The readiness signal lives in your ticket taxonomy, not a vendor demo
Open your PSA and pull last quarter's closed tickets. Sort by category. If a third of them are tagged "Other," "General," or whatever your dispatchers click when they're slammed, you have just found the reason an AI pilot will stall before it helps a single technician. A 150-person MSP throws off enough volume that the patterns are real, but volume is not the same as structure. The model you bolt onto a service desk learns from whatever taxonomy your techs actually used at 4:55 on a Friday, and a messy category field becomes a confidently wrong routing suggestion.
That gap between having a tool and trusting it is the recurring finding in the San Francisco Fed's small-business AI research: the constraint is rarely access to the technology, it's implementation capacity and trust. For an MSP that surfaces in a specific way. Technicians will quietly try a chatbot to draft a knowledge-base article or summarize a noisy alert long before service leadership has decided which client data is allowed near a model. The readiness assessment exists to get ahead of that, ranking where AI can take routing, reporting, knowledge-search, and escalation load off the desk without inventing a new category of risk you now have to manage across every client tenant.
Cross-client data is the line a generic readiness checklist misses
An internal IT team has one set of data and one client: itself. An MSP has thirty, or eighty, each with its own contracted boundaries, and that single fact reshapes the whole assessment. CISA's data-security guidance reads, for you, as a set of blunt questions with consequences: can a model trained or prompted on Client A's tickets surface a fragment of A's environment while a tech is working B's escalation? Which RMM and PSA records are authoritative versus stale-and-still-in-the-database? What gets logged, and would that log itself violate a client agreement? A drafting assistant that scopes to a single tenant is a Tuesday improvement. One that quietly reaches across tenants is a breach notification.
Use NIST's AI Risk Management Framework to keep the rollout honest rather than as paperwork: map the intended use, measure whether outputs actually improve the work, manage the failure modes, govern who owns the decision. The practical move is to split the work by blast radius. Drafting a first-pass KB article or a shift-handoff summary is low-risk and reversible. Recommending an incident severity, touching an SLA clock, or making a commercial promise in a client-facing note is not — those stay human until the evidence says otherwise. The pilot has to be small enough that a service manager can read the outputs without that review becoming its own backlogged queue.
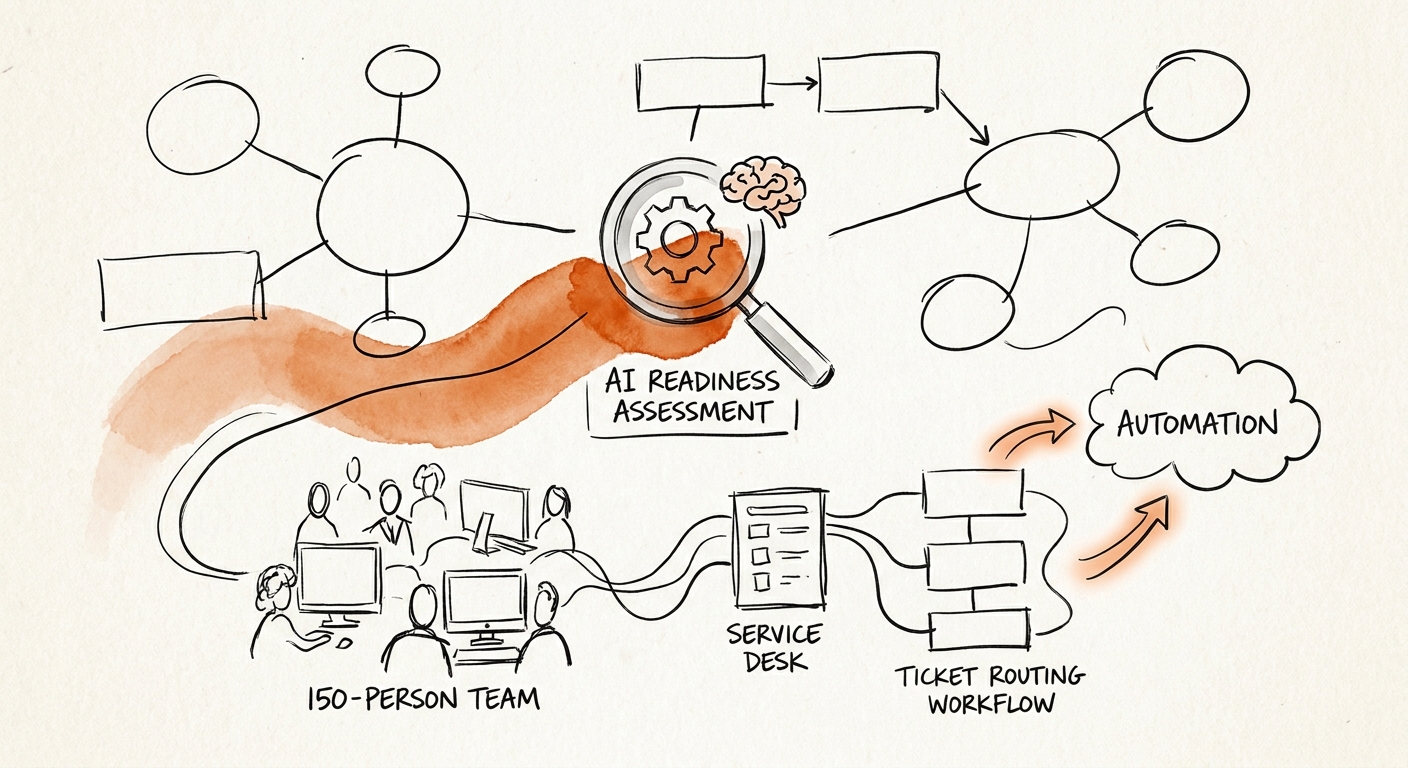
Pick the one workflow your weakest reviewer can still check
Score each candidate workflow on the things that actually predict whether it survives contact with the desk: source reliability, permission clarity, how often exceptions need senior judgment, the review effort it creates, customer-risk exposure, and the one service metric it should move. Run it honestly and the rankings invert your intuition. A ticket-summary assistant scores high on data availability and low on customer-risk tolerance, because a wrong summary on a security incident is expensive. An internal reporting-note generator looks boring and scores beautifully on governance fit. Boring usually wins the first round.
At 150 people the binding constraint is almost always review capacity, not model quality. If a service manager can spend an hour a week comparing AI-assisted outputs against what actually happened to those tickets after they left the queue, the firm learns fast and the pilot earns its expansion. If no one owns that hour, the assessment's job is to say so plainly and recommend the unglamorous fix first — clean the category field, document the escalation rules, decide which records are authoritative — before any automation goes near production. Keep the starting dataset narrow: ticket taxonomy, PSA and RMM reliability, escalation rules, client-data boundaries, and that named reviewer. Nothing else until the first team proves the loop.
The output should be something leadership can argue with in a normal ops meeting, not a slide: a ranked backlog of one governance repair, one pilot with a measurable service number attached, and one follow-on candidate parked behind it. From there, an AI opportunity score sharpens the priority and a 90-day implementation plan turns it into dated work. Monday's task is the smallest one: export last quarter's tickets and count the "Other" tag.
