The "we said yes on the call" problem
Here is the moment that should make every professional services partner nervous. A client emails six weeks after a working session: "On our March 12 call you agreed to absorb the data migration in the fixed fee." Your project lead doesn't remember it that way. So someone opens the recording archive, scrubs through 74 minutes of a Zoom transcript, and tries to reconstruct what a senior consultant actually committed to versus what got floated, debated, and dropped.
That scramble is the real use case for an AI knowledge system over a meeting transcript library — not "search all our calls." Meeting transcripts are a uniquely treacherous document type because they record speech, and speech is full of things that were never decisions: a manager thinking out loud, an associate proposing an option that got rejected two minutes later, a client venting that a competitor quoted them less. A contract has a signature. An email has a sender. A raw transcript has none of that structure, and an AI that retrieves over it will happily quote a sentence someone said in frustration as if it were a binding commitment.
So before any retrieval, the question for a firm in the 100-249 employee band — where Census Bureau data puts AI use near 32% — is narrower than "should we deploy this." It is: which calls, whose decisions, and under what client consent. OECD research on smaller firms and Deloitte's 2026 enterprise AI work both land on the same point: the firms getting value aren't the ones with the biggest transcript pile, they're the ones who decided in advance what a transcript is allowed to prove.
Tag the talk before you trust the search
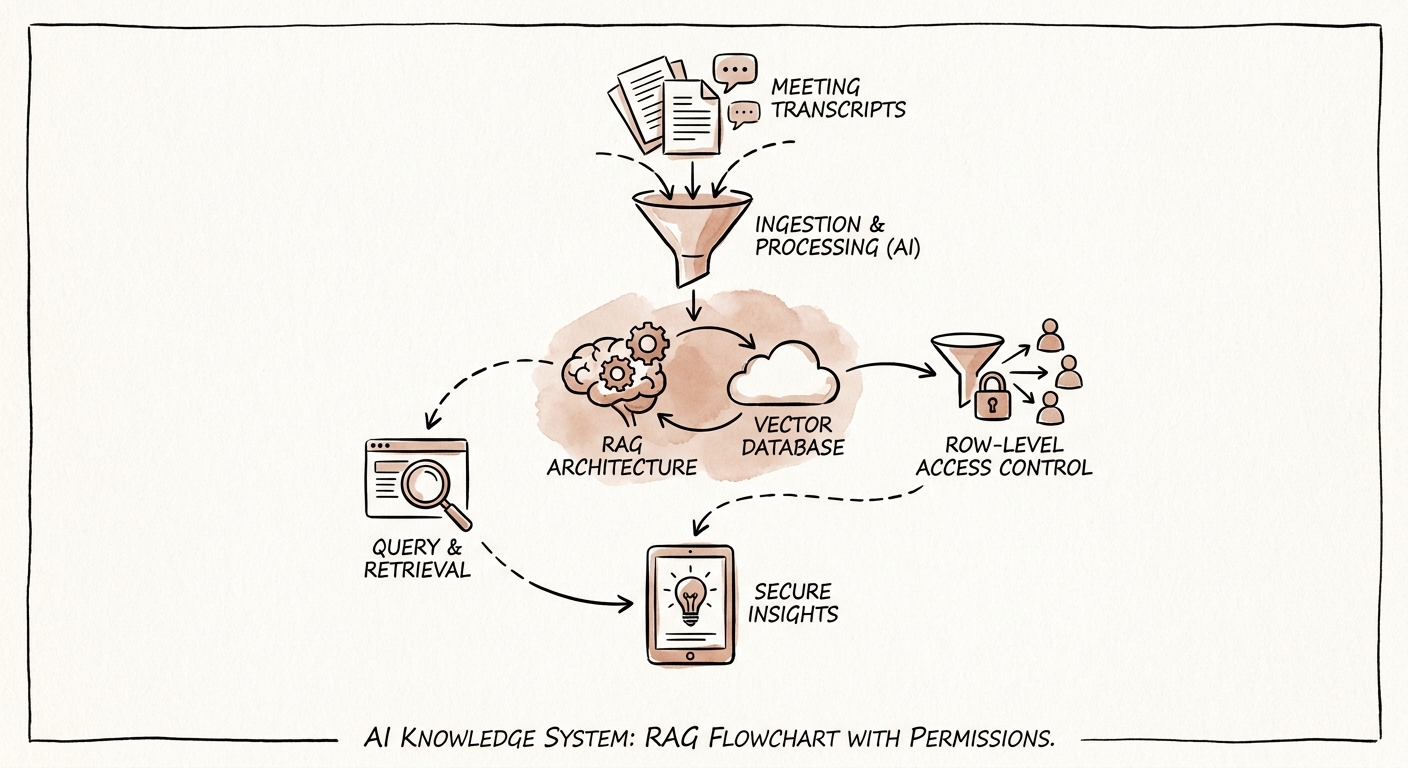
The fix is not a fancier vector database. It is a labeling layer that sits between the raw transcript and the answer, marking every retrievable passage as one of three things: a decision (a client or partner explicitly agreed to something), an action item (someone owns a next step with a date), or unresolved talk (ideas, objections, asides — interesting, but binding on no one). Say a 140-person advisory firm runs 200 client calls a month. If retrieval can't tell those three apart, your AI will surface "we'll throw in the extra workshop" with the same confidence whether the partner actually committed it or an analyst speculated about it.
Layer consent on top of that. Professional services calls routinely contain client-confidential context — board dynamics, pending layoffs, M&A chatter — that was shared in the room under an implied wall. Your transcript library needs a consent flag at the call level (was this recorded with the client's knowledge, and for what purpose) before a single line is searchable. This is exactly where CISA's data-security guidance earns its keep: it pushes you to define the permission boundary, the retention window, and the access log for the recordings themselves, not just the AI output. And because a sentence that's harmless in a draft becomes material the instant it enters client delivery, the NIST AI Risk Management Framework reframe is useful — judge risk by where the answer lands, not by how the model behaves in a sandbox.
