The 2 a.m. handoff is where your margin leaks
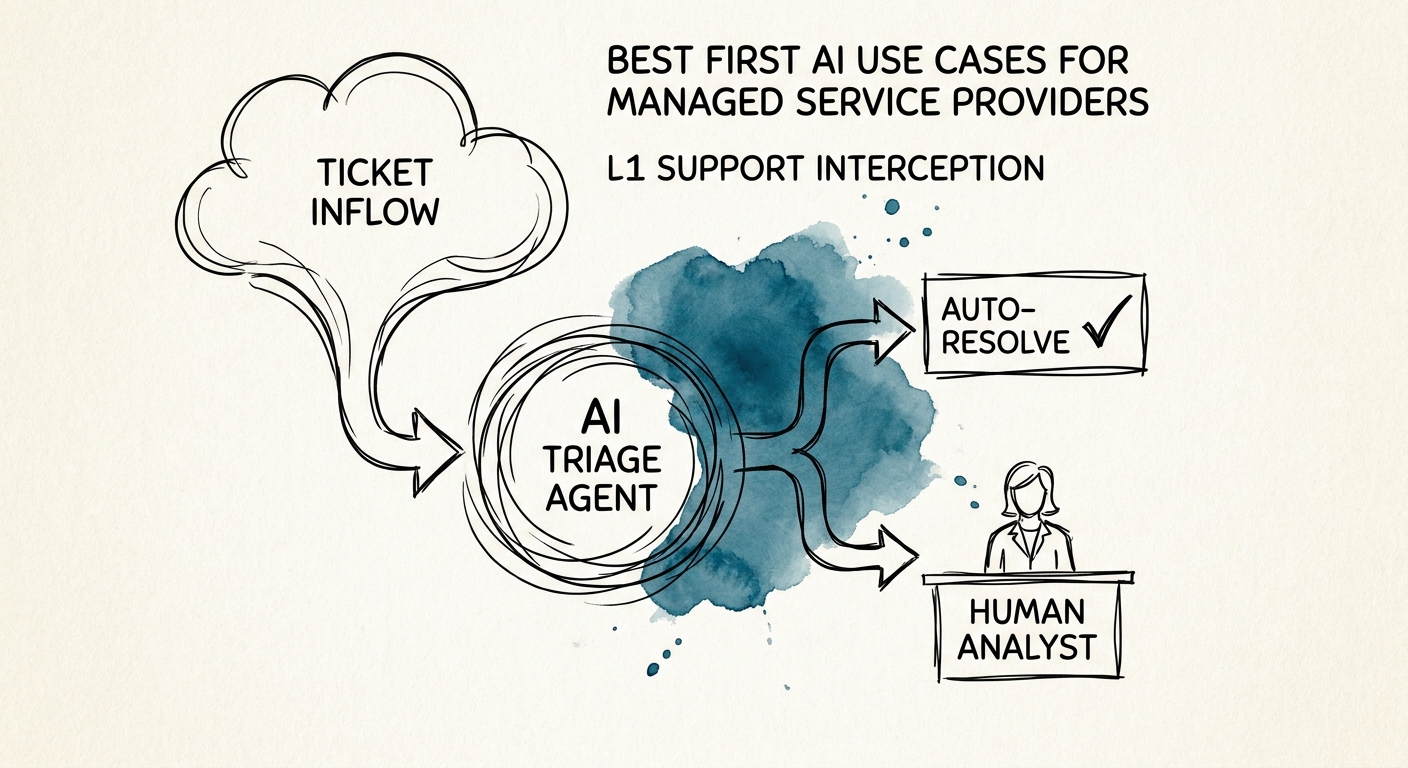
Picture a 35-person MSP on a Tuesday night. A monitoring alert fires for a client's domain controller. L1 acknowledges it, pokes around for twenty minutes, can't resolve it, and escalates. The L2 engineer who picks it up gets a ticket that says, roughly, "DC alert, escalating." So they start over: read the alert, check which client this is, remember whether that client has the weird hybrid AD setup, hunt for the runbook, and ask the customer questions L1 already asked. Forty minutes gone before any real diagnosis begins.
That re-discovery tax is the single most expensive thing in a managed service business, and it's invisible in your P&L because it shows up as "engineers are busy," not as a line item. So when MSP leaders ask where to point AI first, the honest answer isn't "build a chatbot for clients." It's: close the context gap between the person who acknowledges a ticket and the person who resolves it.
The five workflows worth shipping first are narrow and internal: alert triage that clusters noise into a single actionable signal, ticket summarization for clean handoffs, knowledge retrieval scoped to the right client, customer-facing report drafting, and escalation-packet preparation. None of them touch a client commitment without an engineer in the loop. The discipline here — start with a governed internal workflow before anything autonomous reaches a customer — is exactly what the operating-model research from McKinsey, IBM, and PwC keeps landing on: value comes from changing how work flows, not from bolting a model onto the front door.
The escalation packet is the use case that pays for the rest
If you ship only one thing, ship this. When a ticket escalates, an AI workflow assembles a packet before the L2 engineer opens it: a plain-language summary of what's happened, the cluster of related alerts from the same device or client, the matching runbook section, what L1 already tried, and — critically — a list of what's still unknown ("no confirmation whether the last patch window completed"). The engineer opens one screen instead of seven tabs.
The reason MSPs are an unusually good fit for this is also the reason it's hard: every client is a different environment. The retrieval layer has to be scoped to the right tenant, or you'll surface Client A's firewall exception while someone is working Client B's outage. So two rules are non-negotiable from day one. First, every claim in the packet shows its source link and a confidence signal — the engineer can see exactly which runbook, which prior ticket, which alert. Second, the workflow drafts and prepares; it does not close tickets, send client emails, change SLA commitments, or execute remediation. It hands a senior human a head start, not a decision.
Get the scoping wrong and you don't just produce a useless packet — you erode the one thing that makes engineers adopt the tool, which is trust that it isn't confidently mixing up clients. Treat per-client retrieval boundaries as a hard requirement, the same way you'd treat tenant isolation in any tool that touches multiple customers' data. When you're ready to wire these governed flows across support, delivery, and reporting, that's the work behind AI for Technology Services.
Measure it like an SLA, then expand one client at a time
Don't measure this with "engineer satisfaction." Measure it with the numbers your service-delivery review already tracks. Time-to-classify on inbound alerts. Reopen rate — the truest signal that handoffs are losing context. Mean time to escalate versus mean time to resolve after escalation (the packet should compress the second number). Repeat questions to the customer per ticket. Customer-report turnaround. And the honest counter-metric: how much time engineers spend reviewing or correcting AI output, because if that's climbing, the tool is creating work, not removing it.
Roll it out the way you'd onboard a new client — narrow and provable. Pick one alert category (say, backup-job failures) or one client tenant, run the escalation-packet workflow there for a few weeks, and watch the reopen rate and post-escalation resolution time. Expand only when L2 engineers stop double-checking every source link because they've learned the citations hold up. Bain's 2025 work on agentic transformation and the NIST AI Risk Management Framework both make the same point in different vocabularies: scope tightly, keep evidence visible, and earn the right to widen.
Two next steps. If you want to pressure-test which of your workflows is the best first candidate, run it through the AI Opportunity Score. If you want to put a dollar figure on the re-discovery tax — engineer hours times loaded rate times your monthly escalation volume — model it with the AI ROI Calculator before you commit a sprint to it. For the customer-facing layer once the internal flow is trusted, see Customer Service AI.
