Every consultant rediscovers what the firm already knew
A senior consultant spent three days last quarter building a pricing model for a healthcare client. The exact framework — assumptions, objection-handling, the math behind the floor — was discussed in detail on a recorded call eight months earlier with a nearly identical client. Nobody could find it. The transcript existed. It was sitting in the meeting library with 4,000 hours of its peers, untitled and unsearchable, between a status standup and a vendor demo.
That is the real shape of the problem at a consulting firm. You do not have a content shortage; you have a retrieval-and-trust problem. The approved answer exists, but no one can surface the current, sign-off-able version fast enough to use it in front of a client. So the work gets rebuilt — or worse, someone interrupts a partner to ask a question the firm answered last year. The U.S. Census Bureau reported in May 2026 that AI adoption is already materially higher in larger firms, including 32% of firms with 100 to 249 employees and 37% of firms with at least 250 employees. Mid-sized firms are big enough to have scattered, valuable operating knowledge and disciplined enough to need real pilots before they wire AI into client delivery.
Transcripts are the hardest knowledge domain to govern — start there anyway
Meeting transcripts are not clean documents. They are hours of half-finished thoughts, hypotheticals a partner later walked back, pricing floated and rejected, and — the part that should keep you up at night — one client's confidential situation discussed in the same library where another client's team can search. Point a generic chatbot at that and you have built a confidentiality incident with a search box.
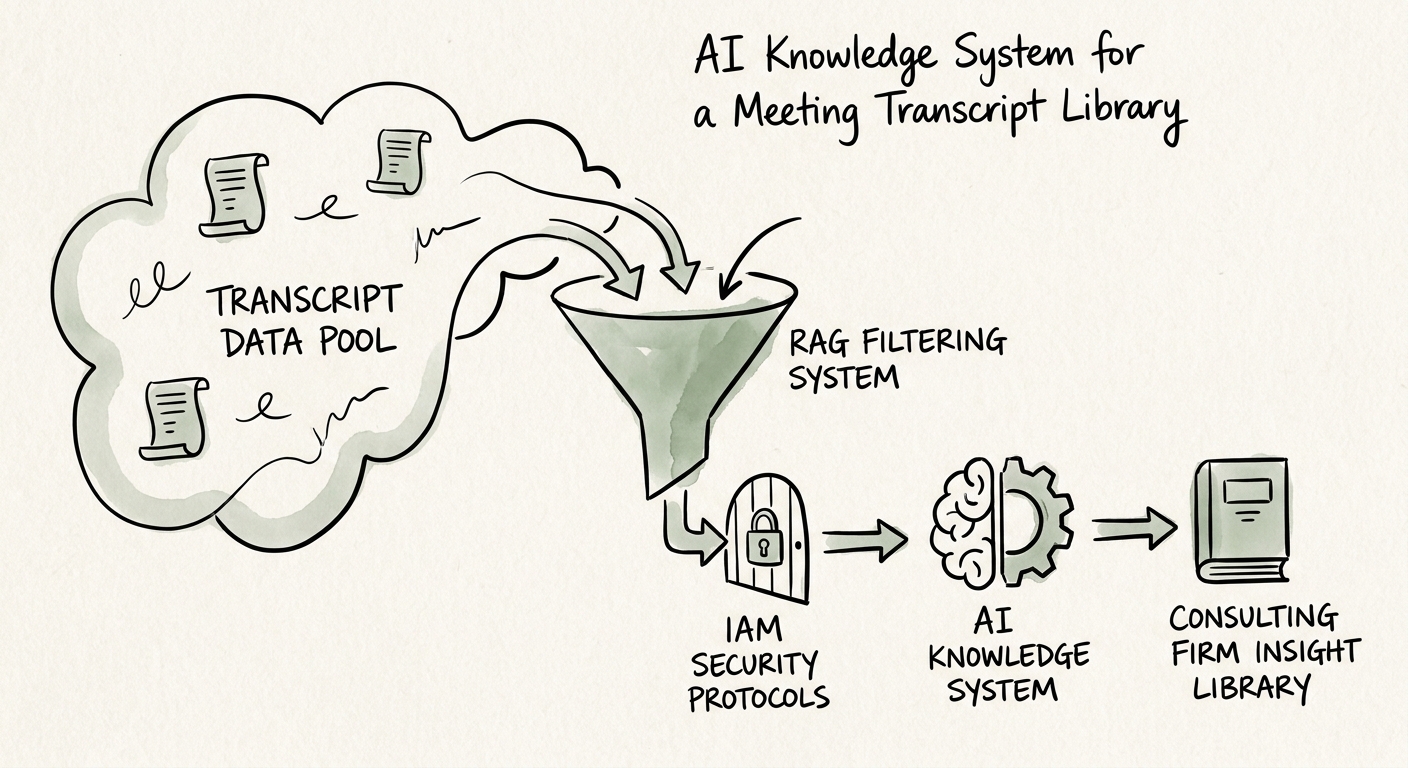
So the first move is not tooling. It's source cleanup and boundaries. Tag every transcript by client, engagement, owner, date, and permission group before a single line is indexed. Quarantine restricted material from reusable methodology — the "how we structure a margin-recovery diagnostic" knowledge that any consultant should reuse versus the "what this specific CEO admitted on the call" knowledge that must never cross engagements. CISA's AI data security guidance is blunt about protecting the data used to train and operate these systems; in a 50-to-300-person firm that means access control, source approval, logging, and a named owner for exceptions — settled before launch, not after the first leak.
Run it on the NIST AI Risk Management Framework: map the workflow, measure answer reliability and data-exposure risk, govern ownership, manage drift as new calls pile in weekly. The assistant answers only from approved transcripts, cites the exact call and timestamp it pulled from, says "I don't have an approved source" instead of inventing one, and routes anything uncertain to a human who owns that answer. That's a governed retrieval layer — the kind of AI knowledge system and RAG build that survives a client audit, not an unowned side experiment.
The twenty-question test, before you buy anything
Here is what you do Monday. Write the twenty questions your consultants actually ask about past calls — "what discount did we land on for a Series B SaaS client," "how did we frame the build-vs-buy recommendation for a manufacturer," "which objection killed the renewal." For each, name the approved transcript that holds the answer. Then score any candidate system on two things: does it retrieve the right source, and does it refuse to surface a transcript the asker isn't cleared to see? If it nails the answer but exposes a restricted call, it failed.
This is the discipline that separates a demo from production. Deloitte's 2026 enterprise research found that only 25% of leaders moved 40% or more of their AI pilots into production — and the difference is almost always whether the first system had a real owner instead of a demo sponsor who moved on. Once retrieval is stable, measure what matters: adoption, partner interruptions avoided, answer quality, and time-to-deliverable in the actual engagement workflow. Push vendors on privacy, retention, and data-use terms in writing — verify the business-data boundary, don't assume it. The next build is laid out in the internal knowledge assistant guide, and we use the AI Transformation Blueprint to turn one governed transcript library into a firm-wide AI operating roadmap.
