
The Consultant Who Followed the 2024 Playbook on a 2026 Rollout
Picture a 60-person implementation firm that stands up the same ERP integration for client after client. There is a "playbook." There are also four playbooks: the canonical one in the wiki, the version a senior consultant forked for healthcare clients, the PDF a project manager emailed during a crunch, and the de facto playbook that lives in the head of the person who has done forty of these. A new hire searches the wiki, finds a step that was correct eighteen months ago, and runs a migration sequence that a hotfix quietly retired last spring. The client notices before you do.
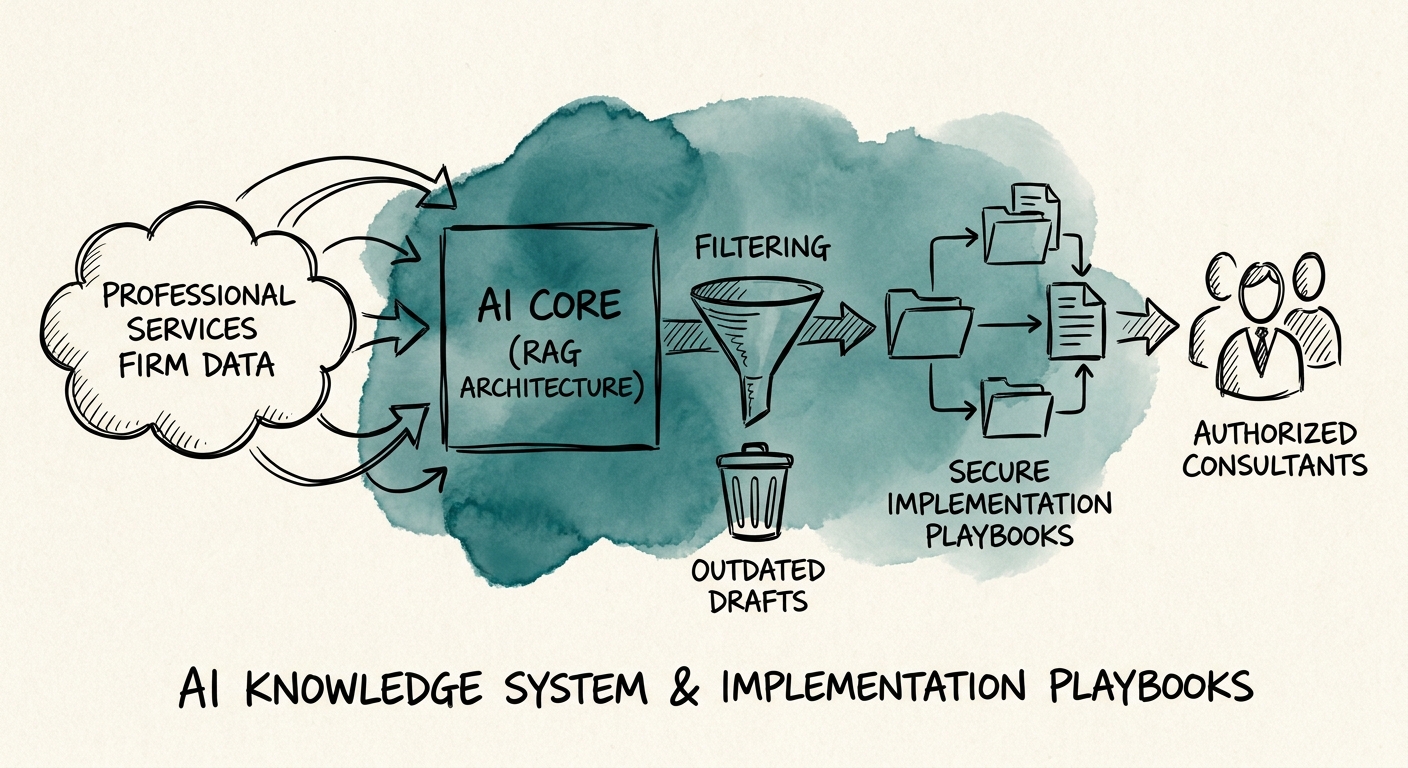
That is the actual problem an AI knowledge system is being hired to solve here, and it is not "answer questions about documents." It is "make sure the answer points to the playbook version that is live today, names the exceptions that apply to this client, and tells the consultant who signed off." Drop the version discipline and AI does not eliminate the 2024-playbook mistake. It serves that mistake instantly, confidently, to every consultant at once.
