The Tuesday-afternoon security questionnaire
A 60-person consulting firm wins a deal with a regional health system. Three days before kickoff, procurement sends a 240-question security questionnaire and a request for your latest SOC 2 evidence package. The partner who knows where the control narratives live is on a plane. The associate searching the shared drive finds three folders named "Compliance_FINAL," "Compliance_FINAL_v2," and "Compliance_USE_THIS_ONE" — last touched at different times by people who have since left. By the time someone assembles an answer, it is stale, and nobody can say with confidence which version the client actually received.
That scramble is the workflow an AI knowledge system should fix — and it is also the workflow that punishes you hardest if you bolt an assistant on top of a messy library. Point a retrieval tool at all three "FINAL" folders and you have not solved anything; you have built a faster way to surface the wrong control narrative with total confidence. The constraint smaller firms keep running into shows up across the research: the RSM middle-market AI survey, the San Francisco Fed analysis of AI and small businesses, and the OECD report on AI adoption by small and medium-sized enterprises all land on the same point — adoption pays off when it is tied to one painful, repeated workflow, not broad experimentation.
So start with the evidence path, not the assistant. For a consulting firm, the source set is specific: control narratives, completed evidence requests, approval notes, policy exceptions, and the client-facing deliverables that quietly reference all of it. Map that set, name a single owner per source, and define one launch criterion — a partner can ask "what's our current answer to control CC6.1, and which document backs it?" and get a cited answer instead of a folder-archaeology project.
For consulting firms, the leak risk is somebody else's data
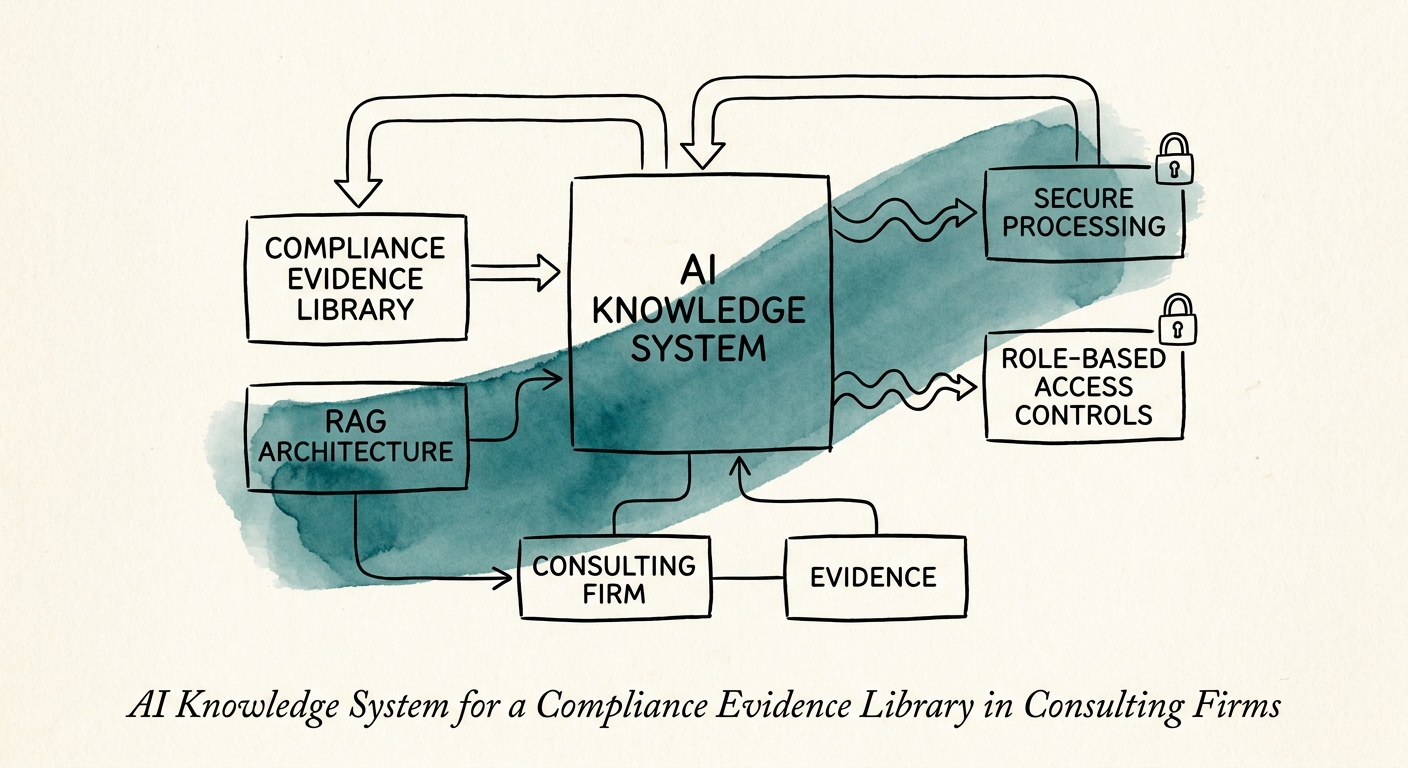
Most AI-governance advice assumes you are protecting your own secrets. A consulting firm's hardest problem is the inverse: your evidence library is saturated with other people's confidential material — client control environments, vendor contracts, a prior engagement's penetration-test findings, an exception memo that names a client by name. Retrieval that helpfully pulls Client A's remediation detail into an answer you are drafting for Client B is not a quality bug. It is a breach, and it is the kind that ends master service agreements.
This is why classification comes before retrieval, not after. Before you connect anything, walk the library and tag what is genuinely reusable boilerplate (your own policy templates, your standard control language) versus what is client-bound and must never cross an engagement boundary. The NIST AI Risk Management Framework gives leadership a shared way to map and rank those risks, and CISA's AI Data Security Best Practices is directly on point the moment the system touches client, vendor, contract, or security data — which, for an evidence library, is constantly. Set the permission boundaries at the engagement level, and decide up front that every output must cite an approved source or it does not ship.
Then check the tool itself against its own commitments. If you are running on Microsoft 365 Copilot's privacy and data controls or building on OpenAI's enterprise privacy terms, confirm in writing that your evidence corpus is not training anyone's model and stays inside your tenant. The governing question is the one an auditor will eventually ask you, framed exactly the way you'll have to answer it for your own clients: can you prove which documents an answer used, who reviewed it, and that no confidential material left the approved environment?

Ship the boring version, and let it show you the gaps
The production system should be smaller and duller than the demo. Pick one path — say, "answer SOC 2 evidence requests from our approved control library" — connect only the classified, owner-assigned sources, force a citation into every draft, and route anything the system can't answer cleanly to a named reviewer before it reaches a client. Resist the urge to launch firm-wide knowledge search on day one; that is how confidential cross-client leakage happens before anyone has built the muscle to catch it.
Measure five things, not vanity engagement: retrieval accuracy (did it cite the right control?), reviewer edit rate (how often does the partner rewrite the draft?), time saved per questionnaire, the count of questions it couldn't answer, and — the most valuable output — the source gaps it exposes. When the system repeatedly can't find a current narrative for a control, you haven't found an AI limitation. You've found a real hole in your evidence library that an auditor would have found for you, at a far worse moment.
To set the source boundaries and reviewer roles before you connect anything, work through the internal AI knowledge assistant guide, then pressure-test whether your ownership and review capacity are actually ready with the SMB readiness assessment. The win for a consulting firm isn't a slick chatbot. It's the Tuesday when the security questionnaire lands, the right answer comes back cited in minutes, and you already knew which evidence was missing.
