
If you are a CIO or VP of Engineering, you likely dread the post-mortem meeting. It usually goes one of two ways. In Scenario A, it is a polite, sanitized boardroom affair where everyone agrees ‘communication could have been better’ and promises to ‘try harder’ next time. No real lessons are learned, and the same bug hits production three months later. In Scenario B, it is a witch hunt. The finger-pointing begins before the slides are even up, engineering blames product for scope creep, and product blames engineering for technical debt.
Neither scenario protects your capital. According to McKinsey, only 0.5% of IT projects deliver 100% of their intended benefits on time and on budget. That means 199 out of 200 initiatives are leaking value. When you are managing a $50M digital transformation portfolio, that leakage isn't just an annoyance—it is a career risk.
The problem isn’t that teams aren’t smart; it’s that their feedback loops are broken. Most organizations treat the post-mortem (or retrospective) as a funeral for the project—a way to bury the dead and move on. Effective operators treat it as a biopsy: a diagnostic procedure to identify the systemic pathogen and inoculate the organization against it. If you aren't getting actionable structural changes from every failure, you are paying the tuition without getting the degree.
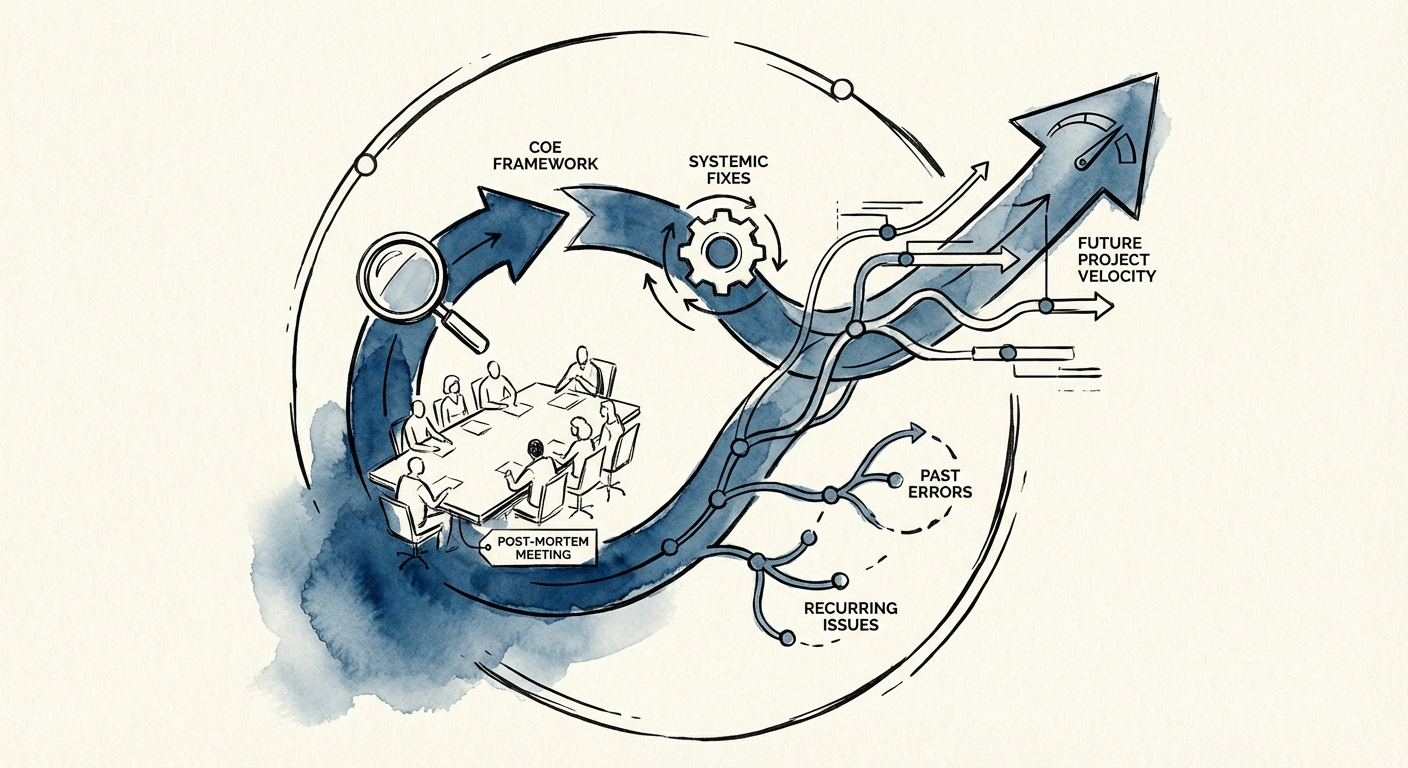
There is a dangerous misconception in the enterprise that ‘blameless’ post-mortems are about being nice. They are not. A true blameless culture, as defined by Google’s Site Reliability Engineering (SRE) standards, is ruthlessly rigorous. It removes the fear of punishment solely to extract the unvarnished truth. If an engineer hides a mistake to save their job, you lose the data point needed to prevent a $2M outage next year.
Stop accepting PowerPoint slides for retrospectives. Slides encourage vague bullet points. Instead, adopt the Amazon-style Correction of Error (COE) document. This is a 2-6 page narrative that must answer five specific questions with zero fluff:
We successfully deployed this framework to assist a stalled fintech client. Their delivery failures turned into retention wins once they showed enterprise customers they had identified the root cause. When a client sees you fixing the machine that builds the product, rather than just firing the operator, trust is restored.
Research from DORA (DevOps Research and Assessment) highlights that high-performing teams measure Rework Rate—the percentage of work that is fixing mistakes versus creating new value. In low-performing IT organizations, this can be as high as 40%. A rigorous post-mortem process should see your Rework Rate drop quarter-over-quarter. If it doesn't, your governance is theater.
If your current project portfolio is bleeding, you don't have time for a six-month cultural transformation. You need a triage protocol. Here is how to operationalize high-value post-mortems immediately.
Make it a policy: The same class of error is not allowed to happen twice. The first time is a learning opportunity; the second time is a leadership failure. If a deployment fails due to a missing config file, the ‘fix’ isn't to remind developers to check configs—it is to automate the config check in the CI/CD pipeline. No automation, no closure.
Look at your current stalled initiatives. Applying a Project Reset Framework often requires killing a zombie project to save the budget. Use a post-mortem on the stalled project (even before it finishes) to determine if the original assumptions still hold true. PMI data suggests 11.4% of all investment is wasted due to poor project performance—recover that capital by shutting down bad bets early.
The cost of tribal knowledge is immense. Ensure every COE is searchable in a central repository. Before any new project over $250k is approved, the lead architect must certify they have reviewed relevant COEs from the past 24 months. This simple governance gate prevents history from repeating itself.
A post-mortem isn't an apology tour. It is an engineering exercise designed to increase your asset value. When you strip away the blame and focus on the mechanics of the failure, you turn an expensive mistake into a permanent competitive advantage. That is how you stop managing chaos and start engineering success.