The adoption pressure is real. U.S. Census Bureau data on AI use at U.S. businesses and OECD research on AI adoption by SMEs both show smaller firms racing to deploy. But Deloitte's State of AI in the Enterprise 2026 is blunt about why most of it underwhelms: value comes from a workflow you can measure and correct, not from a demo that retrieves a paragraph. For an implementation firm, the workflow is narrow on purpose: approved playbooks, release notes, exception logs, and the client-specific constraints that override the defaults.
Version Is the Field That Makes or Breaks Retrieval
Most knowledge-system pilots index whatever is in the drive and call it done. For implementation playbooks that guarantees failure, because two documents can say opposite things and both are technically "in the knowledge base." The fix is unglamorous: every retrievable playbook step carries a version tag, an effective date, and a status — active, superseded, or client-scoped. When AI returns a step, it returns those fields with it. A consultant should never see "do X" without seeing "from Playbook v4.2, effective March 2026, supersedes the v3 migration path."
So design the answer as a packet, not a chat reply. Each result shows: the source playbook and version, the step it pulled, any client-specific constraint that modifies it (the healthcare client who can't do the standard cutover window), the linked exception if one exists, and the delivery owner who approved that version. That last field matters more than people expect. When a consultant can see "approved by the lead who ran the last twelve of these," they trust it — and when they can't, they escalate instead of guessing. CISA's AI data-security guidance should set the permission and retention boundary here, because client-specific constraints often contain things you contractually cannot let leak across engagements.
Be explicit about what AI does not get to decide. It does not approve a rollout exception, change a client cutover plan, or bless a step that conflicts with a signed SOW. NIST's AI Risk Management Framework frames why: the same retrieved sentence is harmless in a planning draft and material the moment it steers a live migration. Then measure five things from week one — playbook-version accuracy (did it cite the active version?), exception reuse, rework hours avoided, time to resolve a rollout question, and how often the delivery lead overrides the AI. If override rates stay high, the answer is never "automate more." It's "your source playbooks contradict each other, and you found out cheaply."
The 90-Day Test: Does Delivery Get Quieter?
Run it as a delivery experiment, not a tech rollout. First 30 days: map one retrieval path end to end — a consultant on a live engagement asks "what's the current cutover sequence for this client type," and you trace exactly which sources answer and whether the delivery lead would defend each one. Kill any source the lead won't stand behind; a stale forked playbook in the index is worse than no index. Days 31 to 60: for every AI answer, ask what your best consultant would have said, and log the gap. Day 90: scale, narrow, or pause until the source playbooks are reconciled.
Here is the tell that separates a good outcome from a polished one. A good result is boring: fewer "which version do I use" questions in the project channel, fewer reviewer rewrites, consultants escalating the genuinely ambiguous cases instead of all of them. A bad result demos beautifully and still has your senior people quietly double-checking every retrieved step against the real playbook by hand — which means you have added a review queue, not removed one. A firm this size cannot carry that.
If playbook retrieval is competing with other first uses of AI on your team, run the AI Opportunity Score to see whether it's the right first bet. Once the review path has produced real evidence — hours saved, version errors caught — pressure-test the economics with the AI ROI Calculator. Human Renaissance sequences exactly this inside the AI Transformation Blueprint, so an implementation firm moves from trustworthy playbook search to the next governed workflow without ever losing track of which version is live.
