
The practical answer
- Short answer
- In B2B SaaS, your on-call rotation is a SOC 2 control and a retention bet. A diagnostic for CEOs to fix incident response before the hero engineer quits.
- Best fit
- Industry: B2B SaaS. Function: Engineering Leadership
- Operating path
- Compliance & Security → Turnaround & Restructuring → Turnaround & Restructuring Services
- Key metric
- $300,000 Cost per hour of downtime for mid-market firms
The auditor asked one question your hero engineer couldn't survive
Picture the SOC 2 readiness call. The assessor points at control CC7.3 and asks, plainly: "If your primary on-call responder is unreachable, who executes the incident response procedure, and where is it documented?" In a lot of Series B and C SaaS companies, the honest answer is a name. One name. The person who wrote the platform, carries the pager by default, and is the only human alive who knows why the payments queue jams at 2 AM.
That answer is the whole problem. You think of on-call as an operational tax — the price of keeping the lights on. In a B2B SaaS business, it is something sharper: it is a compliance control with a heartbeat, and the heartbeat is exhausted. When that engineer burns out and leaves — and in high-stress environments 23 to 25% of engineers do, annually — you don't just lose code. You lose your documented Incident Response capability mid-audit window, you breach the Availability SLAs in your enterprise contracts, and you stare down downtime that costs mid-market firms roughly $300,000 per hour.
And the labor market stopped subsidizing you. The era of engineers quietly eating death marches is over — 66% of employees reported burnout in 2025, an all-time high. Here is the part that should keep a SaaS CEO up at night more than the pager does: a sleep-deprived responder is a worse security responder. The 3 AM brain that misses an anomaly during a real intrusion isn't a culture issue. It's the gap between "we contained it" and "we disclosed it to customers." In a compliance-driven SaaS business, that distinction is the whole company.
Heroics is not a strategy. It is a single point of failure with a pulse. If your uptime depends on one person answering the phone at 3 AM, you don't have a business; you have a hostage situation where you're the hostage.
Run the scorecard: is your on-call a control or a liability?
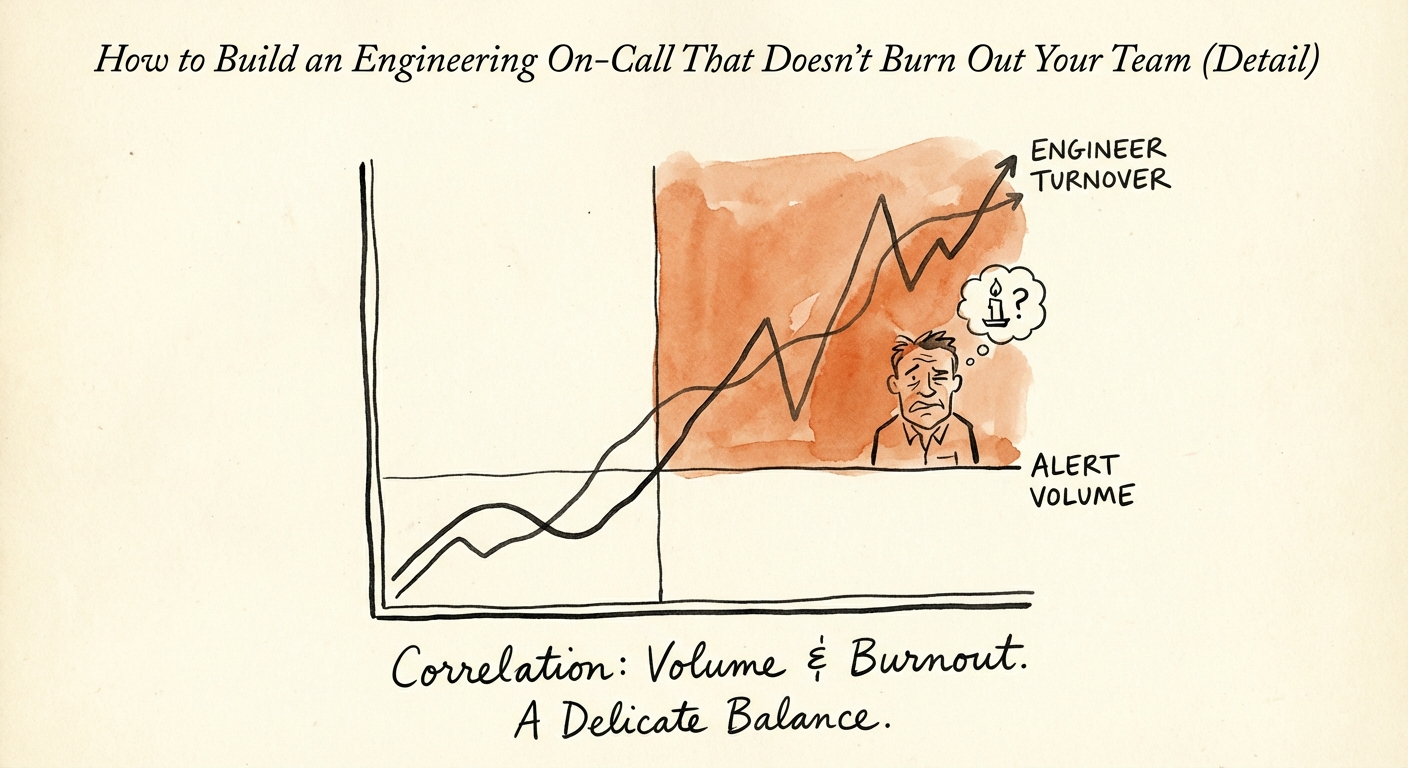
You can't fix what you won't measure, so measure the toil. In SRE language, toil is the repetitive manual work that scales linearly with your service — and for SaaS, that's the leading indicator of margin collapse. If revenue doubles and your incident volume doubles with it, you don't have a product, you have a treadmill with a paywall. Industry data now puts operational toil at 30% of engineering time in 2025. A third of your build capacity, gone to firefighting, while payroll stays flat and the roadmap quietly slips a quarter.
Before you spend a dollar on tooling, answer three questions honestly. They are the difference between an on-call rotation that satisfies an auditor and one that's lying to them.
