The 2 a.m. alert is the wrong place to begin
Picture a managed security services firm running a 24/7 SOC for forty clients. A tier-one analyst is staring at 1,400 alerts in the queue, 90% of them duplicates or known-benign noise from the same three EDR sensors. The temptation is to point AI straight at the firehose and let it auto-close, auto-remediate, auto-respond. That is exactly the move that turns one misconfigured rule into forty client incidents.
Start instead where being wrong is recoverable and being right is visible: alert enrichment, duplicate grouping, drafting the incident summary, assembling the evidence packet, and pulling prior context from past tickets on the same client. These are jobs where the analyst still signs off, so a bad AI suggestion costs a few seconds of review, not a breach notification. CISA's artificial intelligence guidance and the NIST AI Risk Management Framework both land on the same point for systems touching sensitive environments: secure design, mapped risk, and a named human accountable for the output.
The line you do not cross in week one: an AI workflow that silently remediates client infrastructure, downgrades a severity on its own, or pipes raw client telemetry into a tool without a documented data boundary. In a multi-tenant SOC, those three mistakes are not bugs. They are incidents you caused.
Your real product is the audit trail, not the closed ticket
For a cybersecurity services firm, the deliverable a client actually buys is defensible reasoning. When a client's GC asks why an alert was deprioritized at 3 a.m., "the model said so" ends the relationship. So the value of AI in the SOC is not measured in tickets per hour. It is measured in cleaner evidence, fewer dropped handoffs at shift change, escalations that route correctly the first time, and a trail that shows how an analyst reached a recommendation. IBM's Cost of a Data Breach research and Microsoft Security Insider research keep the business case anchored where it belongs: dwell time and operational maturity, not raw speed.
Before a single workflow connects to SIEM, SOAR, EDR, ticketing, or the client reporting layer, write down five things and treat them as non-negotiable: which data the model may see, where the model boundary sits per tenant, which enrichment sources are sanctioned, what the analyst must review before sign-off, and which clients have contractual exclusions that override the default. A 25-person SOC and a 200-analyst MSSP both need this, but the larger shop needs it more — because at scale, one unlogged enrichment call against a regulated client's data is a contract breach repeated forty times over.
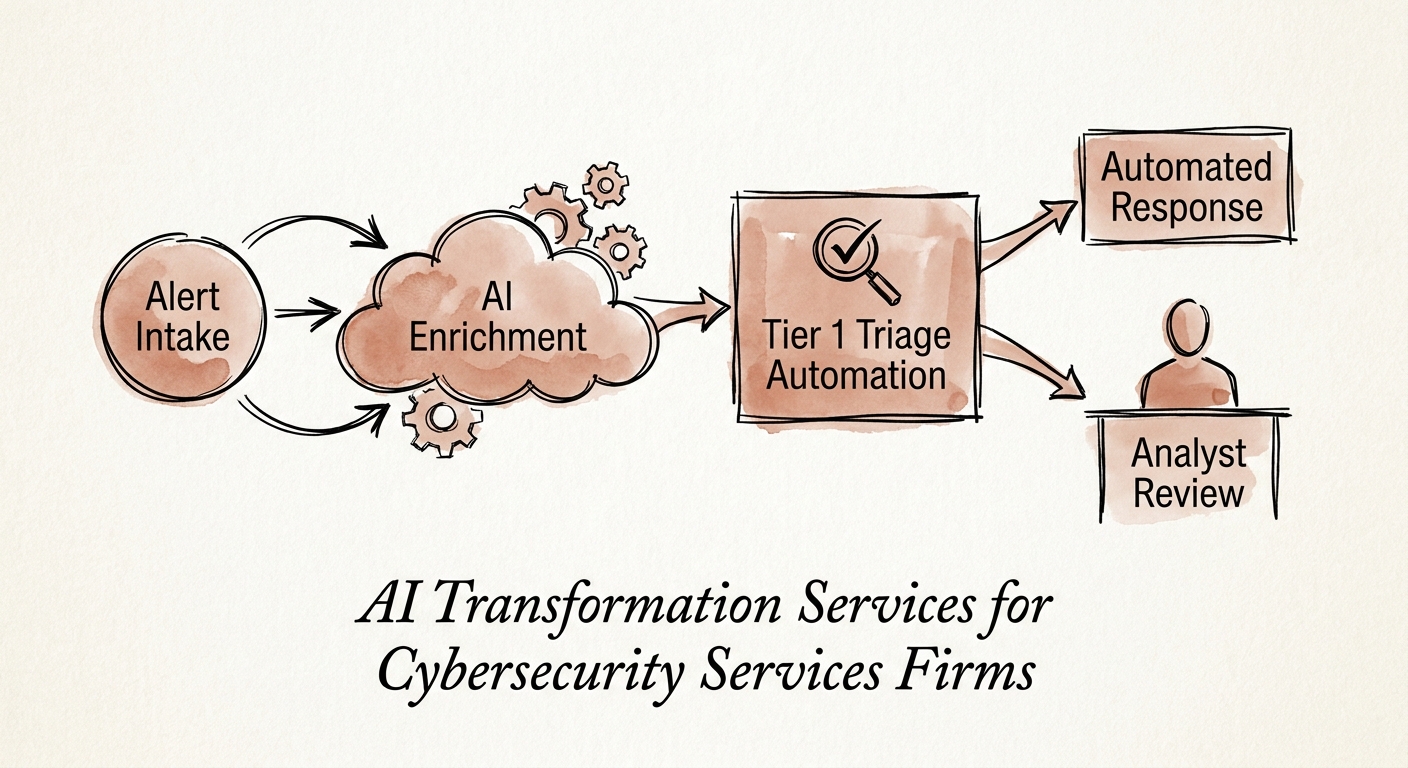
What you can do Monday
Pick one workflow and instrument it before you automate it. The easiest honest win is evidence assembly: measure, today, how long it takes an analyst to gather context, write the summary, and produce the client-facing packet for a single incident. Then watch four numbers as you introduce AI into that step — assembly time, analyst review quality (how often the draft is corrected), queue aging across shift boundaries, and client-report completeness. If review-correction rates climb, the model is creating work, not removing it, and you back it out. Responsible AI in a SOC has to be operationalized this way, not declared in a policy PDF — a theme PwC's Responsible AI survey repeatedly surfaces as the gap between firms that talk about governance and firms that run it.
From there, split by the type of work. When the job is retrieval — runbooks, prior incidents, a client's known-good baseline — that is AI for IT and knowledge management. When the job is governed routing across the SOC toolchain, with enforced review gates and per-tenant boundaries, that is AI workflow automation. Map your queue to those two buckets and you will know what to build first.
