
The practical answer
- Short answer
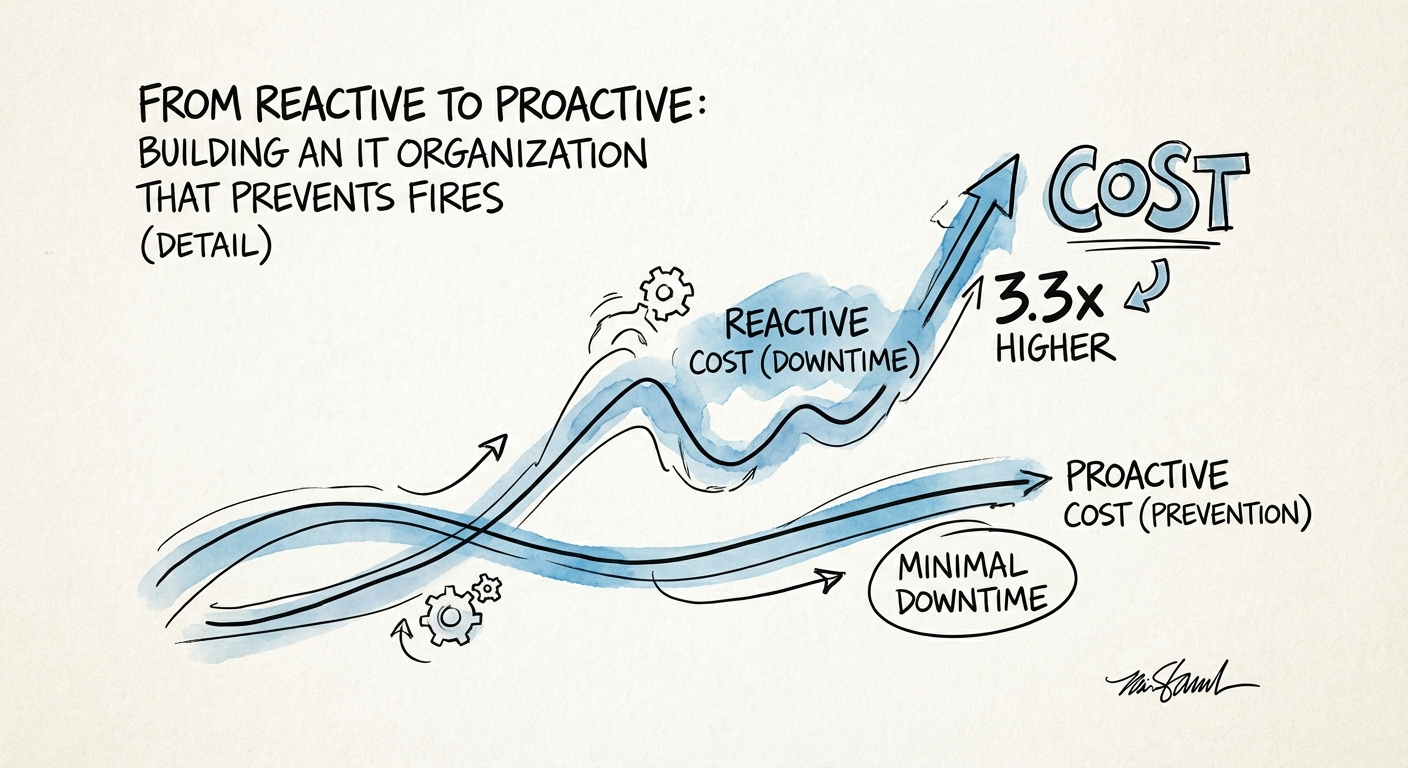
- Reactive IT organizations suffer 3.3x more downtime and bleed $1.4M per hour in outages. Here is the operational maturity roadmap for enterprise CIOs stuck in firefighting mode.
- Best fit
- Industry: Enterprise Tech. Function: IT Operations
- Operating path
- Process Documentation → Operational Excellence → Transaction Execution Services
- Key metric
- $1.4M Avg. Hourly Cost of Downtime (Large Ent.)
The High Cost of the "Hero" CIO
You know the drill. It’s 2 PM on a Tuesday, and your lead engineer is once again saving the day. A critical database cluster failed, threatening to take down the customer portal. The engineer, who holds the entire architecture in his head, ssh’s in, restarts a few services in a specific order known only to him, and the green lights return. The team cheers. You breathe a sigh of relief.
But you shouldn’t be cheering. You should be terrified.
