
The practical answer
- Short answer
- Big-bang rewrites carry a 20% outright failure rate. Here is the cost-benchmark math and the Strangler Fig sequencing that protects EBITDA and your exit.
- Best fit
- Industry: B2B SaaS & Technology. Function: Engineering & IT Operations
- Operating path
- Technical Debt → Turnaround & Restructuring → Transaction Advisory Services
- Key metric
- 79% Failure rate of mismanaged legacy application modernization projects.
The slide that kills the deal
Picture the technical diligence room. The acquirer's diligence team asks one question: "Show us the architecture you actually run in production today." The CTO pulls up two diagrams. One is the live monolith. The other is "V2" — the rebuild that has consumed nine months of engineering and frozen the product roadmap. V2 is at 60%. It runs nothing real. That second slide does not signal ambition to a buyer. It signals an unfunded liability and a divided engineering culture, and it gets priced straight into the offer.
This is the trap the big-bang rewrite sets for B2B SaaS companies heading toward an exit. The instinct is understandable. Engineers genuinely suffer inside aging codebases — Stripe and McKinsey's Developer Coefficient report found developers burn roughly a third of their time fighting legacy performance and maintenance friction rather than building. And the macro liability is staggering: the Consortium for Information & Software Quality puts accumulated U.S. software technical debt at $1.52 trillion. So when the team asks to "do it right this time" with a clean greenfield platform, saying yes feels like leadership.
It is the opposite. The moment you freeze the roadmap to fund a multi-quarter rewrite, you stop shipping things sales can sell. Competitors keep releasing. Renewal conversations get harder because the demo looks the same as last year. And the rewrite's launch date does what every rewrite launch date does — it stays six months out, permanently. The damage is not just the engineering spend. It is the revenue you did not earn while the platform was held hostage. For a deeper read on the fork itself, the fix-versus-replace decision framework is worth a full pass before you commit a dollar.
A rewrite that cannot ship a working slice to production inside one quarter is not a project. It is a hole you fund for eighteen months and then write down in diligence.
The benchmark that ends the argument
You do not have to win the rewrite debate on opinion. The data does it. The Standish Group's CHAOS database, drawn from more than 50,000 IT projects, splits modernization into two outcomes that are not close. Projects run as a wholesale replacement — "start from scratch" — land a successful outcome only 26% of the time and fail outright 20% of the time. Projects run as continuous, incremental flow succeed 71% of the time and fail just 1% of the time. One in five big-bang attempts dies completely. One in a hundred incremental efforts does.
The cost benchmarks follow the same shape, and they are the part that matters when EBITDA is on the line. A big-bang rewrite is a capital sink with no return until cutover — you pay in full for months and collect nothing until the risky switch-over weekend that, per the failure rate, has a real chance of never arriving cleanly. Incremental modernization inverts that cash profile. You wrap the legacy system in an interface boundary, then pull out one capability at a time — the Strangler Fig pattern — routing live traffic to a new service while the untouched legacy code keeps serving everything else. Each slice returns value the quarter it ships.
Sequencing is where the money is, and it is specific to your codebase, not generic. Extract by margin bleed, not by elegance. Say your legacy billing module forces a finance person to hand-reconcile failed charges every month — that subsystem comes out first, because killing the manual reconciliation drops directly to operating margin and partially funds the next slice. The crusty-but-reliable reporting engine that nobody complains about waits until year three. That ordering turns modernization from a line item the board dreads into a self-funding program. To put board-ready numbers on which subsystem bleeds what, run it through a technical debt quantification framework rather than arguing it in adjectives.
