The slide that was right in 2024 and wrong in the room today
Picture a senior consultant at a 30-partner advisory firm, building a board deck the night before a meeting. She remembers a framing slide from a prior engagement that nailed exactly this argument. She finds the old deck, lifts the slide, drops it in. It looks sharp. What she can't see in the file name is that the market-sizing figure on that slide was sourced in early 2024, the client it was built for had a structurally different cost base, and one bullet quietly assumed a regulatory regime that has since changed.
That is the real hazard of an executive briefing archive. It isn't that the work is hard to find. It's that the most reusable material — the board-ready language, the partner's sharpest framing, the analysis that won the last pitch — carries invisible context: who it was for, what was confidential, and when its facts were last true. Deloitte's 2026 AI research points to firms moving past pilots toward production value, but a briefing archive only delivers that value if reuse is governed instead of trusted.
So the first thing to automate is not "search the whole archive." It's a narrower, more useful job: a briefing-reuse workflow that, when a consultant reaches for prior work, tells her whether it's cleared for reuse, what was client-confidential, what needs redaction, and which facts need a fresh source check before they appear in front of a board again.
The metadata matters more than the model
Most firms assume the bottleneck is retrieval quality — a better embedding, a smarter chatbot. It isn't. The bottleneck is that a slide in a shared drive carries almost no machine-readable context about its own reuse risk. Before you spend a dollar on model capability, the archive needs a thin layer of structure on each briefing: who owns it, the client-confidentiality tier, whether reuse is approved, the topic, the effective date of its claims, source freshness, the audience level it was written for, and who must review it before it leaves the building.
NIST's AI Risk Management Framework maps cleanly onto this because briefing reuse is exactly a context-mapping problem: you're measuring whether an output is still accurate and managing the specific risk of advice that looks authoritative because it once was. An expired stat in a confident slide is more dangerous than no slide at all — it passes the eye test.
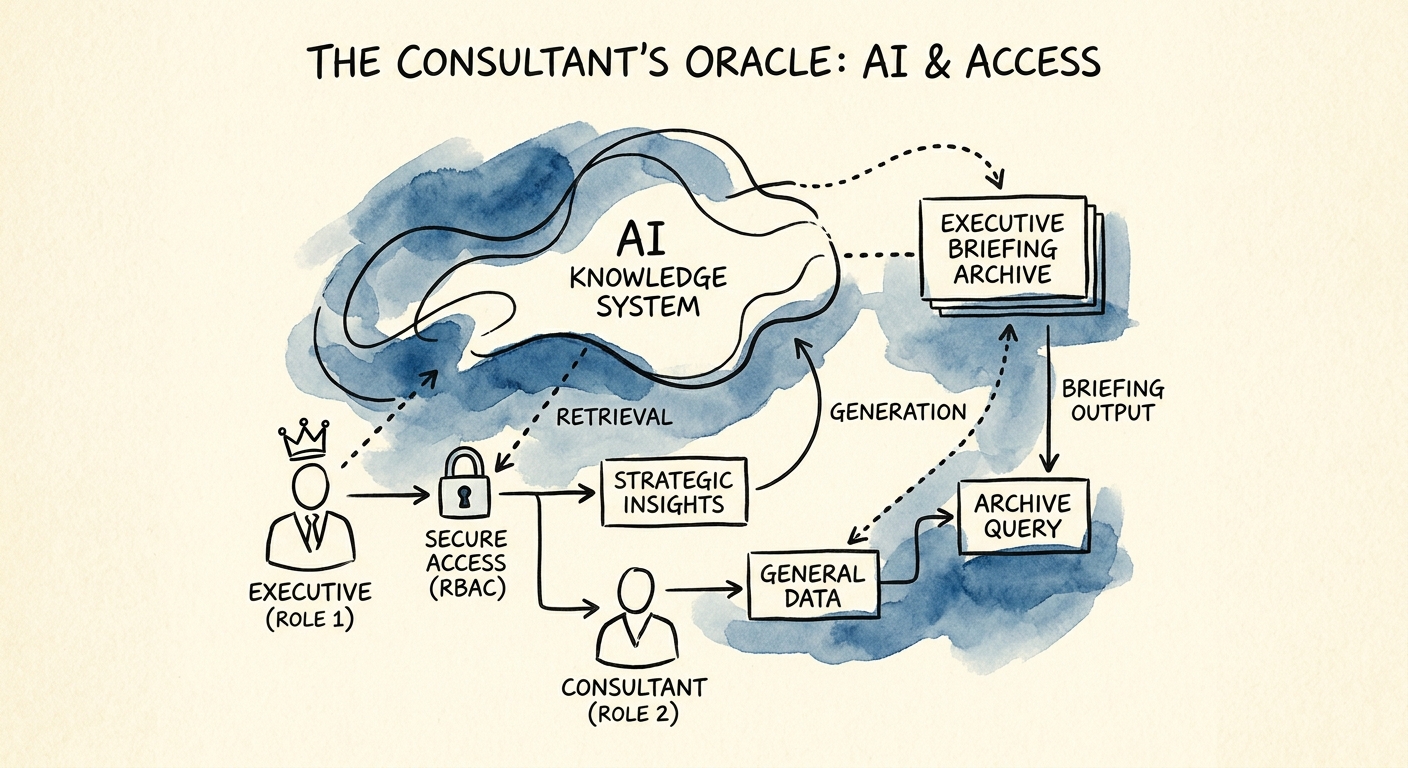
Then the access layer. CISA's guidance on securing AI data translates here into hard boundaries: the assistant should surface the originating briefing and its date, hide client-restricted passages from anyone not cleared to see them, keep anonymized illustrative examples physically separate from live client records, and route any high-stakes reuse to a senior reviewer instead of letting it slip silently into a deck. A practical first cut: pick one practice area — say, the market-entry briefings, where ownership and redaction rules are already understood — and structure that subset first rather than boiling the whole drive.
