
The practical answer
- Short answer
- Why 78% of Splunk implementations fail to deliver ROI despite successful 'go-lives.' A diagnostic guide for PE operating partners and scaling COOs on fixing the 'Ingestion Trap.'
- Best fit
- Industry: Enterprise Software / Cybersecurity. Function: Customer Success / Professional Services
- Operating path
- Process Documentation → Operational Excellence → Transaction Execution Services
- Key metric
- 55% False positive rate in average SIEM environments, driving 'alert fatigue' and user abandonment.
The 'Go-Live' Lie in Observability
In the world of enterprise log management and SIEM, 'deployment' is a vanity metric. For Splunk partners and internal COOs alike, the most dangerous moment in a project lifecycle is the 'Go-Live' party. The agents are deployed, the indexers are spinning, and terabytes of data are flowing into the platform. On paper, the project is a success. In reality, you have likely just built a very expensive digital landfill.
Recent data reveals a significant gap between implementation and value: while 83% of organizations prioritize turning data into actionable insight, only 22% believe they are successful at it. This 'Insight Gap' is where retention dies. In the 2026 Cisco-Splunk ecosystem, where outcomes are scrutinized more heavily than volume, a Splunk implementation that merely 'collects' data is a failed implementation.
The symptom of this failure is rarely silence; it is noise. 59% of security teams report drowning in alerts, with 55% of those being false positives. When a Splunk environment is treated as a dumping ground for every log source without a corresponding use case strategy, the platform shifts from a 'Single Pane of Glass' to a 'Pane of Glass You Can’t See Through.' For PE operating partners evaluating a portfolio company's technical stack, a high Splunk bill coupled with high Mean Time to Resolution (MTTR) is a primary indicator of operational rot.
Shelfware is not just software you don't install; it's data you pay to store but never query. In the consumption economy, 'ingestion without insight' is a churn indicator.
The 'Ingestion Trap': Why More Data Equals Less Value
The root cause of Splunk project failure is almost always the 'Ingestion Trap.' Historically, legacy partner incentives were aligned with data volume—the more data a customer ingested, the larger the license, and often, the larger the managed service fee. This created a perverse incentive structure where 'success' was measured in gigabytes per day (GB/day) rather than questions answered per day.
This volume-first approach creates massive technical debt. Our diagnostic work across distressed technical implementations shows that 50% of SIEM detection rule failures are caused by log collection issues—specifically, poor parsing, incorrect sourcetypes, and lack of normalization. When data is ingested without structure (the 'lazy parsing' model), it becomes unsearchable at scale. The CPU cost to query it skyrockets, search performance tanks, and users stop logging in.
For a scaling services firm, this is an EBITDA killer. If your Customer Success team is constantly fighting 'performance fires' caused by bad data hygiene, you are eroding gross margins on your managed services contracts. You aren't delivering 'Observability'; you are delivering 'Storage Management.' The partners trading at premium multiples in 2026 have pivoted. They don't sell ingestion; they sell 'Business Resilience' and 'outcome-based' monitoring, decoupling their value from the raw volume of logs.