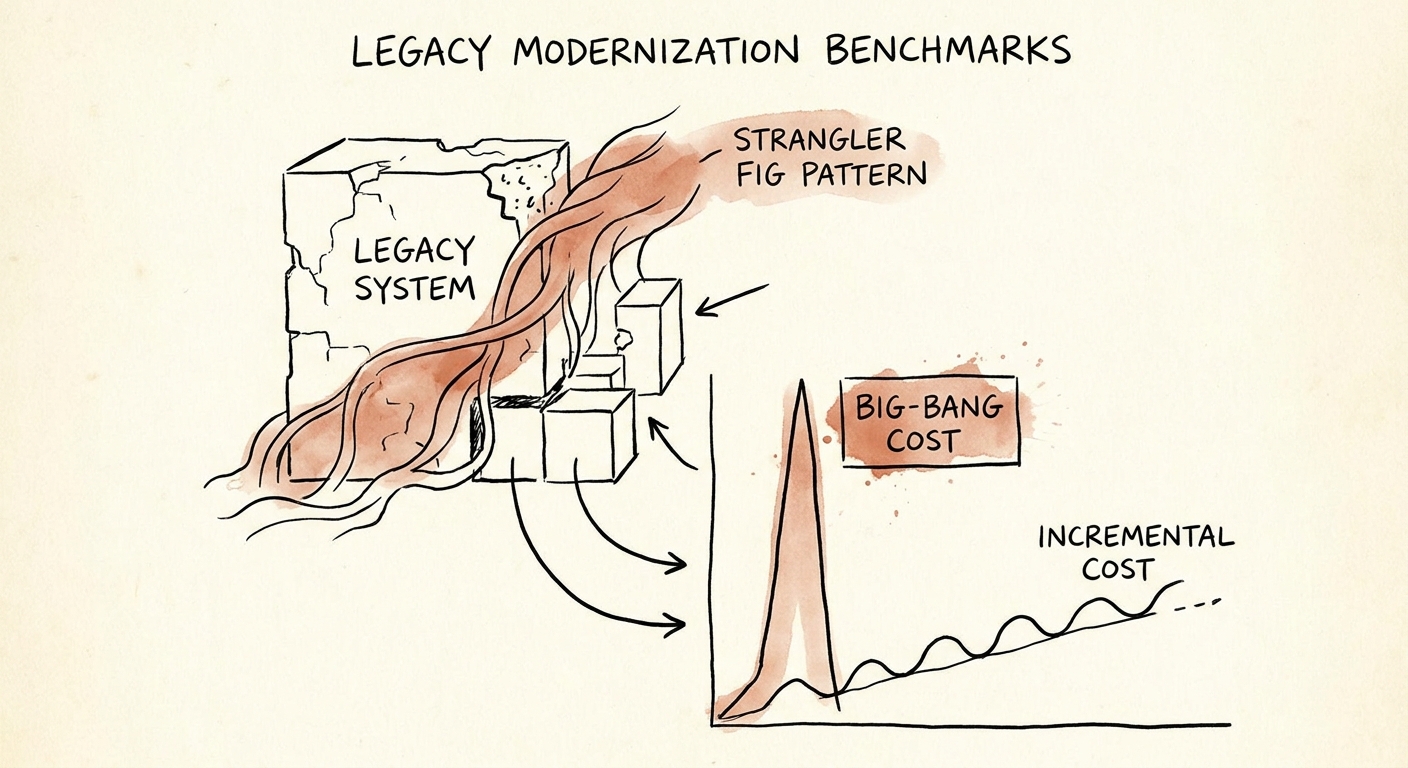
Running it on a 90-day clock
Incremental modernization is a sequencing discipline, not a software pattern. The forcing function is the quarter. If a component cannot be decoupled, rebuilt, and deployed to production alongside the legacy system inside 90 days, the slice is too big — break it down until it fits. This single rule kills the 18-month charter that hides failure until it is too late to course-correct. You either have a working service in production this quarter or you have evidence the scope was wrong, and both are useful.
Three operating rules make it hold. First, put your strongest engineers on the routing layer that decides whether a request hits the old monolith or the new service — done right, customers never notice a migration is underway, which is the entire point of protecting retention while you re-plumb. Second, cap modernization at roughly 30% of engineering capacity and reserve the rest for revenue features; the failure mode of incremental work is not technical, it is letting remediation crowd out everything sales can sell. A quick-win remediation roadmap keeps that balance honest quarter to quarter. Third — the rule most teams skip — once a new service is live, delete the legacy equivalent. Migrations stall into permanent dual-system limbo when the old path is never decommissioned, and now you are paying to run both and burning out the people who maintain them.
I have run this across mid-market software companies, and the human pattern repeats every time: engineers want the clean satisfaction of greenfield, and the business needs the cash-flow stability of evolving what already earns. When your technical leaders ask for "just a few more months" on the rewrite, that is the moment to hold the line. Make modernization ship on the same quarterly cadence and the same dollar accountability you demand from your sales org — and the next time a buyer asks to see what you run in production, the answer is a working system, not a 60% promise.







