The 2023 handbook is still in SharePoint, and Copilot can read it
Here is the failure that should keep an HR director up at night. An employee in your Austin office types "how much PTO carries over into next year?" into Microsoft 365 Copilot. Copilot searches the files that employee can see, finds three documents — the current handbook, last year's handbook nobody deleted, and a benefits deck from a 2023 all-hands — and synthesizes a fluent, well-formatted answer. It cites the 2023 deck. The carryover cap changed in January. The employee plans around the wrong number, and nobody finds out until the dispute.
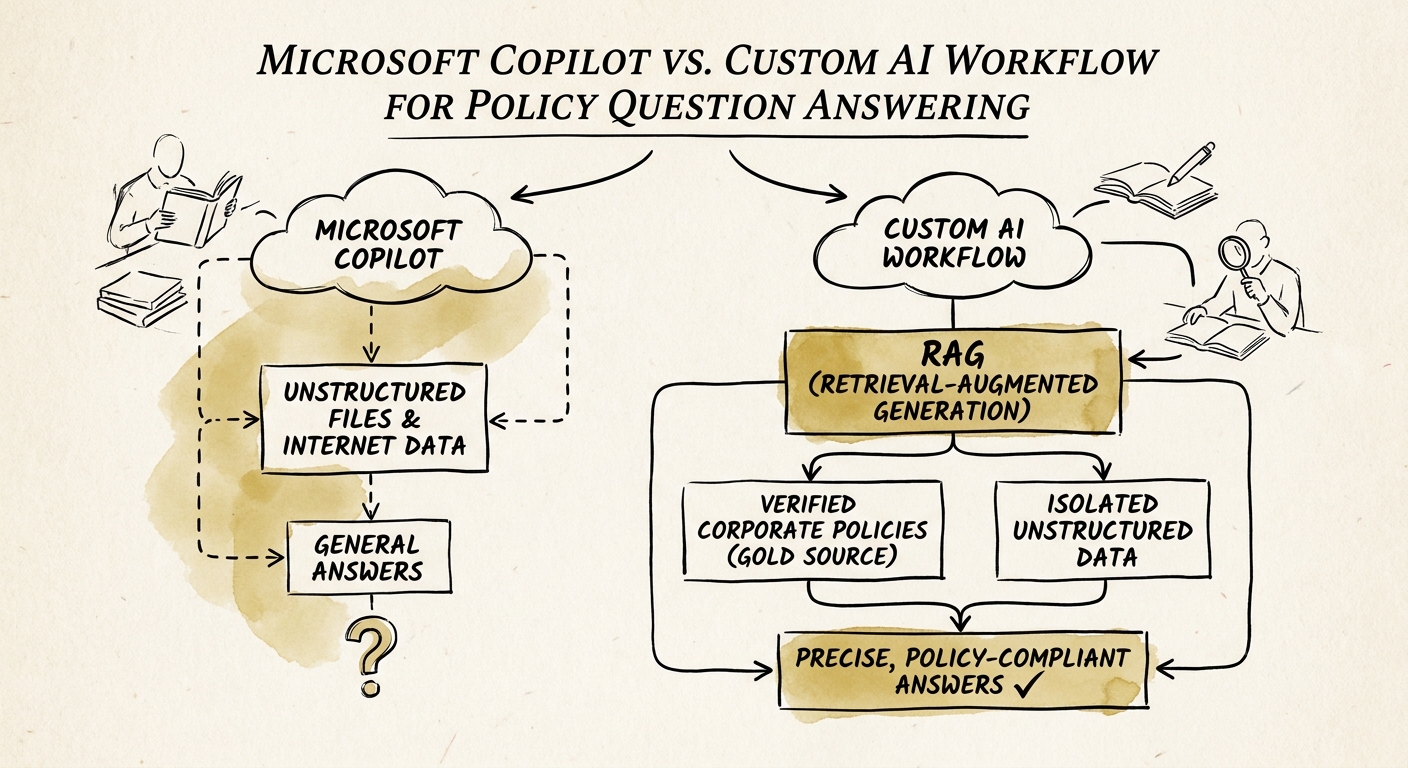
That is the whole problem with treating Copilot as a policy answer engine: it is excellent at reading what is in your tenant and terrible at knowing which version is the law. Microsoft's own architecture documentation is clear that Copilot grounds answers in Microsoft Graph content the user already has permission to access. That is a security feature and a content-freshness liability at the same time — it will faithfully retrieve a stale, superseded, or draft policy if that file is sitting in a folder the employee can open.