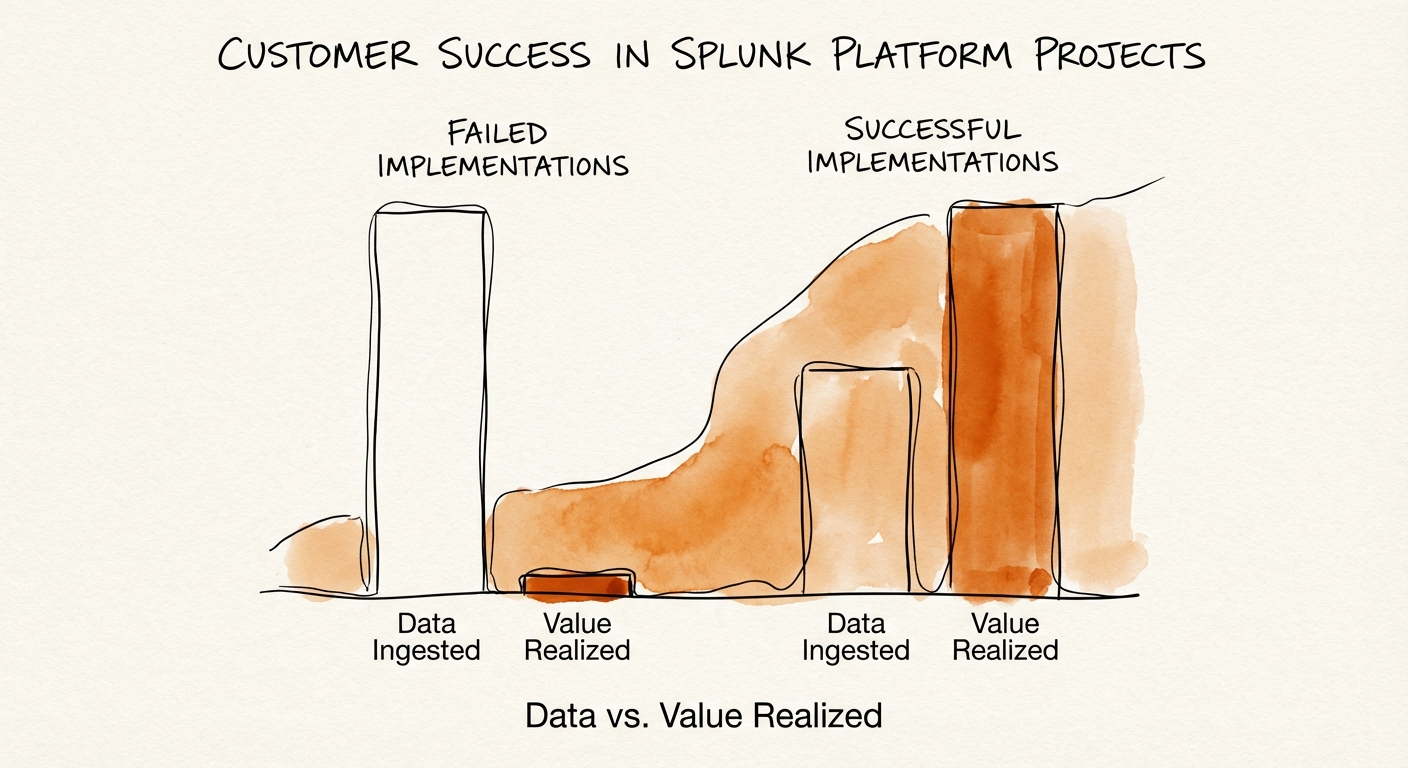
Escaping the Trap: The Outcome-Based Delivery Model
Recovering a stalled Splunk project requires a hard pivot from 'Implementation' to 'Adoption.' This is not about training users on Search Processing Language (SPL); it is about reverse-engineering the data pipeline from the business question backward. Effective Customer Success in complex platforms demands a 'Use Case First' methodology.
1. Audit the 'Quiet' Logs
Identify data sources that account for high ingestion volume but zero search activity. Shelfware is not just software you don't install; it's data you pay to store but never query. Rigorously archive or route these to lower-cost storage tiers.
2. Measure 'Time to Insight,' Not 'Uptime'
Stop reporting on system health in your QBRs. Start reporting on 'Threats Blocked,' 'Downtime Avoided,' and 'Development Cycles Saved.' With downtime costing Global 2000 firms an estimated $400B annually, your CS narrative must be financial, not technical.
3. The Cisco 360 Pivot
With the integration of the Cisco 360 Partner Program, the market is bifurcating. 'Resellers' who simply transact licenses will see margins compress. 'Specialists' who can bridge the gap between network observability and security operations will command the premium. Your CS team is the engine of this transition—they must stop being 'support reps' and start being 'value architects.'







