The note that says "timing" when it means "we missed"
Every controller at a 50-300 person company knows the Day 4 ritual. Marketing spend is $63K over budget. The owner of the line types back: "timing — Q3 campaign pulled forward." It goes in the close package. The CFO reads it, nods, moves on. Three months later the campaign was real but the overage was permanent, and now the forecast is wrong because nobody re-checked the word "timing." That single mislabeled variance is the actual cost center here — not the typing time.
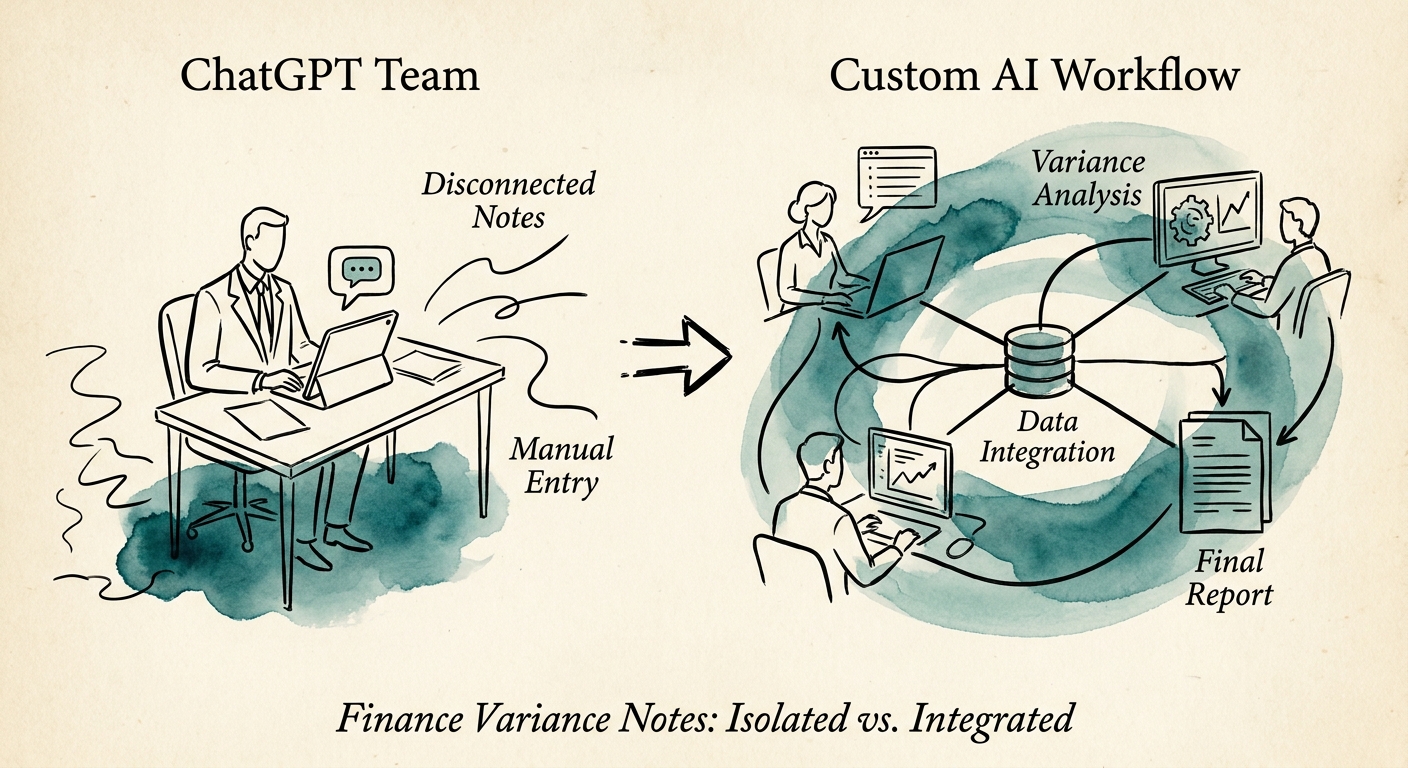
So when someone asks whether finance variance notes should live in ChatGPT Business or a custom-built workflow, the honest answer starts with a different question: what does your AI tool know about the variance besides the dollar amount? ChatGPT Business will happily turn "Marketing +$63K vs budget" into three polished sentences. It does not know that the same line was flagged as "timing" last quarter and never trued up. It cannot see that the budget baseline it's comparing against was the original board version, not the reforecast finance has been using internally since March.
That gap is the whole decision. Broad adoption surveys from RSM, the San Francisco Fed, and the OECD tell you mid-market finance teams are adopting AI fast. None of them tell you which budget version your variance note should compare against. In a finance close, that detail is not a footnote — it is the difference between a note that prevents a forecast miss and a note that launders one.
The drafting is the easy 20%. The 80% is the join.
