Your readiness lives in the queue, not the roadmap
Picture the Tuesday-morning state of a 100-person managed service provider: a few hundred open tickets, a Tier 1 team triaging "Outlook won't connect" for the ninth time this week, and a senior engineer who is the only person who actually remembers how one anchor client's hybrid Exchange setup is wired. That is where your AI readiness gets decided — not in a strategy deck, and not by which platform a vendor demos. It is decided by whether the work your team repeats every day has clean source material, a measurable baseline, and an owner who can sign off on what the machine produces.
The pull to do the opposite is strong, because the numbers make AI feel inevitable. The Census Bureau's May 2026 review shows adoption is already concentrated in the mid-market, with 32% of firms in the 100-to-249 employee band reporting AI use. For an MSP that statistic is double-edged: your clients read it too, and "are you using AI to handle our tickets faster" is becoming a renewal-conversation question. But buying a broad copilot and telling every pod to "find use cases" is how you end up with a tool that drafts ticket replies your engineers have to rewrite anyway. Readiness is the discipline of knowing which queue, which runbook, which client tier is actually ready — before the contract is signed.
Score each workflow on the four things an MSP can't fake
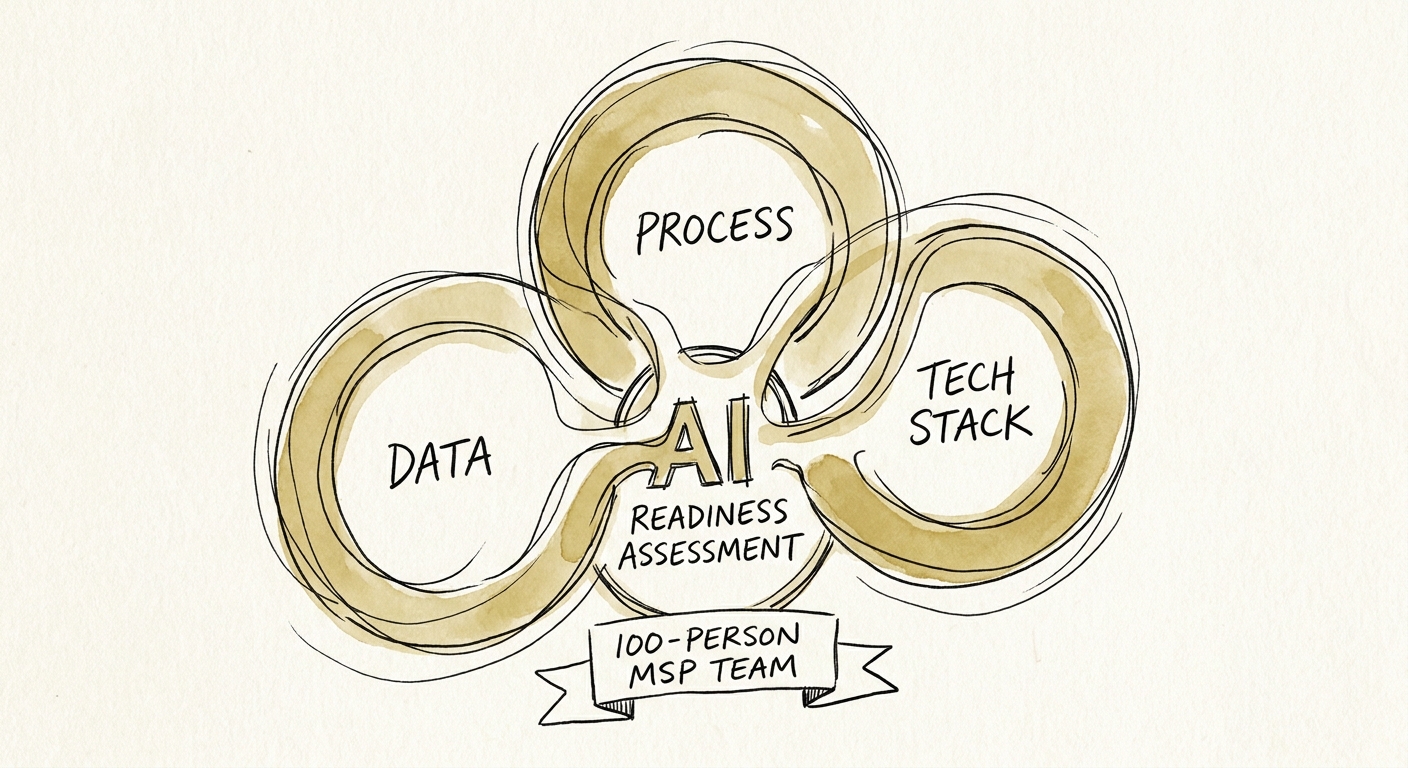
The OECD's work on SME adoption is blunt about why most attempts stall: it depends on data readiness, skills, financing, and management capability — not model access. The firms that turn AI into real operating leverage run it as a management system, not a license purchase. For an MSP, "data readiness" is unusually concrete because you don't own most of the data — your clients do, and you handle it under contract.
So score every candidate workflow on four axes. First, source quality: ticket-deflection suggestions are only as good as your knowledge base, and most MSP KBs are a graveyard of stale articles and "see Greg" notes. Fix the source before you connect a model to it. Second, blast radius: drafting a reply to a low-severity ticket is a different risk class than auto-executing a remediation script across a client's fleet. Use the NIST AI Risk Management Framework to sort assistance (human reads, then sends) from action (the system changes a client's production environment). Third, data boundary: a multi-tenant MSP cannot let one client's documentation, contracts, or network diagrams bleed into a prompt that serves another. CISA's guidance on securing data used to train and operate AI systems is the floor here — per-tenant isolation, logging, and access control are non-negotiable when the SOW says you're a custodian. Fourth, economic value: tie it to a number you already report, like first-touch resolution rate or mean time to resolve. The output of this exercise is a ranked backlog with a named governance owner, not a wishlist of clever prompts.
Pick one queue, instrument it, then earn the right to expand
The reason discipline matters is that the gap between "demo" and "production" is where most of this dies. Deloitte's 2026 State of AI research found only about a quarter of leaders had moved 40% or more of their pilots into production. An MSP feels that gap acutely: a tool that drafts decent ticket responses in a sandbox can still crater your CSAT if it confidently invents a fix for a client environment it doesn't understand. So write down the baselines before the pilot starts — mean time to resolution on the target queue, reopen rate, escalation volume, and the exact approval path for anything that touches a client system. The same San Francisco Fed reading on AI and small businesses underscores that the payoff shows up in operational metrics, not in adoption headcount.
Make Monday concrete: choose one queue — say, password-reset and access-request tickets across your standardized clients, the highest-volume, lowest-blast-radius work you have. Stand up an AI-drafted-response workflow with a human approving every send for the first 30 days, fed only by a KB you've cleaned and scoped to that tenant. Measure resolution time and reopen rate against the baseline, then decide whether to widen the loop. We use a clear pilot-versus-production distinction so teams stop mistaking a good demo for an operating change. When you're ready to turn that first scored queue into a sequenced plan across knowledge systems, automation, and governance, the AI Transformation Blueprint is where it goes next.
