The 11:40pm Ticket That Touches Three Clients
A 250-person MSP is not a bigger 40-person MSP. It's a fundamentally different control problem, because the same dispatcher queue, the same Level 1 bench, and the same after-hours pod are servicing forty or eighty distinct client tenants in a single shift. When you bolt AI onto ticket summarization or knowledge search at that scale, you're not asking "is the model accurate?" You're asking "does the model know which client it's standing in right now?"
Here's the scene that should drive your whole assessment. It's 11:40pm. A Level 1 tech has a P1 from Globex Manufacturing and reaches for an AI-assisted summary to brief the on-call engineer. The model has been trained, fine-tuned, or simply fed examples that include resolution notes from Acme Logistics, who runs a nearly identical firewall config. The summary it produces is fluent, confident, and quietly seeded with Acme's network topology. Nobody catches it, because at 250 people nobody reads every summary. Census reporting on rising business AI use tells you the adoption pressure is real; it does not tell you that an MSP's adoption risk is structurally different from a law firm's or a manufacturer's, because the MSP's "internal data" is dozens of clients' confidential infrastructure sitting in one PSA.
So the readiness assessment for a firm this size starts in an unusual place: not "where could AI save time?" but "where does our work cross a client boundary, and is that boundary enforceable by something other than a tired tech's judgment at midnight?"
Score Each Workflow Where It Crosses a Tenant Line
Lay out the seven places AI most wants to live inside an MSP — ticket triage and summarization, escalation handoffs, knowledge-base search, account/QBR research, RMM alert correlation, client-facing reporting, and renewal-risk flagging — and refuse to score them as a group. Each one crosses the tenant boundary at a different angle and carries a different blast radius. NIST's framework for trustworthy AI gives you the spine: for each workflow, name the intended use, the reliability of the source data, who reviews the output, and what the exception path is when it's wrong.
Then run the harder pass. CISA's guidance on securing the data used to train and operate AI systems is the right lens here precisely because an MSP's training corpus and its retrieval context are other people's protected environments. For every workflow, answer three things in writing: (1) Is tenant separation enforced in the retrieval layer, or only in the prompt? Prompt-level "only use Globex data" is not separation — it's a suggestion. (2) Is there a per-client logging trail showing which records the model touched, so you can answer a client's "what did you feed the AI about us?" without guessing? (3) Has the affected client's contract and security addendum actually been read for AI/subprocessor language, or are you assuming consent?