Make the review artifact concrete. When the system answers "what did we commit to on the Henderson account," it should return the timestamped source passage, its decision/action/talk label, the consent status of that recording, and the named partner who can confirm it — not a fluent paragraph with no trail back. Then measure five things over the first release: how often answers cite a verifiable source passage, how many open action items the library surfaces that were getting dropped, retention-policy compliance on the underlying recordings, how often a reviewer has to override a "decision" label, and how long it now takes to reconstruct what was actually agreed. If those don't move, the answer is cleaner labeling, not broader search.
The 90 days that tell you whether to scale
Days 1-30: pick one delivery team and one client portfolio, and map a single question end to end — "what did we agree to and who owns the next step." Strip out any recording the responsible partner won't personally stand behind, and kill the fantasy of indexing every call the firm has ever made. Days 31-60: run the library in parallel with how your project leads already reconstruct commitments, and compare. Where the AI labels a passage a "decision," would a senior consultant agree it was binding? Track the disagreements; they're your real signal. By day 90 you decide: scale it, narrow it to commitment-tracking only, or pause until the consent and retention plumbing is actually trustworthy.
A good outcome here looks unglamorous. Your weekly account reviews get shorter because nobody is scrubbing recordings to settle "did we say yes." Dropped action items go down. The partner reading a client email knows in 30 seconds what was actually committed. A bad outcome looks slick in the demo and still leaves managers manually checking transcripts before every client conversation — at which point you've added a review queue instead of removing one, which a mid-market firm can't afford.
If transcript retrieval is competing with three other AI ideas for the same budget, run them through the AI Opportunity Score before you build anything, and only reach for the AI ROI Calculator once the review path has produced real time-saved evidence — not a projection. When you're ready to sequence this into the next governed workflow without losing control of who can see which client's words, that's what the AI Transformation Blueprint is built to do.
