
The practical answer
- Short answer
- A $30M SaaS company had an elite 45-min MTTR and 12% runbook coverage. Here is why the second number cost them their multiple in diligence.
- Best fit
- Industry: B2B SaaS. Function: Technical Operations & DevOps
- Operating path
- Process Documentation → Operational Excellence → Transaction Execution Services
- Key metric
- 15 Minutes burned on 'coordination tax' without documented runbooks
The dashboard said "elite." The diligence said "key-person risk."
Picture the data room for a $30M ARR B2B SaaS company going to market. The engineering page leads with a 45-minute mean time to resolution on P1 incidents. It looks fantastic — faster than most peers twice their size. Then the technical reviewer asks one question that the dashboard cannot answer: who actually fixes these? Pull the on-call logs and the answer falls out immediately. Roughly four out of five high-severity incidents route through the same person — the technical co-founder — because he is the only human alive who knows how the primary database cluster behaves under load.
That 45-minute MTTR is not the output of a mature process. It is the output of one exhausted person working 80-hour weeks to keep the lights on. The instant he takes a vacation, or a sabbatical, or a competing offer, the number doubles. Acquirers know this, which is why the metric they actually weight in technical due diligence is not MTTR at all — it is runbook coverage: the percentage of P1 and P2 incident types mapped to a predefined, executable workflow that a second-tier engineer can run at 3 a.m. without paging the founder.
In that company, runbook coverage sat at 12%. So the speed was real, but the resilience was a fiction. This is the exact pattern that surfaces as a due diligence red flag and gets re-priced into the offer: buyers do not pay a premium multiple for heroics they can't transfer onto their own bench. They pay for systems that survive the architect leaving. Below 80% coverage, you are not selling a scalable platform — you are selling a dependency on one person's memory.
A 45-minute MTTR held up by one exhausted co-founder is not a fast team. It is a single point of failure with a good dashboard, and every diligence partner knows how to find it.
The 15-minute tax you can't see on the P&L
Here is what 12% coverage actually feels like when the pager goes off at a company this size. The alert fires. The responding engineer doesn't open a runbook — there isn't one — so the first move is reconstruction. They toggle between the PagerDuty alert, three Slack threads, a Jira ticket, and a Confluence page last edited eleven months ago, just to establish what "normal" looked like before the spike. Only after that scramble does anyone touch the root cause. incident.io's research on automated runbooks puts that context-reassembly step at a minimum of 15 minutes per incident — pure overhead, before a single line of the actual fix gets written.
Now attach a dollar figure to that quarter hour. The EMA/BigPanda outage-cost benchmark pegs the blended cost of enterprise downtime at roughly $14,056 per minute. Fifteen minutes of fumbling, before remediation even begins, is over $210,000 in lost revenue, SLA credits, and trust erosion per major incident. That cost never appears as a line item. It hides inside churn, inside support escalations, inside the co-founder's calendar. It is the most expensive thing in the operation that no spreadsheet tracks.
Where the math flips
Coverage changes the unit economics because it moves work off the most expensive, least scalable resource in the building. PagerDuty's platform benchmarks show that automating routine remediation — safely cycling a specific service, flushing an overloaded cache — cuts MTTR for those tasks by an estimated 40%. The alert triggers the diagnostic, assigns the incident commander, and surfaces a one-click action inside the channel the team already lives in, instead of an adrenaline-soaked engineer typing a destructive CLI command from memory. Gartner's MTTR analysis reports the same magnitude: automated context retrieval plus human-in-the-loop remediation consistently trims resolution time by north of 40%. The difference between a blip and a board-level incident comes down to whether the person holding the pager has a runbook in front of them — or has to go find the founder.
