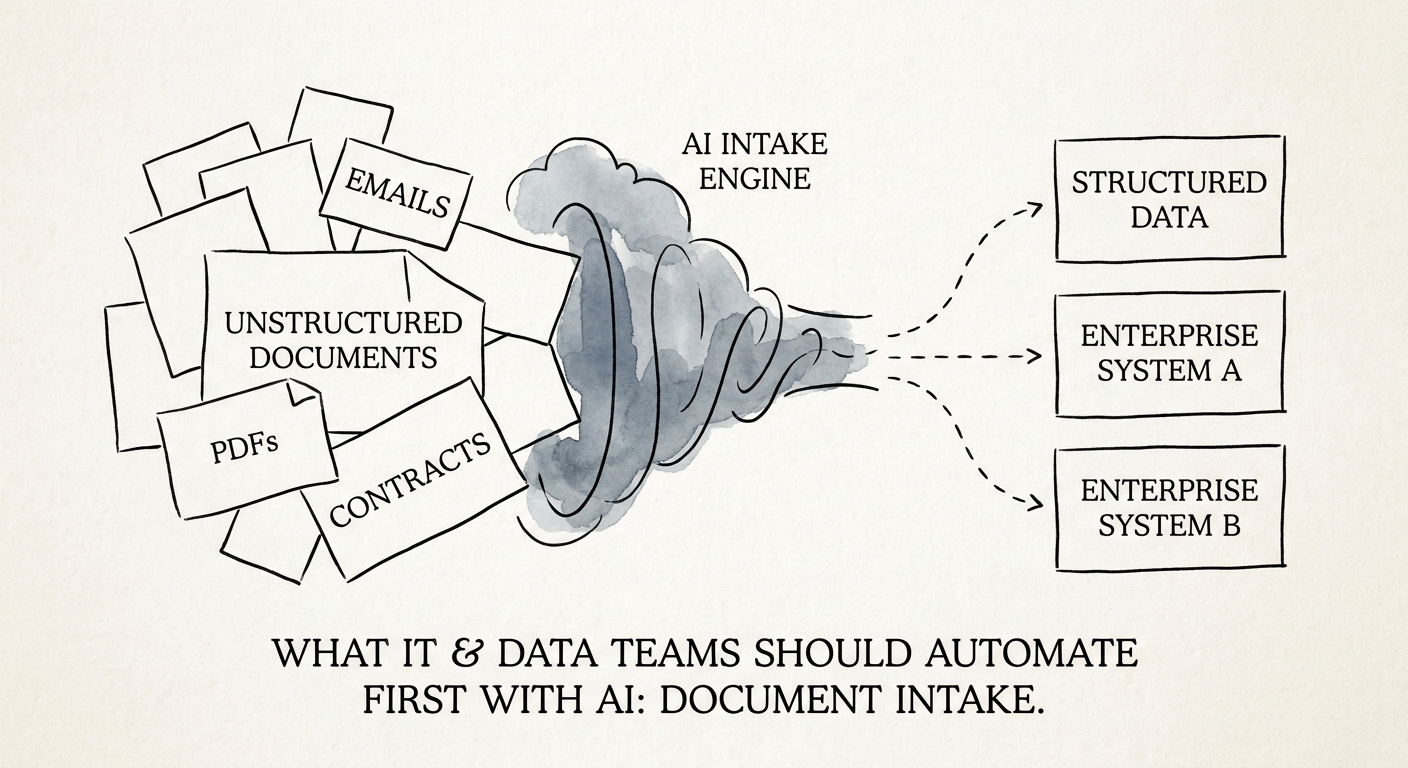
The shared drive is the real backlog
Walk into most mid-market IT shops and the AI conversation is about chatbots and ticket deflection. Meanwhile, two seats over, someone is opening a vendor's emailed PDF, squinting at which version is current, and hand-keying a renewal date into a spreadsheet they will email to three people. That second job, the unglamorous intake of documents that arrive in fifteen formats from people who do not work for you, is the one AI is actually good at right now, and the one nobody volunteers as a pilot.
Pick one class and only one: vendor packets, inbound security questionnaires, signed order forms, or onboarding paperwork. Not "documents" in general. The reason to constrain it is that each class has its own truth: a security questionnaire has required fields a customer expects filled, an order form has a number that has to reconcile to a CRM, an onboarding packet has a missing-signature problem. The U.S. Census AI business adoption data and the Deloitte State of AI in the Enterprise 2026 both show the adoption pressure landing squarely on the teams that already own document-heavy plumbing. That pressure does not tell you which class to start with. The shape of the work does.