For policy questions specifically, the answer is only as trustworthy as your document hygiene, and most 50-300 person companies have a decade of orphaned PDFs, an HR drive, a "Policies (Final) (v2) (USE THIS ONE)" folder, and three jurisdictions' worth of leave rules in one place. OECD research on SME AI adoption keeps landing on the same point: the technology is rarely the constraint — organizational readiness is. For policy Q&A, readiness means you can name, today, which library is authoritative and which versions are retired. If you cannot, no chatbot fixes that.
Where the line actually falls: who is asking and who is accountable
The clean way to draw the boundary is not "Copilot vs. custom." It is "research vs. ruling." Those are different jobs with different risk profiles, and they map onto two different tools.
Copilot is the right tool for the people who own the policy. An HR generalist asking "summarize what changed in the updated parental leave policy versus the prior version" or "draft a Slack announcement explaining the new expense limits" is doing research and drafting. They have the judgment to catch a stale citation, the permissions to see the source, and the accountability to verify before they send. Microsoft's privacy and data-protection documentation supports exactly this internal-assistant pattern — your prompts and tenant data stay inside your commercial boundary. For a four-person HR and legal team, this alone is worth the license.
A custom workflow becomes the right tool the moment a non-owner relies on the answer as if it were official. When 280 employees self-serve "can I expense my home internet?" and act on what comes back, you are no longer doing research — you are issuing rulings at scale, and you need controls Copilot does not give you out of the box: a single approved source set rather than "everything I can see," a version stamp and effective date on every answer, role and jurisdiction gating (the answer for a California exempt employee is not the answer for a Texas contractor), a disclaimer where legal requires one, and a hard escalation path to a human for anything touching termination, accommodation, or pay. The NIST AI Risk Management Framework gives you the vocabulary for the answer-risk side — what the system refuses to answer, how it flags low confidence, where it hands off — and CISA's AI data-security guidance covers keeping sensitive employee and policy data inside an approved retrieval boundary instead of whatever the file permissions happen to allow that week.
Pilot one policy area, and watch the escalation rate, not the demo
Policy bots demo beautifully. You ask about PTO, it answers cleanly, the room nods. Then someone asks about bereavement leave for a stepparent in a state with its own statute, and the thing either invents a confident answer or quietly contradicts the handbook. Deloitte's 2026 enterprise AI research documents this gap between pilot enthusiasm and production reliability across exactly these knowledge-work use cases — and policy answering is one of the least forgiving, because a wrong answer is not an annoyance, it is a legal exposure.
So scope the pilot to one bounded, high-volume, low-litigation area — PTO and expense approval are the usual best first picks, because the questions repeat and the stakes are bounded. Run it for the people who own the policy first, then a small employee group, before anyone announces it company-wide. And measure the metrics that actually predict trouble: citation accuracy (did it point to the current, effective version?), outdated-source rate (how often did it surface a retired document at all?), escalation rate and whether the escalations were correct (a bot that never escalates is more dangerous than one that escalates too much), and the HR and legal review burden the system creates versus removes. The RSM middle-market AI survey and the San Francisco Fed's analysis of AI and small businesses both point the same direction: the companies getting durable value are the ones that scoped narrow and proved control before scaling.
The Monday move is a one-hour audit, not a software purchase: open your policy library and find every superseded document an employee can still read. Until that list is empty, keep Copilot in the hands of HR and legal for research and drafting. Build the custom answer engine when — and only when — your standard for an employee-facing reply is "we can prove which version of which policy supported this answer, and where it got escalated." If you want help drawing that line for your own document set and tooling, that is the kind of decision a focused roadmap engagement is built to settle.