- What's your alert signal-to-noise ratio? If more than half your pages require no human action, you've trained your team to swipe alerts away reflexively. That reflex doesn't switch off when the alert is a real intrusion. Alert fatigue isn't a comfort problem — it's how breaches get ignored for six hours.
- Who handles the database rollback tonight if your lead SRE is on a plane? If a junior engineer can't, your SOC 2 roadmap is fiction. A control that depends on one specific person being awake and reachable is not a control. It's a wish.
- Are you actually paying for availability? "It's part of the salary" is a 2019 answer. Top-quartile SaaS firms now use direct stipends or, better, mandatory time-in-lieu — because uncompensated 3 AM expectations are how you fund your competitor's hiring pipeline.
The math is brutal and worth saying out loud to your board. Replacing a senior engineer runs 100 to 150% of annual salary once you count recruiting, ramp, and lost velocity. A $150K engineer who quits over a broken pager rotation actually costs you north of $300K. Spend $20K fixing your alerting and you're looking at a 15x return — and you're doing it in the one budget line that also happens to be an audit control.
The 90-day fix: four moves only the CEO can authorize
Engineers can't fix this alone, because the fixes require deleting things and saying no — and that needs executive air cover. "Work smarter" is not a mandate. These four are.
1. The "Delete 30%" mandate
Pull every alert that fired in the last 90 days. If it didn't trigger a specific human action, delete it. If the action could be scripted, automate it. Be ruthless — culling the noise is the only way to restore the signal your team needs to catch the page that actually matters. In a SaaS shop, this single sweep usually reclaims days of attention per engineer per month.
2. Kill the solo rotation with a shadow model
No junior engineer goes on-call alone. Run primary/secondary: an experienced engineer backs the primary every shift. This does two jobs at once — it gives your SOC 2 audit a genuine, demonstrable redundancy for CC7.3, and it transfers the tribal knowledge that currently lives in one person's head. You're training your way out of the key-person dependency every shift.
3. Codify time-in-lieu
If an engineer is paged at 3 AM, they are not at standup at 9. Write it down as policy, not a favor. Interrupted sleep has a real physiological cost, and pretending otherwise is how you convert your best responder into a resignation letter. The next morning off isn't lost productivity — it's the cheapest retention insurance you'll ever buy.
4. Treat runbooks as a board deliverable
Every alert links to a step-by-step runbook, or it shouldn't page anyone. Bring those runbooks to your next board meeting the way you'd bring ARR. If a competent engineer can't execute incident response from documentation alone, your operational resilience is a rumor — and in diligence, that's exactly what a buyer's tech team will find.
The bottom line: in B2B SaaS, your uptime is only as durable as your responders are rested, and your compliance posture is only as real as your documentation. Build a system that lets your best engineers sleep. They'll build the platform that lets you scale — and pass the audit.







