
The practical answer
- Short answer
- Why standard 90-day engineering onboarding fails in turnaround environments. Learn how technical debt destroys ramp times and how to implement a 120-day remediation-first playbook.
- Best fit
- Industry: B2B SaaS & Tech. Function: Engineering Leadership
- Operating path
- Technical Debt → Turnaround & Restructuring → Transaction Advisory Services
- Key metric
- 120 days Recommended remediation-first ramp for engineering hires in distressed software environments.
Engineering hires in a turnaround environment often consume significant fully loaded cost and peer time before they can ship safely. The standard enterprise onboarding playbook assumes a clean codebase, documented services, and a functioning CI/CD pipeline. Distressed software assets usually have the opposite: undocumented legacy code, fragile database schemas, and a few senior engineers carrying too much institutional knowledge.
The Reality of the Turnaround Ramp
In a PE-backed SaaS rescue, we initially treated slow ramp time as a hiring problem. The real constraint was the operating environment. New engineers were spending most of their early capacity reverse-engineering undocumented decisions before they could make safe changes. That is not a talent issue; it is onboarding debt.
Software engineering research from Gartner, McKinsey, Forrester, MIT Sloan, and Bain all points in the same direction: engineering productivity depends on environment, documentation, tooling, and management systems, not just individual skill. If you want the hiring plan to protect the EBITDA bridge, recalibrate the financial model around the actual constraints of the codebase. Start by calculating your true exposure using our framework for fully loaded recruiting costs and ramp time.
In a turnaround, a new engineer's first job is not to build the future; it is to stabilize the past. You are trading a short-term illusion of feature velocity for long-term platform stability and talent retention.
Technical Debt as an Onboarding Tax
The core reason traditional onboarding fails in a turnaround is that you are not just teaching a new hire your product roadmap. You are asking them to reconstruct years of undocumented technical choices. When a target has been starved of capital or managed for short-term delivery, engineering teams often accumulate shortcuts that make simple changes unexpectedly risky.
We see this velocity tax in diligence and post-close integration. A newly installed CEO promises a major product release within six months, hires senior developers, and assumes output will rise linearly. Instead, productivity stalls because the legacy team is explaining workarounds, the new team is afraid to break production, and the product roadmap is competing with stabilization work.
To fix this, quantify the debt before you assign the headcount. Operating partners should treat technical debt as a measurable drag on EBITDA, not a vague engineering complaint. A focused code and architecture review in the first 30 days creates the baseline. You can use our methodology outlined in technical debt quantification for pre-acquisition pricing adjustments to convert that drag into a board-level operating plan.
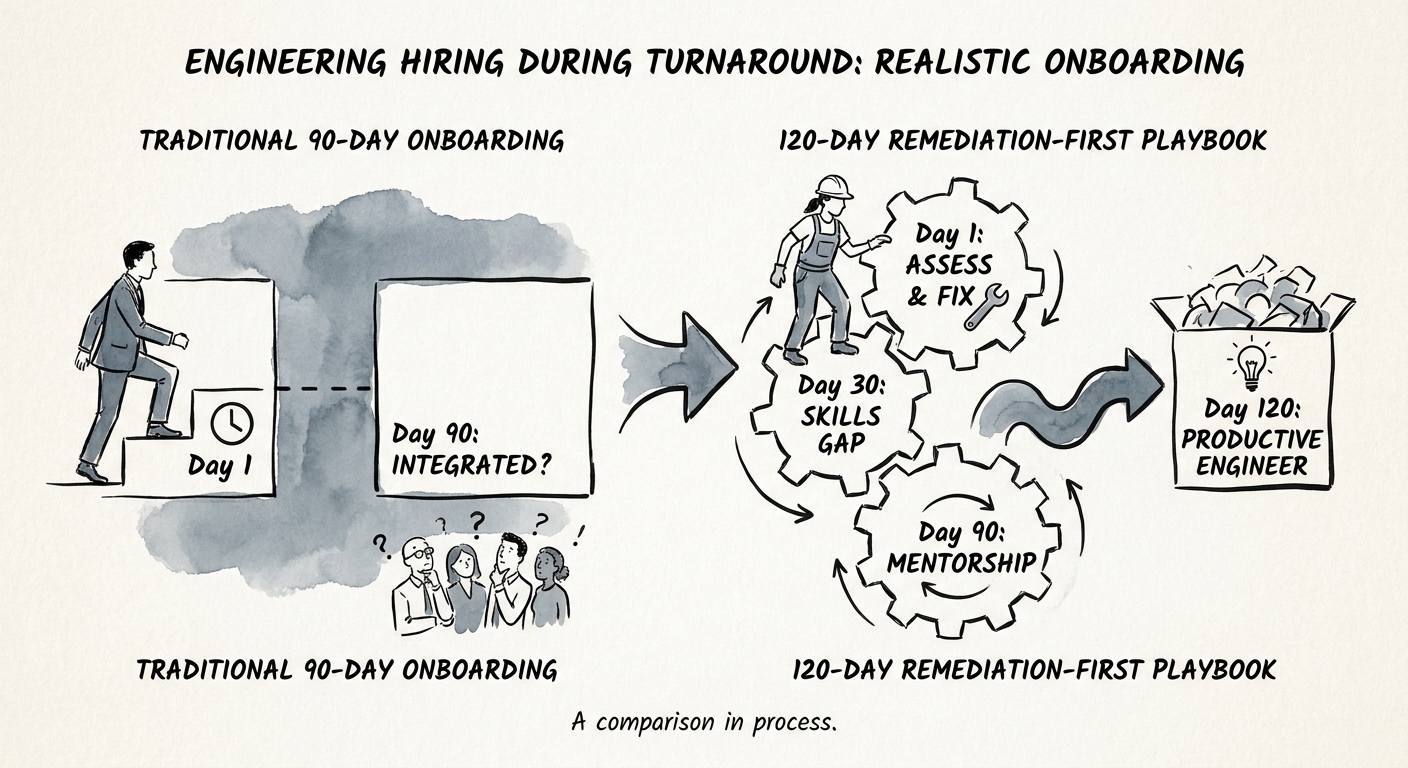
The 120-Day Remediation-First Playbook
To break the cycle of churn and stalled velocity, replace the default 90-day feature ramp with a 120-day remediation-first onboarding playbook. In a turnaround, a new engineer's first job is not to build the future at full speed; it is to understand and stabilize the system they inherited. During the first 30 days, assign new hires to automated tests, observability gaps, and documented walkthroughs of legacy modules. By Day 60, shift them into specific, low-risk technical debt tickets such as deprecated libraries, dead code paths, and slow database queries. They learn the system by improving it.
This structured approach turns onboarding from a forensic investigation into a systematic paydown of technical debt. It also reduces dependency on legacy experts because new hires are adding stabilization value instead of relying on endless ad hoc explanations. You are trading a short-term illusion of feature velocity for long-term platform stability and talent retention.
By Days 90 through 120, these engineers have built a practical model of the system architecture through direct remediation. Only then should they take on net-new feature development. We implemented this phasing at a distressed HCM platform, which you can read about in the 120-day technical debt paydown case study. Standardize the ramp, pay down the debt, and build a foundation that supports your exit multiple.







