The onboarding doc that exists three times
Picture a 40-person agency on a Monday. A new account coordinator needs to kick off a client onboarding. She searches the shared drive and finds three documents named some variation of "Client Onboarding." One was written by the founder in 2023. One was updated by the ops manager last quarter. One is a copy somebody made for a specific retainer client and never renamed. She picks the cleanest-looking one. It's the wrong one. The kickoff goes out missing the brand-asset intake step, and three weeks later a designer is waiting on logo files that should have been collected on day one.
That is the actual failure mode an AI knowledge system over your SOP library has to solve. The problem was never search speed. The problem is that your SOPs, campaign QA checklists, account handoff rules, and creative-spec sheets disagree with each other, and a chatbot pointed at all of them will confidently surface whichever version it ranks highest. You don't get fewer mistakes. You get faster, more authoritative mistakes.
The Census Bureau's data on AI use at U.S. businesses and the OECD's research on AI adoption by small and mid-sized firms both show adoption climbing fast among shops your size. None of that pressure repairs a library where the canonical onboarding SOP is ambiguous. Deloitte's State of AI in the Enterprise 2026 makes the same point a different way: value shows up only when the workflow can be measured and corrected, not when the demo looks slick.
Pick one document type and make it the only source
Don't index the whole drive. Pick the SOP category that causes the most rework, which for most agencies is either client onboarding or campaign QA, and make exactly one document the system's only allowed source for that question. Everything else gets archived or marked as reference, not retrieval. This is dull work. It is also the entire job. An agency that does this for onboarding alone will feel the difference before it touches creative specs or handoff rules.
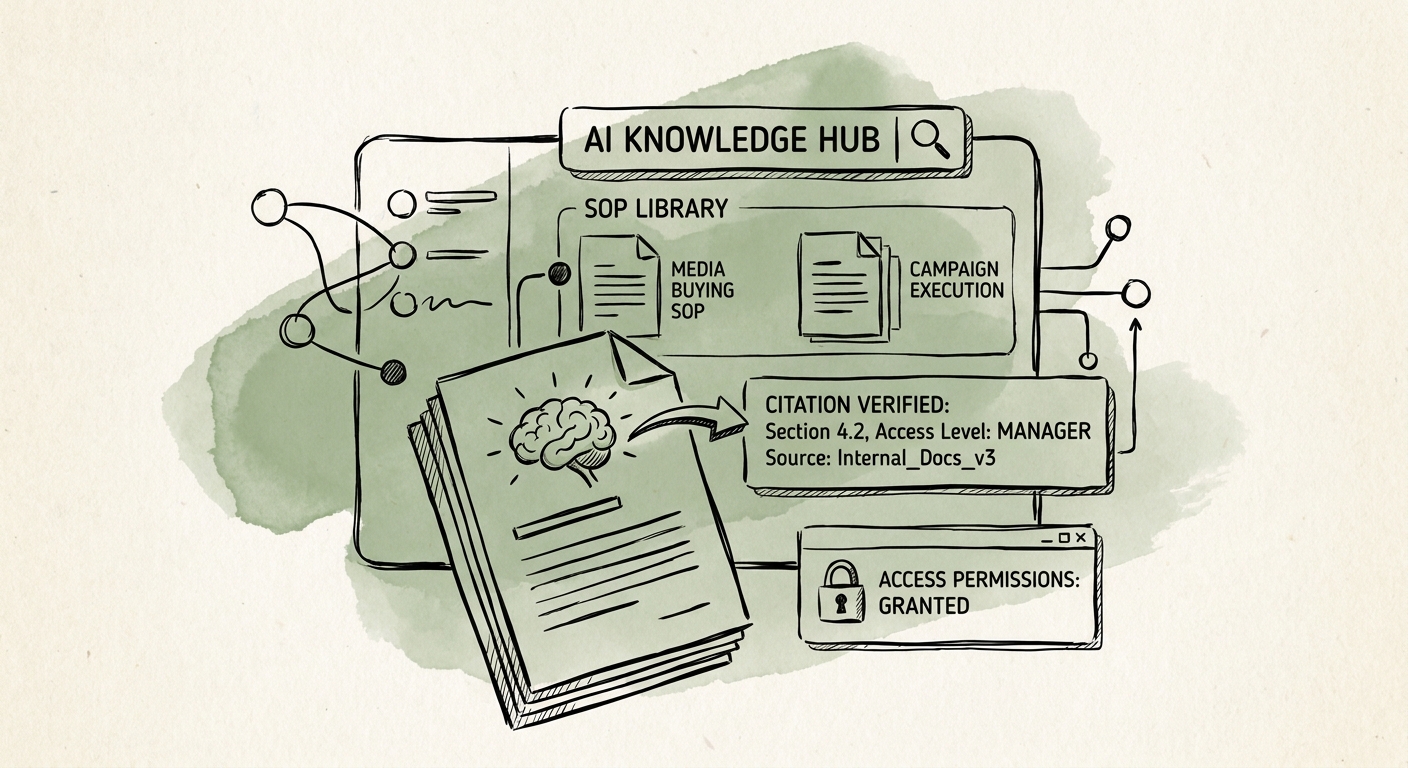
Then give the answer a receipt. When the coordinator asks "what's the onboarding sequence for a new paid-social retainer," the system should return the step list, a flag for any client-specific exception, the SOP version date, and the name of the operations lead who owns it. If it can't show those four things, it shouldn't answer. That receipt is what separates a usable agency tool from a transcript you can't trust. The NIST AI Risk Management Framework frames this as contextual risk, and it fits agencies precisely: a half-right onboarding step is harmless in a brainstorm and expensive the moment it drives a real kickoff.
Two things stay off-limits to the AI no matter how good the retrieval gets: client-specific process exceptions and creative approvals. Those go to a human every time, because a retainer client's bespoke approval chain is exactly the kind of thing a generic answer will flatten. Set the permission boundary, retention rule, and access log for these documents deliberately, the way CISA's AI data-security guidance describes, and lean on enforceable vendor terms like OpenAI's enterprise privacy commitments so client SOWs don't leak into a training set. Then measure the things that actually move: SOP-version accuracy, campaign rework hours, account-handoff defects, and how often a reviewer overrides the answer. If those don't drop, the fix is cleaner source ownership, not a bigger model.
The 90-day test: does the wrong doc still get pulled?
Run it on a clock. In the first 30 days, trace every onboarding question from the moment someone asks it to the answer they act on, and delete or archive any source the ops lead won't personally vouch for. Days 31 to 60, sit a trained account manager next to the system and compare its answer to what they'd actually do, exception by exception. By day 90 you make one call: scale to the next document type, narrow the scope, or pause until the source library is genuinely clean.
You'll know it worked by how boring it feels. A good outcome is the new coordinator pulling the right onboarding sequence on her first try, the designer getting brand assets on day one, and nobody emailing "wait, which doc is current?" A bad outcome looks polished in a demo but leaves your ops manager still spot-checking SOPs and creative specs by hand, now with a second review queue bolted on top. A mid-market agency cannot afford an automation layer whose main output is more work for the person who already knew the answer.
If you're weighing this against other places to start, run the AI Opportunity Score first, and only reach for the AI ROI Calculator once the review path has produced real numbers on rework hours saved. We package that exact sequence inside the AI Transformation Blueprint, so an agency can go from "fix the onboarding SOP" to the next governed workflow without ever losing track of which document is the source of truth.
