Hand the same call to two reviewers and watch the scores split
In most support and delivery teams under 300 people, QA looks like this: a team lead pulls a handful of calls or tickets each week, listens with a spreadsheet rubric open, and fills in scores between other work. The problem isn't effort. It's that two reviewers scoring the same conversation will land points apart on "empathy," "set expectations correctly," or "followed the escalation path" — and the rep on the receiving end can feel it. When the score depends on who happened to review you that week, coaching loses its teeth.
AI gets pitched as the fix, and it can help — but be precise about which part of QA you're actually trying to repair. There are three distinct jobs hiding inside "QA review": deciding which interactions get reviewed (sampling), scoring them the same way every time (rubric consistency), and turning misses into coaching that sticks. Tools are good at different ones. San Francisco Fed research on AI and small businesses keeps landing on the same point: the constraint is usually capacity to operate the thing, not access to the model. So start narrow. One queue, one rubric, and a supervisor who agrees to read the first batch of AI-flagged misses and tell you which were wrong.
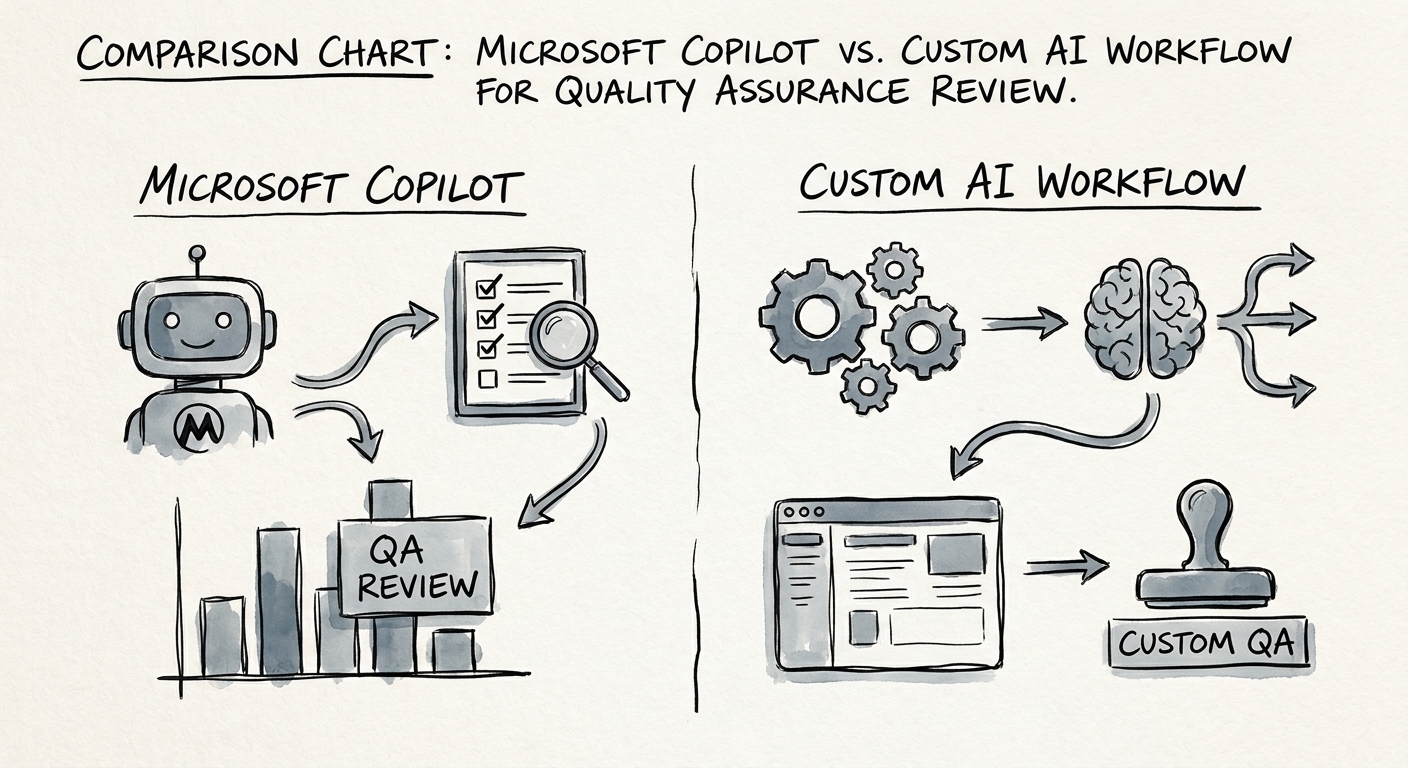
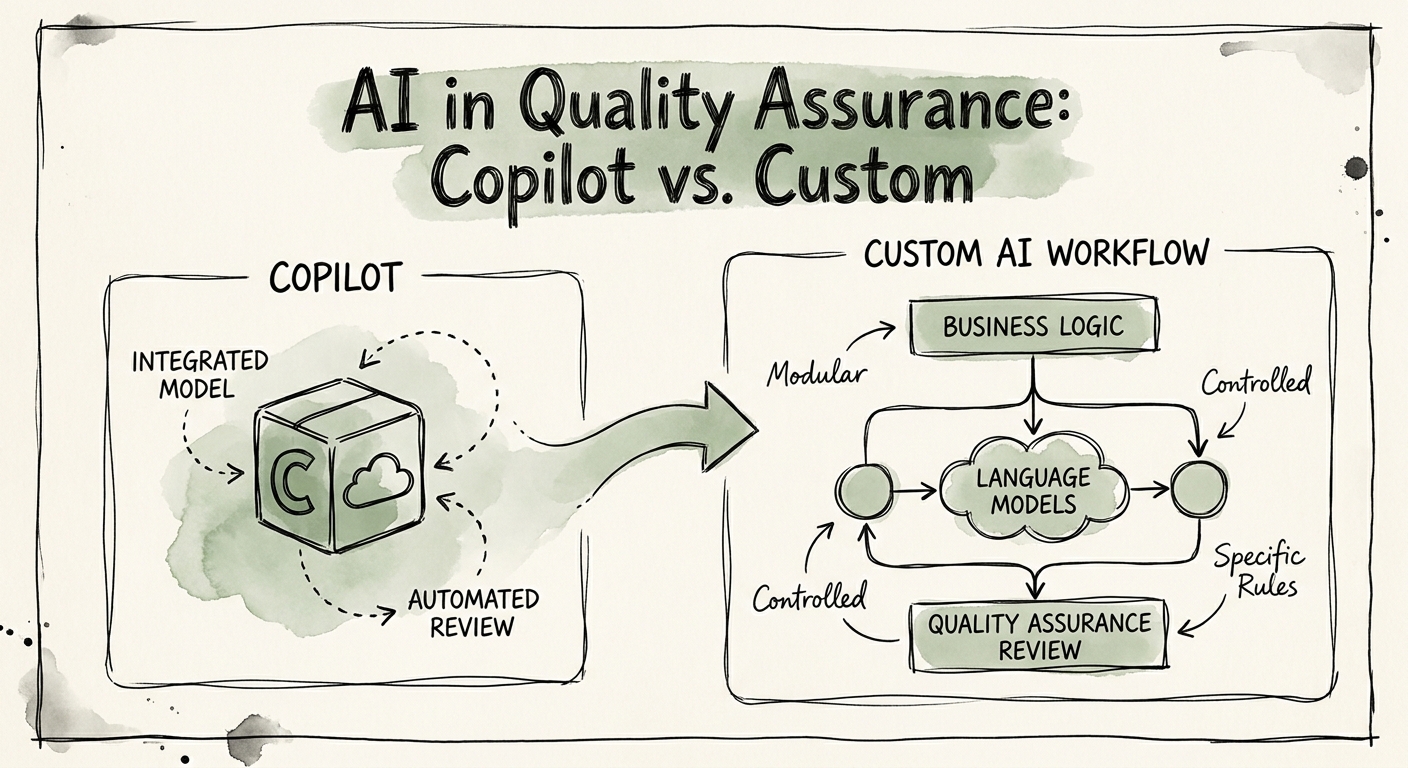
Copilot speeds up the reviewer. Custom AI runs the program.
Microsoft 365 Copilot is genuinely useful inside a QA seat — for the reviewer who has already decided which call to open. It can summarize a 22-minute call so the lead doesn't have to scrub the recording, surface the moment a customer's tone shifted, and draft the coaching note instead of leaving a reviewer to write the same three sentences forty times. That works when the source material lives where Copilot can see it, governed by Microsoft 365 permissions (the data path is laid out in Microsoft 365 Copilot privacy and data protection and Microsoft 365 Copilot architecture). It's a strong calibration aid. It is not a QA system.