Run the test, then decide whether to scale
Here's the honest go/no-go. You're ready to build when the archive can actually be segmented by client sensitivity and when practice leaders have agreed on one uncomfortable question: how do we treat material that's two years old? A configured knowledge platform may be enough if all you need is citation-backed retrieval. You only need custom workflow logic when approval status, redaction, and reviewer routing have to be enforced before any excerpt leaves the archive — not suggested, enforced.
Wait if the archive is a shared-drive pile with no owners, no date discipline, and no agreement on what's reusable. Pointing AI at that doesn't make it findable; it makes the wrong things findable faster. In that case the first work isn't a model at all — it's a briefing inventory, a reuse-risk rubric, and a small pilot connected to the firm's broader AI transformation blueprint.
What you're proving in that pilot is narrow and measurable: that the archive can speed senior work without blurring whose context it was. Track briefing-cycle time, how often a reviewer has to correct the assistant, how many redaction catches it makes before client material goes out the door, and how many unsupported or expired claims it strips out. The win isn't "the consultant found the slide faster." The win is "the consultant found the slide, saw it was last supported in Q1 2024, and was prompted to re-source the number before it hit the board deck."
This matters disproportionately at mid-market advisory firms, where a handful of partners hold most of the institutional memory in their heads and their old decks. The system should make that memory searchable — and, in the same motion, make its risk visible: the client-specific assumptions, the dated statistics, the market claims that need a refresh, the sections a junior associate shouldn't reuse without a partner's eyes. Retrieval and restraint have to move together, or you've just built a faster way to spread stale claims.
Give leadership an evidence packet they can poke holes in during a normal partner meeting: for each reuse, name the source briefing, show what the assistant recommended, capture the edit a human made, and note what happened to that piece of work downstream. Keep the starting dataset deliberately small — briefing metadata, approval status, confidentiality tier, date sensitivity, source freshness — and decide the required fields, the exclusion rules, and the escalation triggers before you expand past the first practice group. If the numbers don't move — if redaction catches stay flat and expired claims keep slipping through — fix ownership, permissions, and source quality before you add a single layer of automation on top.
