Your PSA Already Knows Where AI Should Go First
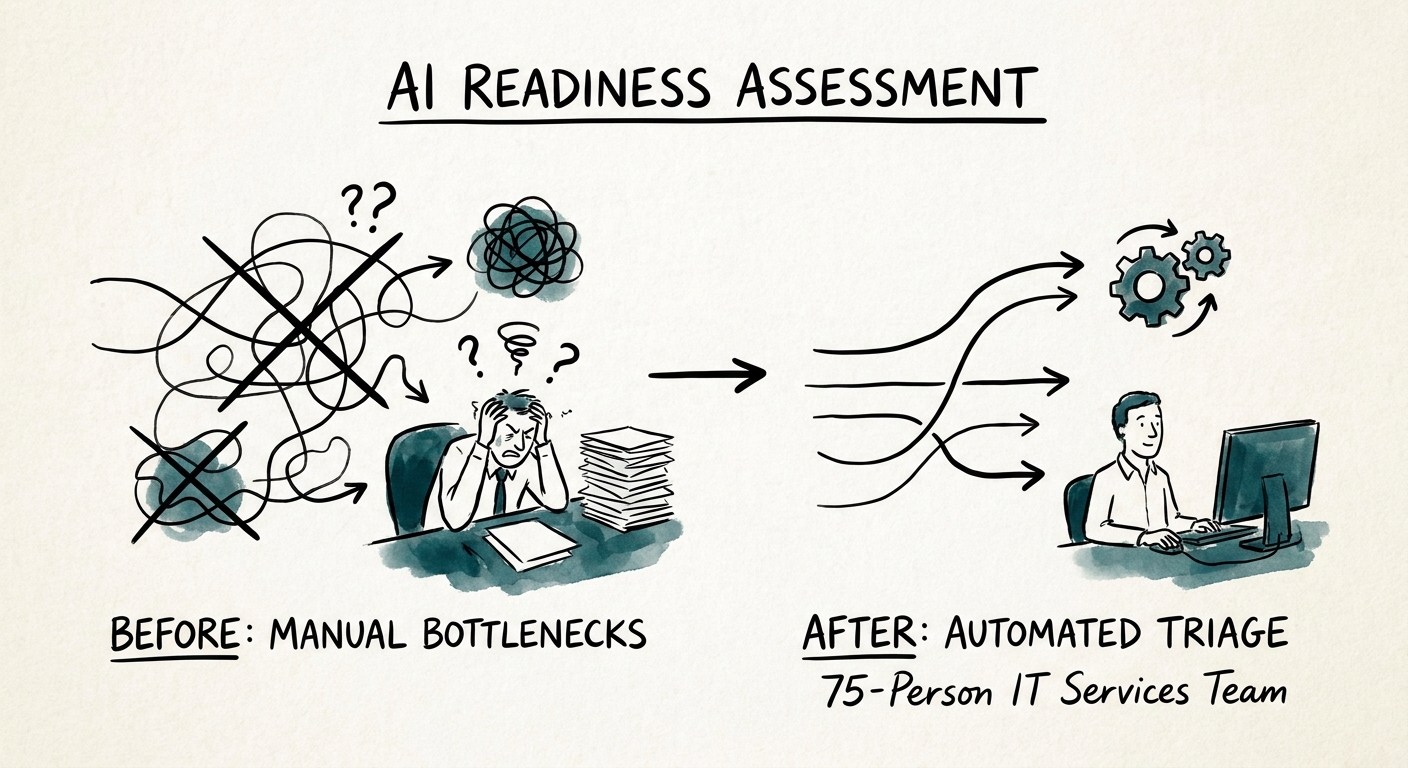
Picture the Tuesday standup at a 75-person managed services firm. The service desk has 1,400 open tickets, three engineers are quietly resolving the same password-reset and disk-space alerts they cleared last week, and a proposal for a 40-seat migration is sitting half-written because the one person who knows the client's environment is on site. That is not a place that needs a chatbot. That is a place that needs to read its own PSA data honestly.
AI readiness at this size is not a question of curiosity or vendor demos. It is a scoring exercise against systems you already run: the PSA, the ticketing queue, RMM alert streams, the proposal library, and whatever passes for a service-desk knowledge base. The RSM middle-market AI survey, the San Francisco Fed's analysis of AI and small businesses, and the OECD report on AI adoption by small and medium-sized enterprises all point the same direction: adoption only pays off when a firm can name a specific workflow, a specific data source behind it, and a person accountable for the output. Adoption rate alone tells you nothing.
So the first readiness question for an MSP is narrow and answerable: can you rank one recurring workflow where the data source is clean, the delivery owner is obvious, and the improvement is measurable in hours or escalations avoided? If you can name it — say, drafting first-response replies for tier-one tickets in a single category — you are ready to score. If every candidate is "the model will figure it out," you are not.
The Trap: One Client's Data Leaking Into Another's Answer
The way a 75-person MSP gets burned is not a bad demo. It is handing every engineer a general assistant pointed at the full ticket history, then discovering the model happily pulled detail from Client A's environment into a summary it generated for Client B. At your scale you carry dozens of client tenants under one roof. Multi-tenancy is your business model and your single largest AI risk at the same time.
Before any model touches a client record, decide what it is allowed to see. The CISA AI Data Security Best Practices are the right lens for the hard call: which PSA records, ticket histories, RMM alerts, client runbooks, proposal drafts, and knowledge articles get exposed to a model, which get scoped per tenant, and which never leave the system at all. Pair that with the NIST AI Risk Management Framework to assign a named reviewer and a measurable risk threshold to each use, instead of trusting a fluent paragraph nobody owns.
Concretely, write a one-page control sheet for each candidate workflow before you build it: which tenant boundary applies, who owns the source system, how fresh the data has to be, what output the model is allowed to produce, who signs off, what service metric it should move, and the stop condition that pulls it offline. A first-response draft that an engineer reviews before sending needs light controls. Anything that writes back to a client's RMM or updates a ticket status automatically needs deterministic checks wrapped around the model — not the model's own confidence.
Output a Backlog Your Service Manager Can Actually Run
The point of the assessment is not a maturity score. It is a ranked list of two or three workflows your service delivery manager can put into a sprint. Deloitte's State of AI in the Enterprise 2026 makes the useful distinction: the firms getting value have stopped counting pilots and started counting production workflows. For an MSP, production value means measured ticket-handling time removed, fewer escalations on a category, or proposal turnaround cut — tied to a real client commitment, not a slide.
Score each candidate on the dimensions that actually predict success here: data-source cleanliness, tenant-data sensitivity, the review burden it puts on your engineers, the service delay it removes, and whether one team can ship it in a single sprint. The most common finding is uncomfortable and worth surfacing on purpose — the workflow everyone is most excited about is usually the one with the messiest knowledge base or no clear tenant boundary. When that shows up, fix the source system first. A model on top of a stale, unsegmented knowledge base just produces wrong answers faster.
Run the manual-work scoring guide to confirm a candidate is worth building, then stage it with the 90-day AI implementation plan: clean the source, prototype on one ticket category, train the reviewing engineers, launch, then decide whether to scale to a second workflow. Pick exactly one ticket, knowledge, or proposal workflow for the first 90 days and hold the firmwide assistant rollout until that one has owners and a number attached. By the next quarterly review you want a backlog item that shipped — not another deck of AI ideas.