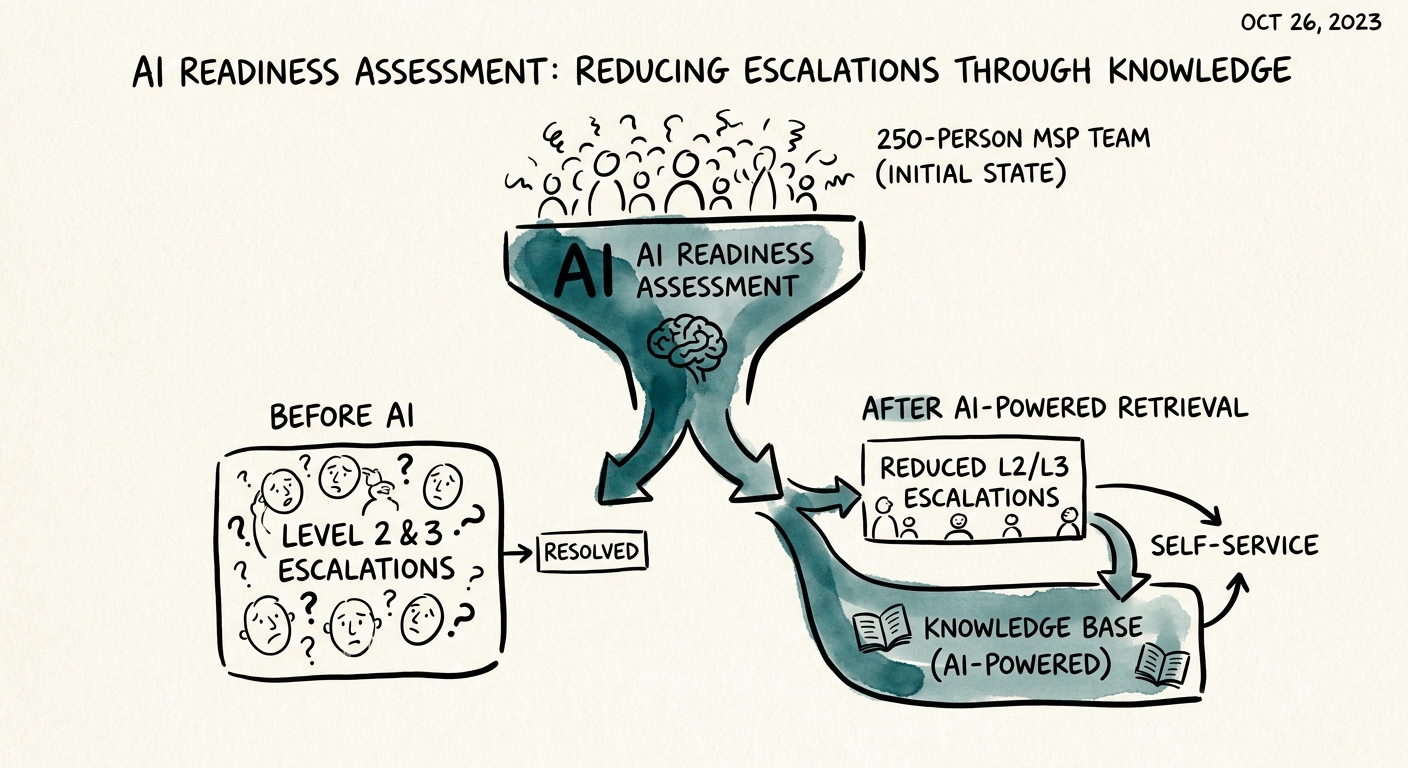
A 250-person MSP almost always finds the readiness gradient runs the same way: internal-only workflows (RMM alert clustering, dispatch routing) are nearly ready, single-tenant client-facing workflows (one client's report) are workable with logging, and any workflow that pools examples across clients is a hard stop until retrieval is tenant-scoped. That gradient, not a tool shortlist, is the deliverable.
Pick the Pilot Your Service Managers Can Actually Police
The right first pilot at this scale is internal, single-tenant, and high-volume enough to measure — RMM alert correlation or first-draft ticket summaries scoped to one named client who has signed off. You want a workflow where a service manager can pull a sample of fifty outputs on a Friday and tell, within an hour, whether the thing is helping or quietly inventing. If a candidate workflow only works when a senior technician's undocumented instinct is in the loop, or when client-data controls are "mostly" enforced, you wait and fix the control first.
Watch the review burden, because it's the silent budget. At 250 people generating AI-assisted output across a 24/7 desk, the volume of stuff that needs human eyes can quietly become a second job for your team leads. The pilot you keep is the one where managers can inspect samples, frontline techs can flag and challenge a bad summary in the moment, your security lead can trace the data flow per tenant, and leadership can see a real number move — mean time to resolution, escalation accuracy, QBR prep hours — before anyone adds the next team.
Run it as a contained loop: one client, one workflow, a defined source set (PSA, RMM, ticketing, with cross-client examples explicitly walled off), and an evidence packet that names the source record, shows the AI draft, captures the tech's edit, and ties it to what happened after the ticket closed. Then decide expansion on the scores you wrote down, not on enthusiasm. If variance across teams hasn't visibly dropped and the tenant-separation question still gets a shrug, you repair ownership, permissions, and source quality before automating anything else. A quick way to frame the first conversation is an AI opportunity score, followed by a scoped implementation sprint on the one workflow that earned it.
