The 4:45 PM Slack message every agency knows
An account manager pings the channel: "Does anyone have the current onboarding playbook for SaaS clients? The one in the drive looks old." Three people reply with three different files. A senior strategist who is supposed to be heads-down on a pitch loses twenty minutes adjudicating which version is real. Multiply that by every paid-media setup, every reporting cadence, every QA checklist, every client kickoff, and you start to see where agency margin quietly leaks.
Marketing agencies almost never have a document shortage. They have a retrieval-and-trust problem: the right answer exists somewhere inside an implementation playbook, but nobody can confirm fast enough that it's the current, approved version. And this isn't a small-shop problem you grow out of. The U.S. Census Bureau reported in May 2026 that business AI adoption is already materially higher in larger firms, including 32% of firms with 100 to 249 employees and 37% of firms with at least 250 employees. As an agency scales past 50 people, it accumulates more playbooks, more client-specific variants, and more "ask Sarah, she wrote it" tribal knowledge — exactly the conditions where a governed AI layer earns its keep, and exactly why disciplined pilots beat a firm-wide rollout.
Why pointing a chatbot at the shared drive backfires
Here's the mistake I watch agencies make: they connect a chatbot to the entire Google Drive, demo it once, and call it a knowledge system. Then it confidently surfaces the 2024 paid-social playbook with the deprecated tracking setup, or worse, pulls a client's confidential rate card into an answer for a different account. Now you've taught the team that the tool can't be trusted, which is the hardest reputation to recover.
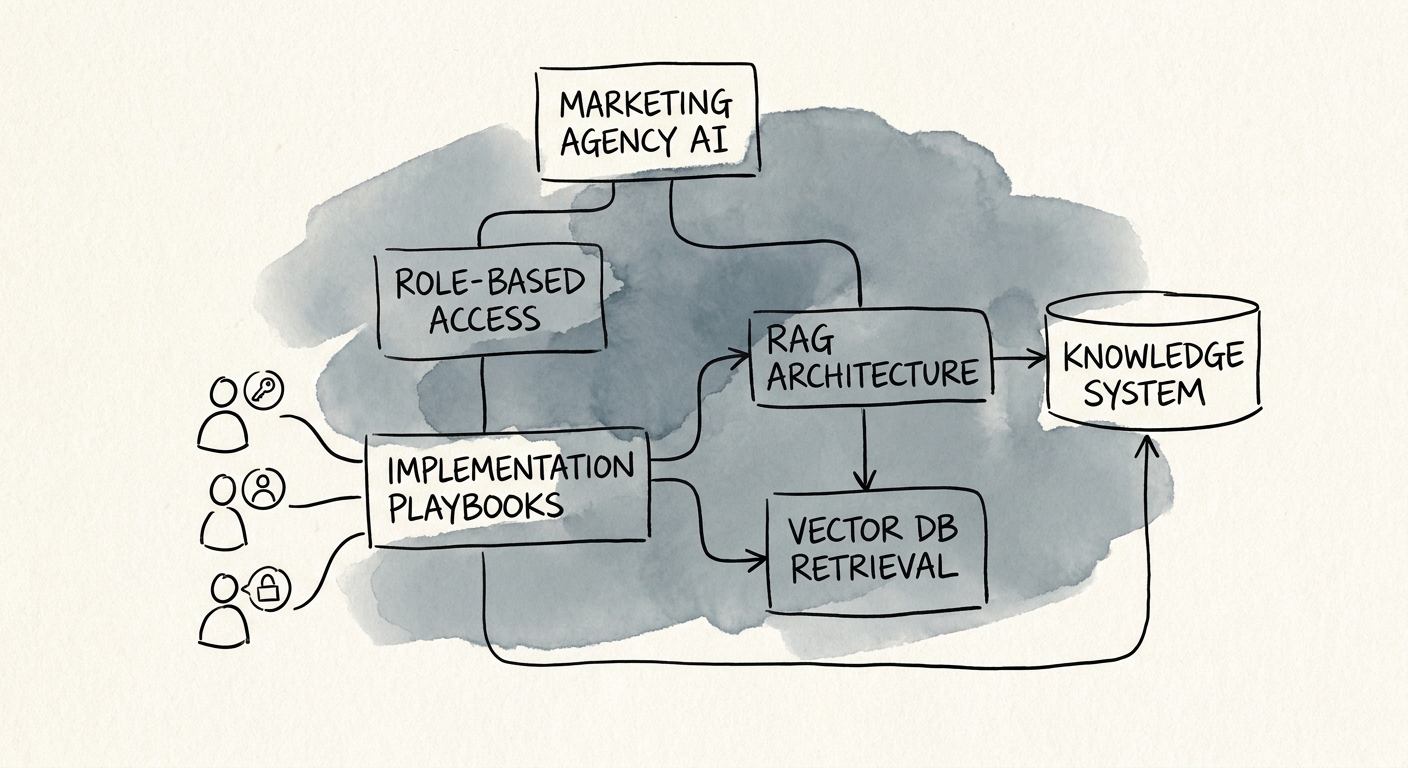
An implementation playbook is a specific, high-value knowledge domain — treat it like one. Before anything gets indexed, tag each playbook by client type, owner, last-approved date, source system, permission group, and confidence level. That metadata is what lets the system retrieve the live version and respect access boundaries instead of flattening everything into one searchable blob. The first build step is unglamorous source cleanup: archive obsolete versions, wall off restricted material (client contracts, margins, anything under NDA) from reusable operating knowledge, and name who owns the answer library after launch. CISA's AI data security guidance is blunt about protecting the data used to train and operate these systems; at agency scale that means access control, source approval, and logging are part of the build, not a later cleanup. Wrap it in the NIST AI Risk Management Framework — map the workflow, measure answer reliability, govern ownership, manage changes — and the assistant should answer only from approved playbooks, cite the file it pulled from, flag when the playbook is silent, and route uncertain answers to a named human. The architecture lives with AI knowledge systems and RAG, not as an unowned side experiment.
Write the twenty questions before you pick a tool
Skip the vendor demos for a week. Instead, write down the twenty questions your team actually asks about implementation playbooks — "What's the current QA checklist before a campaign goes live?", "Which reporting template do we use for retainer clients?", "What's the approved client-onboarding sequence?" For each one, name the single approved source. That list is now your test set: a candidate system either retrieves the right playbook without leaking restricted material, or it fails, and you find out before rollout instead of in front of a client. This discipline is why so many AI pilots stall — Deloitte's 2026 enterprise research found that only 25% of leaders moved 40% or more AI pilots into production. The ones that crossed over had a production owner, not a demo sponsor.
Once retrieval is stable on the twenty questions, instrument the workflow: how often the assistant gets used, how many senior-operator interruptions it avoids, answer quality, and time-to-answer on a kickoff or QA pass. In vendor selection, force the privacy, retention, and data-use review — verify your business-data boundaries, don't assume them. Get one playbook domain governed and trusted, and you have a repeatable pattern for the next one. The next move is documented in the internal knowledge assistant guide, and we use the AI Transformation Blueprint to turn that first governed knowledge system into a broader operating roadmap for the agency.