What Copilot won't do on its own: pull a defensible sample across every rep instead of the calls a lead gravitates toward, apply the same rubric thresholds case after case so scores stop drifting, capture the exact transcript snippet that justifies each score, route low scores into a supervisor's review queue before they hit a rep's record, and roll the whole thing up into a trend that shows which rubric line is failing across the team. That's the custom-workflow territory — sampling logic, scoring with cited evidence, override queues, and integration with your support or delivery platform. Two controls are non-negotiable before any AI score touches a person's file: the monitoring and human-override requirements in the NIST AI Risk Management Framework, and the protection of recorded customer conversations and coaching records per CISA AI data security best practices. A wrong score that nobody can appeal is worse than no score.
Run a three-way bake-off on one calibration sample
Don't decide this in a meeting. Take the same 40 calls and score them three ways: a human reviewer alone, a reviewer using Copilot to summarize and draft, and a custom workflow that samples, scores against the rubric, and cites evidence. Then look at the numbers that actually matter for QA — not adoption vibes. Deloitte's State of AI report makes the uncomfortable point that pilots routinely look great and then don't survive production; the bake-off is how you find that out for $0 of committed spend.
Measure the few things QA lives or dies on: inter-rater agreement (do the AI score and a senior reviewer land within a point?), how many genuine customer-impact misses got caught that the old spreadsheet sample never would have, the false-positive rate a supervisor had to overturn, and whether coaching notes actually got written and acted on. Then decide cleanly. If reviewers mostly need to move faster through calls they already pull, Copilot earns its seat — keep it and stop. If the real problem is that scoring isn't consistent, the sample isn't representative, and nobody can prove why a rep got dinged, that's a custom workflow, and the bake-off just told you it's worth building. The OECD's work on AI adoption among smaller firms and the RSM middle-market AI survey both suggest the same sequencing: nail one governed workflow before you widen coverage. Want the build-or-buy call written down with the controls and the rollout sequence? Start with the AI roadmap.