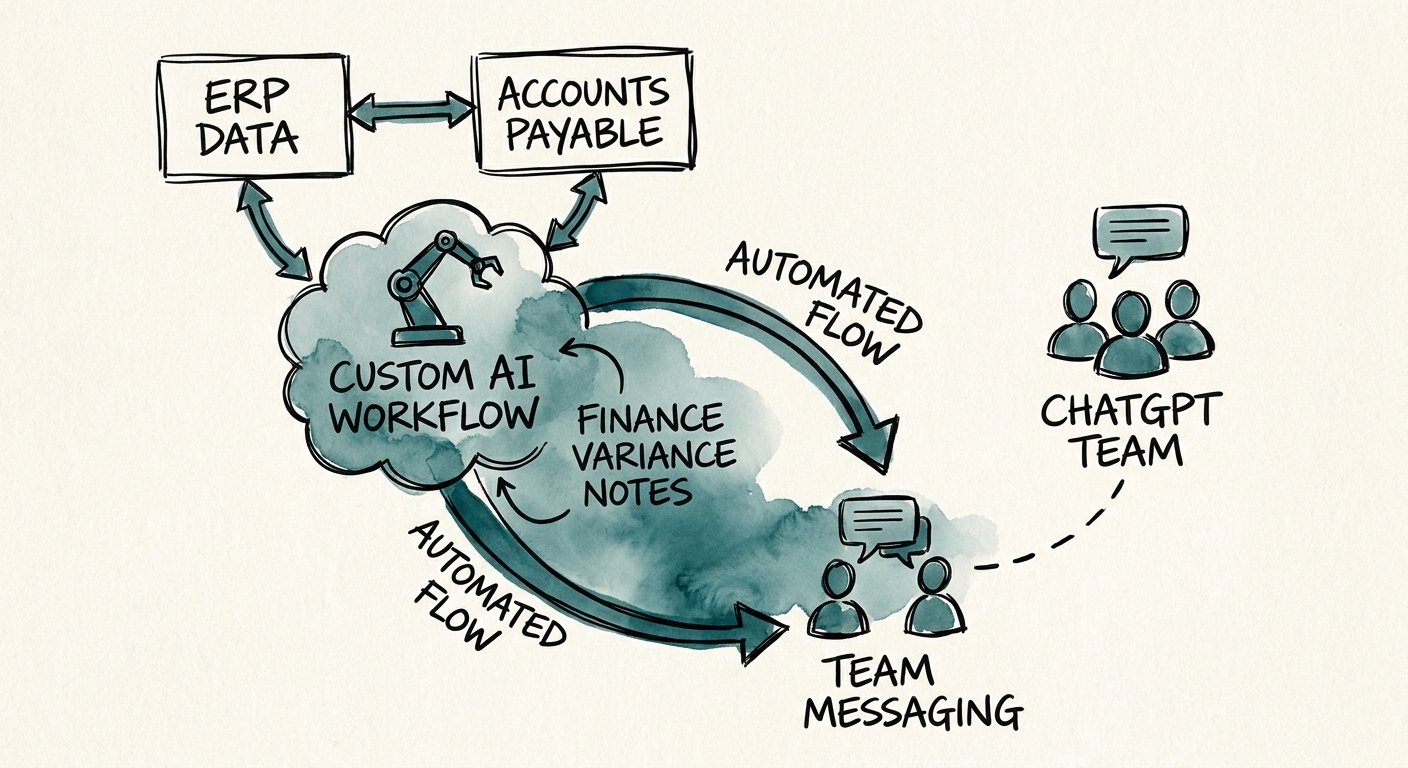
Picture the actual data path behind one variance line. You need the GL actual (from the close trial balance), the budget baseline (which version?), the current reforecast (different system, often a spreadsheet), the line owner (a person, by department), last period's commentary on the same account (was it "timing"?), and the reviewer's sign-off state. ChatGPT Business is genuinely good at the last step — turning a verified row into board-ready prose, or rewording a department head's terse Slack reply into something a director will read. That is real time saved, and you should use it there. OpenAI's enterprise privacy terms belong in your data-handling review before any GL data goes near it.
But the polish is maybe a fifth of the work. The other four-fifths is the join: pulling the right budget version, matching the GL account to a named owner, surfacing what that owner said about this account three closes ago, and refusing to call a note "complete" until a human has confirmed timing-vs-permanent. That logic does not live in a chat thread. It is a workflow with rules. Here is the test I give finance teams: if your variance note answers "how much" but a built process is the only thing that can answer "is this the same problem we explained last quarter," you have outgrown the chat box.
When you do build, scope the control layer first, not the model. NIST's AI Risk Management Framework gives you the map — intended use, measurement, and accountability — and CISA's AI data-security guidance tells you how to gate access to the GL, vendor exposure, and customer-revenue detail that lives inside these notes. The non-negotiable rule: an AI-drafted explanation is a draft until a named reviewer marks it reviewed. It never becomes management fact on its own, and the owner of every line can see — and challenge — the words attributed to them.
Run the math on rework, not typing
Deloitte's State of AI in the Enterprise 2026 keeps pointing at the same thing: value shows up in production, not pilots. For variance work, "production value" is concrete and you can measure it this close. Track four numbers across the next three closes: hours from "variance flagged" to "owner responded," the count of notes rewritten after the controller's review, how often a prior-period "timing" note had to be reversed, and how late the reforecast lands because commentary was still in flight. Those are your real costs. Typing speed is not on the list.
Then decide by volume and repeat-rate. If you have a dozen material variances a month and they are different every time, stay in ChatGPT Business — building a workflow for that is over-engineering. If the same fifteen accounts blow through threshold every single close and you need an audit trail that survives the year-end review, build the workflow. Start narrow: pick one threshold band (say, lines over $25K and 10%) or one department's variances, run it for two closes, and compare against the numbers above. Use the finance variance ROI lens or the AI ROI Calculator to put close-cycle hours and rework against the build cost honestly.
Write the decision down in one sentence a CFO would sign: "We kept variance notes in ChatGPT Business / built a workflow / paused to fix the budget-version problem first, because owner-response time and post-review rework showed X." If you cannot fill in the X with a real number, you are not ready to scale either way — and the next move is one department, not a finance-wide rollout. Want help scoping which variances justify a build? Build the AI roadmap starts exactly there.
