The vendor invoice that posted twice
Picture a 120-person distribution business. A clerk pastes a scanned vendor invoice into ChatGPT Business, asks it to pull the total, the PO number, and the line items, and gets a clean answer in four seconds. She types those numbers into the ERP. It works. So she does it again the next day, and the next, and within a month half the AP team is doing the same thing — pasting documents into a chat window, eyeballing the output, keying it into the system of record by hand.
Then a duplicate posts. A faded total reads $1,480 instead of $1,480.00 written as $14,800 on a second page the model never saw. Nobody can reconstruct which invoice version the clerk actually looked at, because the chat thread is gone and the ERP just shows a number. That gap — between "the model read the document" and "the right value is in the system, and we can prove it" — is the entire decision.
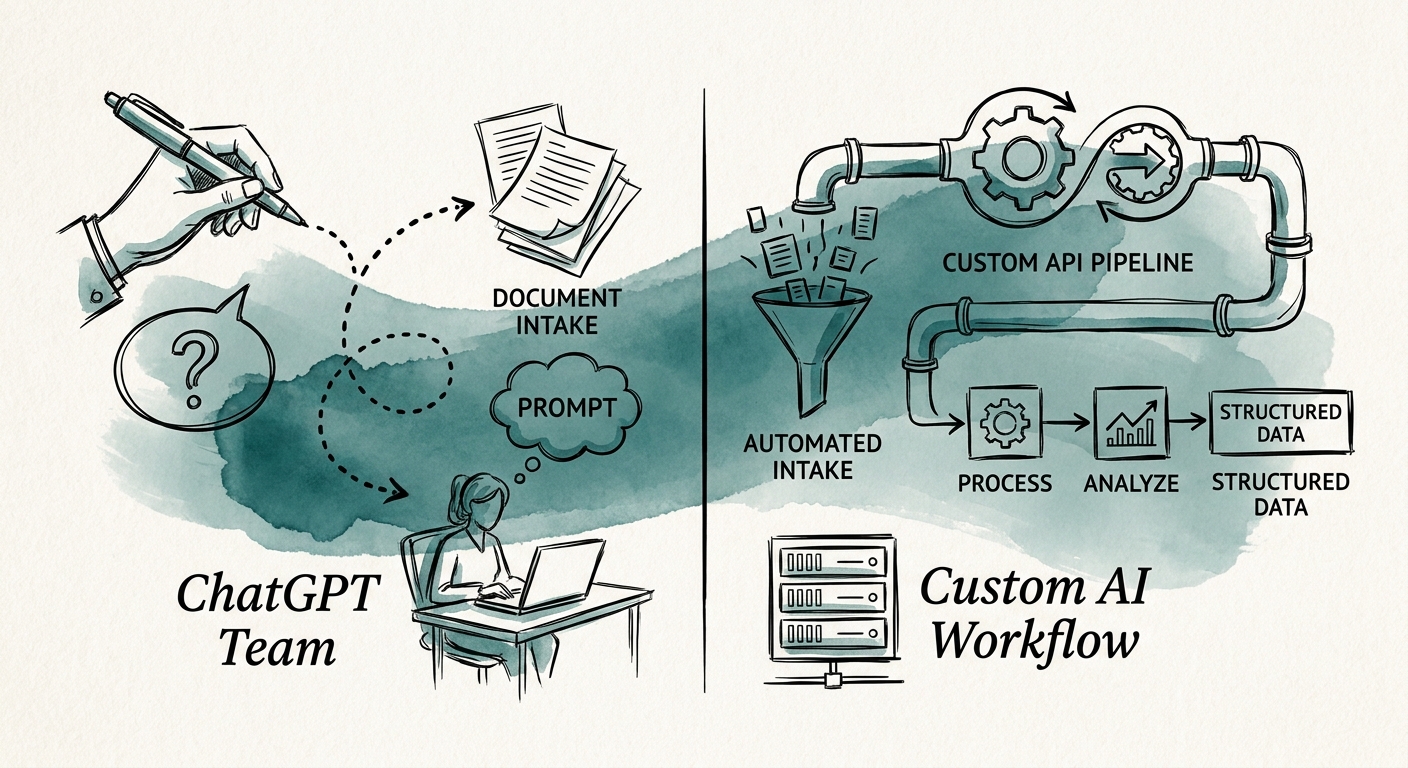
ChatGPT Business is genuinely good at the first half. It will read a PDF, explain a clause, summarize a contract, compare two versions of terms. For a trained employee handling a handful of approved documents, that is a real productivity gain, and the broader research on smaller-company AI adoption from RSM, the San Francisco Fed, and the OECD backs that up. But intake is not "reading." Intake is a chain: upload, OCR, extract fields, classify the document type, validate against policy, route exceptions to a human, post to the system of record, and retain the evidence. A chat window does step three brilliantly and pretends the other seven don't exist.
Confidence is the field your chat thread is missing
Here's the test that splits the two options. Take any extracted field — the invoice total, the contract renewal date, the vendor tax ID — and ask how sure the system was, and what happened when it wasn't sure. ChatGPT Business answers with confidence-flat prose. It says "$1,480.00" with the same fluent certainty whether the digits were crisp or smudged, and your data-boundary review still has to decide which documents are even allowed in the workspace. A custom intake workflow does the opposite: it attaches a confidence score to each field, links back to the exact source page, and refuses to post when the number is shaky.
Concretely, a built workflow should hard-stop and queue a human when a required field is blank, when the vendor isn't in your master list, when a contract term contradicts your policy, or when the destination system is ambiguous. It keeps the original file, the extracted values, the confidence, the reviewer's edits, the posting target, and the retention rule together — so the duplicate-invoice question has an answer instead of a shrug. The NIST AI Risk Management Framework gives you the language for naming intended use and monitoring extraction error rates, and because intake documents are stuffed with vendor banking details, customer PII, and employee data, the CISA AI data-security guidance applies directly to what you let touch a shared chat workspace.
What most teams get wrong is scoring the pilot on summary quality — "wow, it understood the contract." That is the wrong scoreboard for intake. The right questions: can the AP lead challenge a posted value and trace it to a source page in under a minute? Does an unrecognized vendor stop the line instead of sailing through? Is every posting logged well enough that a controller can audit it three months later without opening a single email thread? If the answers are no, you don't have a workflow. You have a faster way to make confident mistakes.

Let the exception queue tell you whether to build
You don't need a strategy deck to make this call. You need one number: how many documents of one type flow in per week, and how many currently need a human to fix something. If a clerk processes 30 invoices a month and 3 are weird, stay in ChatGPT Business — the manual keying is cheap and the build isn't worth it. If you're posting 400 invoices a week and reviewers spend their mornings hunting for the source page behind a wrong total, the exception queue is screaming for a governed workflow. Deloitte's State of AI in the Enterprise 2026 keeps reinforcing the same point: value shows up as shrinking exception queues and falling posting errors, not as demo applause.
Track six things on the document family that hurts most: per-field extraction accuracy, exception rate, reviewer correction time, posting delay, duplicate-intake count, and how long an audit retrieval takes. Those numbers are the build justification — or the proof you don't need one yet.
Start narrow on purpose: one document type, one destination system. Use the document-intake automation guide to define the upload-to-posting handoff, then run it inside a staged 90-day plan so you prove extraction, review, posting, and retention on invoices before anyone touches contracts or applications. Write the decision down — kept in ChatGPT Business, built as a workflow, or paused for vendor-master cleanup — and tie it to exception rate and correction time, not to how impressed someone was in the demo.
