
The version-three problem
Picture a 45-person consulting firm. A senior associate is staffing a new healthcare client on a Tuesday and needs the current data-handling policy before the kickoff call. They search the shared drive. They find "Data Policy FINAL," "Data Policy FINAL v2," and a PDF in a 2024 engagement folder that someone clearly edited for that specific client. Three versions, no clear owner, no date that means anything. So they pick the one that looks most complete and move on. That guess is now governing how a regulated client's data gets handled.
That is the actual problem an AI knowledge system gets pointed at in a consulting firm — and it is the reason the order of operations matters more than the tooling. The research keeps landing on the same constraint: smaller firms win by tying AI to a specific, painful workflow rather than turning it loose. The RSM middle-market AI survey, the San Francisco Fed analysis of AI and small businesses, and the OECD report on AI adoption by SMEs all point the same direction.
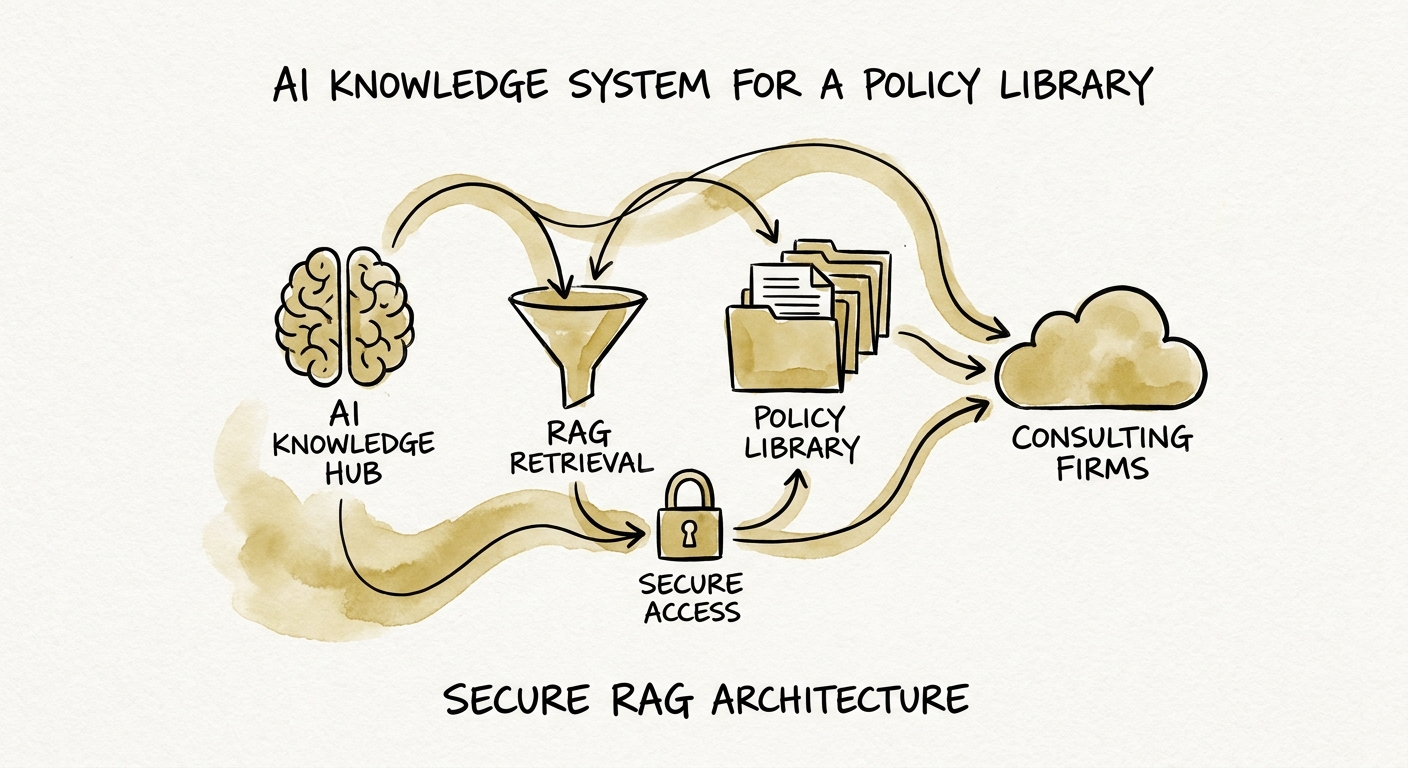
For a consulting firm, the "source set" is not abstract. It is your engagement methodology, your data-handling and confidentiality policies, your SOW and rate-card templates, your delivery quality standards, your onboarding playbook. Here is the trap: if you connect an AI assistant to a library where "FINAL v2" still beats the real policy in three of five folders, the assistant will confidently cite the wrong version — and now it does so in eight seconds, on every project, with a tone of authority your associate didn't have. Before any retrieval, do the boring map: for each policy, who owns it, who reviews it, what is the one approved copy, and what does a good answer cite. That map is the work. The model is the easy part.
Why client confidentiality changes the whole build
Most knowledge-system advice treats document access as a permissions detail. In a consulting firm it is the entire risk surface, because your knowledge isn't just policies — it's client work product. The SOW you wrote for one client references their roadmap. The "case study" draft in the marketing folder names a deal that was never meant to leave the room. The retrospective from a turnaround engagement quotes the client CFO. Index all of that into a single retrieval layer and you have built a machine that can surface Client A's confidential strategy to the associate working on competing Client B — which is exactly the cross-engagement wall your contracts promise to maintain.
So the classification step is not housekeeping; it is the thing that keeps you out of a breach-of-confidentiality conversation. The NIST AI Risk Management Framework gives leadership a shared language for mapping where the system can do harm, and CISA's AI Data Security Best Practices applies directly the moment the library touches client, contract, or personnel data. Practically: separate firm policy (broadly retrievable) from client work product (walled, or excluded entirely), strip the named examples before anything gets indexed, and set retrieval boundaries that respect engagement teams.
Then pressure-test the tooling. If you're running an enterprise assistant, read Microsoft 365 Copilot's privacy and data controls; if you're building custom on a model API, read OpenAI's enterprise privacy commitments. The question a partner should be able to answer in a client audit is plain: which documents did this answer draw from, who reviewed it, and did anything confidential leave the approved environment? If you can't answer that, you don't have a knowledge system — you have an unlogged liability.
Ship the narrow one, measure the right things
The production version should be embarrassingly smaller than the demo that got the partners excited. Pick a single path — say, "what is our current data-handling and confidentiality policy, and what does it require on a healthcare engagement." Connect only the approved, owned, current sources. Require a citation in every answer so a consultant can click through to the real document. Route anything the system can't answer cleanly to a named reviewer instead of letting it guess.
Then watch metrics that mean something for a firm that bills by the hour: retrieval accuracy on policy questions, how often a reviewer has to correct an answer, minutes saved per associate per week versus the old folder hunt, and — the underrated one — the list of questions the system couldn't answer. That last list is gold. Every gap it surfaces is a policy your firm thought it had but didn't, the kind of thing that only shows up today when an associate improvises on a live client.
For the source-boundary design, the internal AI knowledge assistant guide walks through walling work product from firm policy. Before you connect anything, run the SMB readiness assessment to confirm you actually have owners, permissions, and review capacity in place — because a knowledge system without those isn't ready, it's just faster wrong answers. The firms that win here build something that answers from trusted sources and openly flags where the policy is still missing, instead of papering over the gap with confident prose.