Classify and route before you ever extract
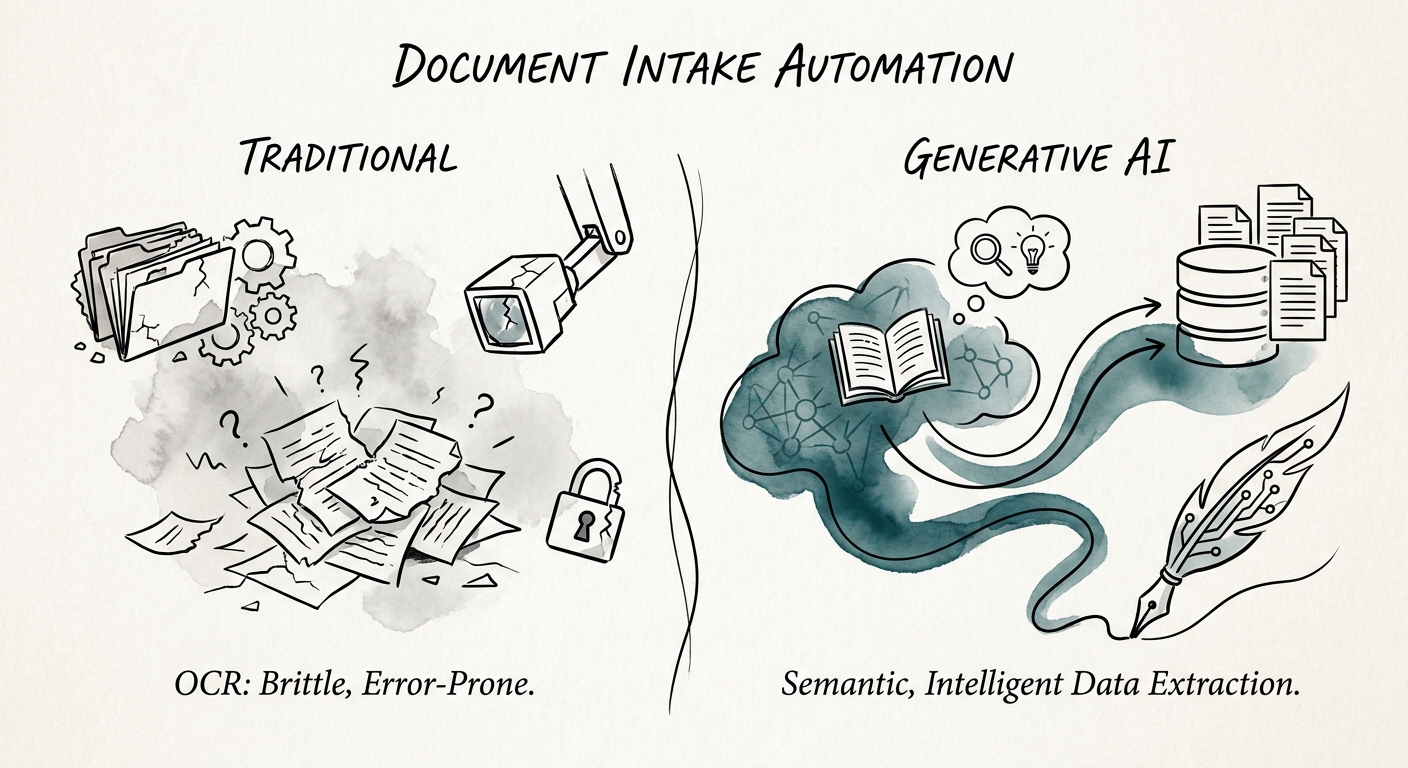
Here is where IT teams, who are wired to chase the impressive demo, get it backwards. The hard part of document intake is not pulling a value out of a PDF. Modern models do that fine. The hard part is the model confidently extracting a renewal date from a document that turns out to be last year's contract, or pulling fields from a file that should never have been routed to that pipeline because it contained someone's PII. The classification and routing layer is the product. Extraction is the easy mile.
So sequence the build that way. First, can the system reliably say "this is a current vendor MSA" versus "this is an expired draft" versus "this is something I don't recognize, send it to a human"? Only once that gate holds do you turn on field extraction. And every extraction needs a confidence floor: above it, route forward; below it, kick to a named reviewer's queue with the source file attached. Say a 60-person company processes 200 inbound documents a week. If the model auto-handles the 150 it is sure about and routes the 50 ambiguous ones to a person, you have not removed the human, you have stopped making them the first-pass sorter. Measure four things weekly: classification accuracy, missing-field catch rate, reviewer minutes per document, and the count of files the system correctly refused to process. If accuracy is high but the refusal count is zero, the model is not being honest about what it does not know. Run the AI Opportunity Score or the AI ROI Calculator only after those four numbers have an owner and a baseline.
Permissions are the load-bearing wall
An IT team has one advantage on this project that a marketing or sales team building the same pilot does not: you already own access control, and you already know that the document pile is full of files some employees should never see. Use that. The NIST AI Risk Management Framework gives you the structure to write down intended use, who is accountable, and how you measure whether it works before you scale anything. The CISA AI data-security guidance tells you the part teams skip: the intake system inherits whatever permission sloppiness already exists in the source folders. If a contracts share is readable by everyone because nobody cleaned it up, your shiny new pipeline now reads it too, and so does anyone who queries downstream.
So on Monday, do this in order: classify document type before any model touches the content, scope source access by document class so the intake job only sees what it should, set the confidence threshold, and hold incomplete or low-confidence files in human review instead of forcing a guess. Add the next document class only after the current one runs a full month without a misroute. The intake model should never be able to reach further than your access design lets it. When you're ready to map which class to automate after this first one earns its keep, that sequencing is what the AI roadmap is for.
