It started with a vendor's "minor" version bump
Picture a 90-person software company on a Tuesday morning. A SaaS vendor pushed a point release over the weekend, quietly renamed a field in their webhook payload, and now the billing sync is silently dropping line items. Support tickets pile up. The engineer who wrote that connector left eight months ago. By noon the on-call lead is grepping logs they've never seen, and three other integrations are flapping because they all chained off the same expired OAuth token nobody knew was shared.
This is what "API breakage" actually looks like, and it is almost never one bad connector. It is weak ownership spread across authentication, schema changes, monitoring, and vendor release cadence — four things that each have a different person responsible, or worse, nobody. The MuleSoft Connectivity Benchmark report is worth reading here precisely because it treats connectivity as a business-wide condition, not a ticket queue. When integrations are brittle, the cost shows up as stalled launches and firefighting, not as a line item called "API."
The stakes climbed the moment your company started shipping AI features. A copilot, a RAG system, an automated workflow — all of them are downstream of the same data plumbing. If customer, product, and billing data can't move reliably, the model inherits stale or contradictory context and produces confidently wrong answers. Deloitte's State of AI in the Enterprise 2026 ties production AI to operating readiness, and integration reliability is a quiet, load-bearing part of that readiness. You can't bolt intelligence onto plumbing you don't trust.
Stop the bleeding before you redesign anything
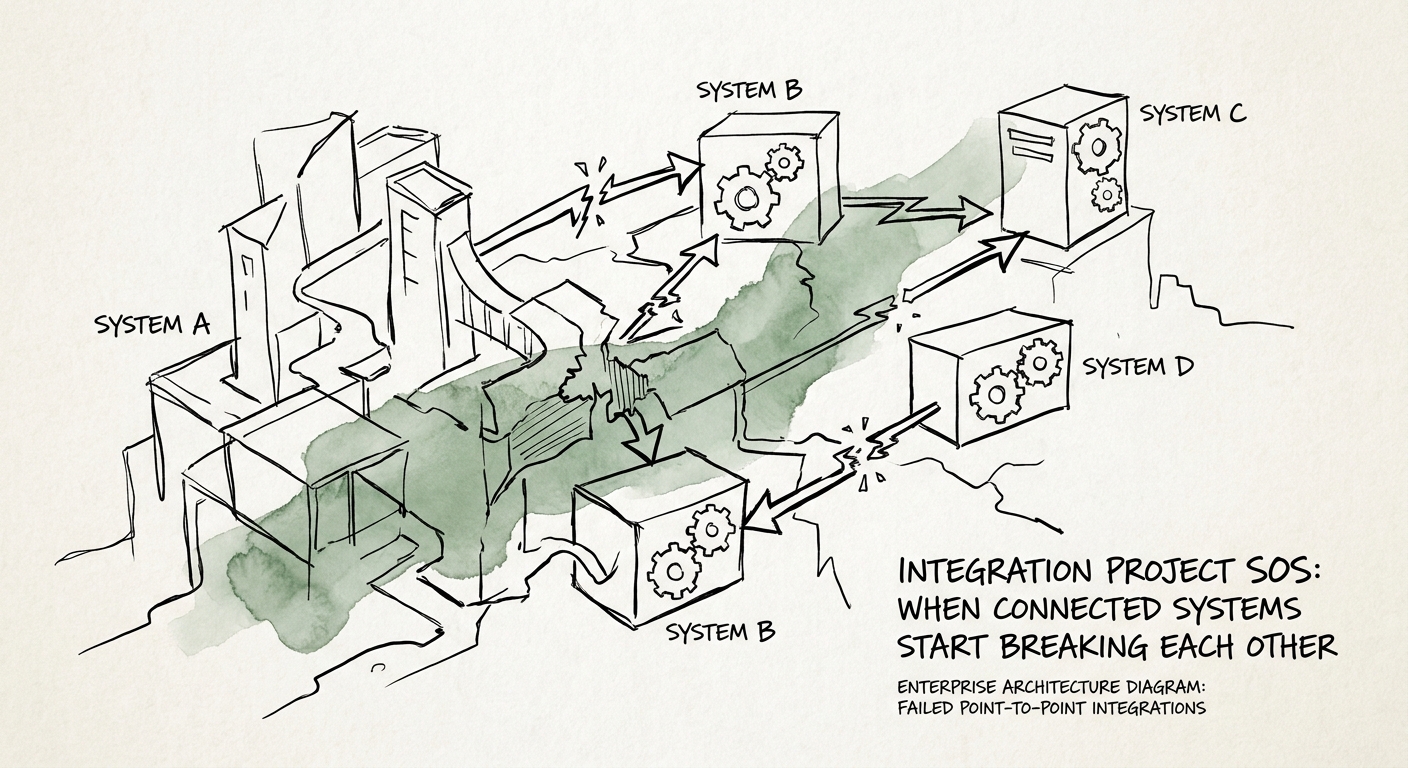
The reflex is to rip out the bad integration and rebuild it "properly." Resist that for one day. The fastest path out of a breakage spiral is a current integration map — one row per connection — with five columns filled in: who owns the system, who owns the data, how it authenticates, how it fails, and what business process dies when it does. Most teams in this situation discover they have forty-some connections and can confidently fill in all five columns for maybe a third of them. That gap is the actual problem.
Once the map exists, hunt for three specific failure patterns. Authentication drift: tokens, keys, and service accounts that rotate, expire, or get shared across flows with no alerting — the most common cause of the "everything broke at once" morning. Schema drift: a vendor or internal team changing a field shape without a contract or a consumer-side test catching it. Ownership drift: the connector whose author left, whose runbook never existed, whose Slack channel went quiet. Tag every row on your map with which drift it's exposed to. While you do this, keep the OWASP API Security project open beside you so that authorization gaps and exposed endpoints surface in the same pass — a breakage audit and a security audit cover the same surface, so do them together.
Only after the map is honest do you move critical flows behind a control plane: a gateway that centralizes auth, an event queue that decouples producers from consumers so one slow vendor can't cascade, monitoring that pages before customers notice, and a documented owner per flow. That's the first milestone — not zero incidents, but a control plane where the next vendor surprise degrades one queue instead of taking down four systems. If you want the architecture reasoning behind centralizing versus federating connections, the API federation playbook goes deeper on that tradeoff.
Recovery that survives a diligence room
If you're venture- or PE-backed, or anywhere near a sale, fixing the breakage isn't the finish line — proving you fixed it is. A technical buyer's diligence team will ask for exactly four artifacts, and a flailing integration shop can produce none of them: a current architecture diagram, monitoring and uptime records, an incident history with root causes, and a named owner per critical flow. Generate those as the byproduct of the recovery, not as a scramble two weeks before a data room opens. The map you built in the second step is your architecture diagram. The control plane is your monitoring story. The drift tags are your root-cause history.
Treat new and rebuilt connectors as products, not glue. CISA's Secure by Design guidance increasingly sets the expectation buyers apply to connected software: authentication, logging, and failure handling designed in from the start, not patched after the first incident. A connector that meets that bar reads as engineering maturity in diligence; one that doesn't reads as deferred risk and gets discounted.
Here's what to do Monday: pull every team that owns a third-party or internal API into one room and build the five-column map live, on a screen, no homework. You'll finish the meeting knowing your real connection count, your unowned flows, and which of the three drifts is most likely to wreck your next Tuesday. If the map exposes more than you can stabilize in-house, talk through the recovery plan with us — that conversation starts with your map, not a pitch.