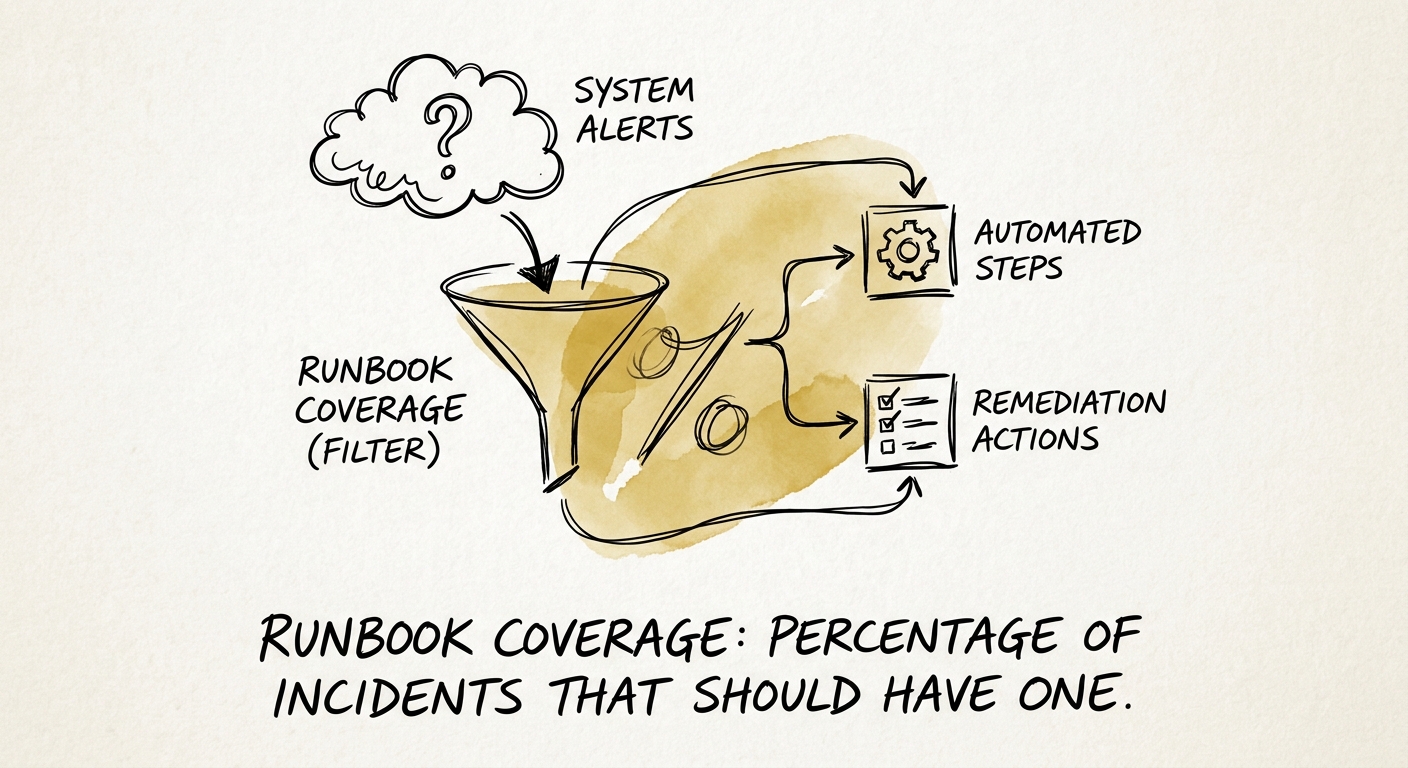
How to move from 12% to 80% in one quarter
You do not close a coverage gap by trying to document the entire system at once — that project dies in week three. You close it by frequency. Open your incident platform and rank alert types by how often they actually fire. The first finding at most scaling SaaS companies is uncomfortable: the top ten alert types cause the overwhelming majority of pages, and almost none of them have a runbook. That is your 90-day list. Write executable workflows for those ten, and coverage on your real-world incident volume jumps from single digits toward 80% without documenting a single rare edge case.
While you're in there, measure the bleed. If engineers are spending more than a fifth of sprint capacity on undocumented operational toil, that capacity is being converted directly into a thinner EBITDA margin — you're paying senior salaries to re-derive the same fix every week. McKinsey's research on IT resilience found that organizations that systematically modernize their architecture and adopt documented incident practices cut high-severity resolution time by nearly 60% within six months. To make it stick, the coverage has to stop being a cleanup sprint and become a default: no service ships without a remediation workflow in its Definition of Done.
One caution that separates real coverage from theater. A runbook that hasn't been executed or reviewed in 90 days is a liability, not an asset, because incident response plans fail the moment the infrastructure drifts away from what the document describes. Stress-test them on a schedule. Done right, this stops being a documentation chore and becomes the cleanest enterprise-value story you can tell a buyer: an audited 80%+ coverage figure that proves the company runs without you — which is, in the end, the only thing they're buying.