This scenario isn't a sign of a high-performing team; it is the hallmark of a Level 1 maturity organization—chaotic, ad-hoc, and dependent on individual heroics. In this environment, "process" is a dirty word, and documentation is something everyone promises to do "next quarter." The result? You are not leading an IT organization; you are running a high-stakes fire department.
The Math of Reactive Operations
The cost of this operating model is not abstract. While your heroes are fighting fires, your EBITDA is burning. Recent data from EMA Research indicates that unplanned downtime now costs large enterprises an average of $23,750 per minute. That is approximately $1.4 million per hour. If you are in high-frequency trading or healthcare, that number can easily triple.
But the direct cost of outages is just the tip of the spear. The hidden tax of reactive management is the efficiency drain on your entire engineering organization. Industry analysis confirms that organizations stuck in reactive maintenance cycles experience 3.3x more downtime and 2.8x more lost revenue than their proactive counterparts. Every hour your senior engineers spend troubleshooting preventable issues is an hour stolen from strategic initiatives—the very digital transformation projects you were hired to deliver.
If you feel cornered by missed deadlines and budget overruns, look at your incident logs. How many of those "emergencies" were repeat offenders? How many were caused by "human error" (which accounts for 66-80% of all downtime)? You don't have a talent problem. You have a process void.
You don't have a talent problem. You have a process void. Reactive organizations spend 2-5x more on emergency fixes than proactive organizations spend on preventive maintenance.
The Maturity Gap: Why "Good Enough" is Failing You
To escape the firefighting trap, you must objectively assess where your organization sits on the IT Maturity Model. Most "enterprise CIOs" inherit organizations operating at Level 1 (Initial) or Level 2 (Managed), yet they are tasked with delivering Level 4 (Quantitatively Managed) results.
The 5 Levels of IT Maturity
- Level 1: Initial (The Hero Zone). Processes are unpredictable, poorly controlled, and reactive. Success depends on individual effort. Risk: High key-person dependency.
- Level 2: Managed. Processes are characterized for projects and are often reactive. You have a ticketing system, but no root cause analysis. Risk: Recurring incidents.
- Level 3: Defined (The Target). Processes are characterized for the organization and are proactive. Standard Operating Procedures (SOPs) exist and are followed. Benefit: Predictable outcomes.
- Level 4: Quantitatively Managed. Processes are measured and controlled. You use data to predict failures before they happen. Benefit: Margin expansion.
- Level 5: Optimizing. Focus on continuous process improvement.
The chasm between Level 2 and Level 3 is where most CIOs fail. Crossing it requires moving from tribal knowledge to turnkey systems. It requires an admission that "agile" does not mean "undocumented."
The Documentation Dividend
Data shows that the simple act of documenting and digitizing core processes can lead to a 31% reduction in operational costs. Why? Because documentation standardizes execution. When a junior engineer can resolve a Level 2 incident using a playbook, your senior engineer can focus on architecture. When a deployment process is scripted and documented, the "human error" factor—the leading cause of downtime—plummets.
Consider the technical debt you inherited. It’s not just bad code; it’s undocumented complexity. Reactive organizations spend 2-5x more on emergency fixes than proactive organizations spend on preventive maintenance. That 60% premium you pay for emergency repairs? That’s your budget for innovation, evaporating into thin air.
The 30-Day Escape Plan
You cannot buy your way out of this with a new tool. You must engineer your way out with process. Here is your 30-day roadmap to move from Reactive to Defined.
Days 1-10: The Incident Audit
Stop fixing and start counting. For the next 10 days, categorize every single unplanned task. Was it a code regression? A config drift? A vendor outage? Identify the top 3 sources of "noise." You will likely find that 80% of your fires come from 20% of your systems. This is your target list.
Days 11-20: The Expert Extraction
Pick the one engineer who knows everything and remove them from the on-call rotation for a week. Their only job is to write down what they know. Use a governance framework to enforce this. They must produce a "Runbook" for the top 3 incident types identified in your audit. If it’s not written down, it doesn’t exist.
Days 21-30: The "Read-Only" Test
Test the documentation. Hand the new Runbook to a junior engineer and have them resolve a simulated incident without asking questions. If they fail, the documentation is bugged. Fix the doc, not the engineer. This is how you build a standardized delivery model that survives staff turnover.
The Outcome
Proactive IT isn't a luxury; it's a mathematical necessity for survival in the enterprise. By shifting from heroics to systems, you don't just sleep better at night. You recover the 30% of your budget currently lost to inefficiency. You stop being the "Department of No" and start being the "Department of Scale."
The fire department is a noble profession, but it has no place in your data center. Hang up the helmet and start building the fire code.







