The Friday-afternoon go-live that nobody could actually approve
Picture the last hour before a customer go-live at a 120-person implementation shop. The delivery manager has eleven Jira tickets, a requirements doc that's three revisions out of date, a Teams thread where the customer "agreed" to a scope change, and a QA lead saying "I think we're good." Nobody can point to a single artifact that says: every acceptance criterion was tested, every Sev-1 is closed, and the customer signed off on what actually got built. So they ship anyway, and find out two weeks later that the integration the customer cared about most was never in the test plan.
That is the real shape of implementation QA, and it is why a faster summary doesn't solve it. The problem isn't that the evidence is hard to read — it's that the evidence is scattered, contradictory, and missing in places, and no tool is enforcing the rule that you don't go live until the gaps are closed. San Francisco Fed research on small-business AI use keeps surfacing the same gap: adoption is easy, operating capacity is not. Before you decide Copilot vs. custom, name four things out loud — which release, which evidence sources count, what severity model defines "blocking," and the one person whose name goes on the go/no-go.
Copilot reads the room. Custom AI holds the door.
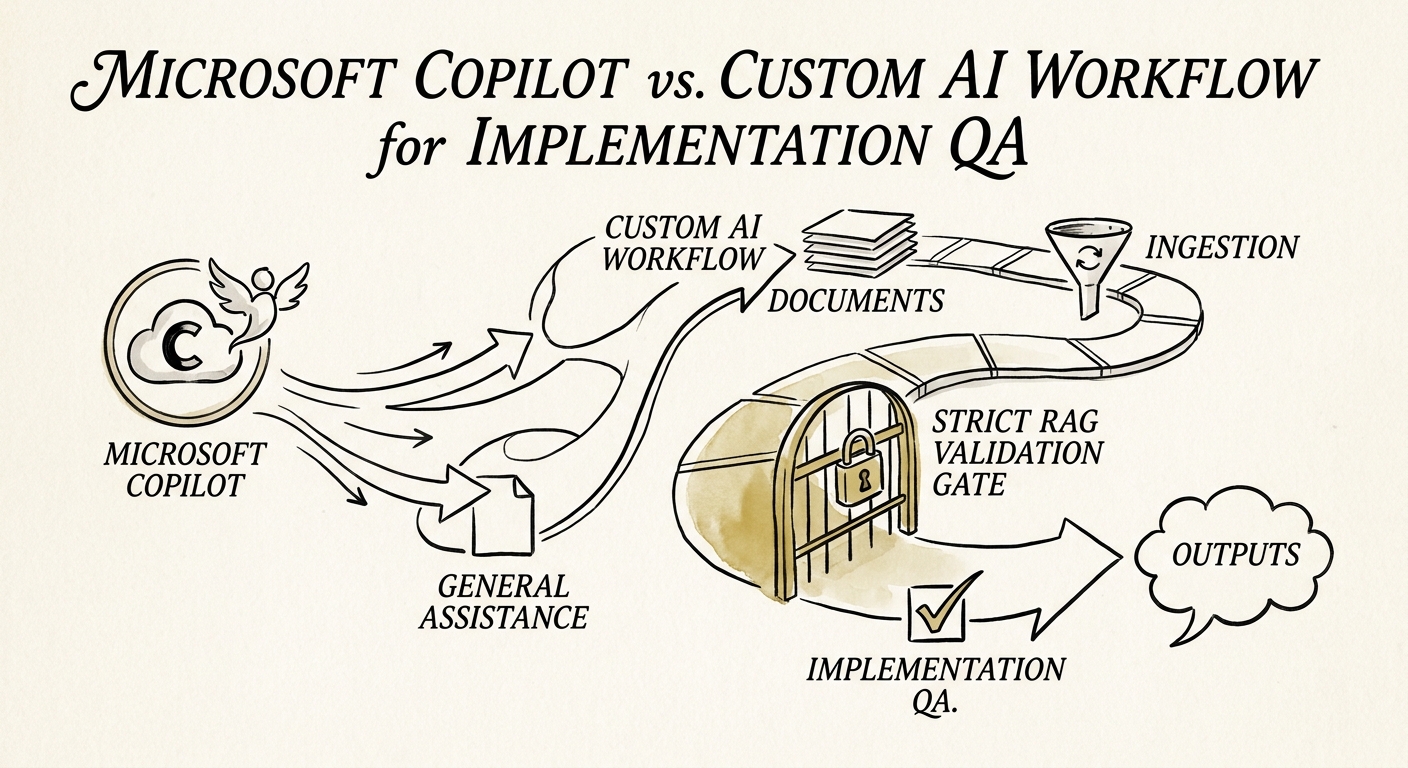
Microsoft 365 Copilot is genuinely good at the first half of this job. Point it at the requirements doc, the Teams thread, and the ticket comments, and it will draft you a release-readiness brief in two minutes: here's what changed, here's what the customer asked for, here's where the test notes contradict the spec. Because it runs inside your Microsoft 365 tenant with existing permissions and respects your data-protection boundaries, the QA lead can lean on it without a security review. For prep, for catching the obvious contradiction before the standup, that's real time back.
What Copilot cannot do is refuse to ship. It has no concept of a gate. It won't reconcile a tested acceptance criterion against the one a customer signed in a contract, route a reopened Sev-1 to the right engineer, or block the deploy button when evidence is incomplete. That's where a custom workflow earns its cost: it reads from Jira or Linear and your CRM, maps each acceptance criterion to a test result and an owner, applies the severity model the same way every release, and produces an auditable trail of who approved what. Build the escalation and fallback logic against the NIST AI Risk Management Framework, and use CISA's data-security guidance to control how customer commitments and implementation evidence flow between systems. The test: if the cost of a missed gate is a customer escalation, you want enforcement, not a summary.
Measure the launches that didn't blow up
The honest signal isn't how slick the readiness brief looks — it's whether the post-go-live week got quieter. Deloitte's State of AI work draws the line between a demo that wows and a system that changes the operating number, and for implementation QA that number is simple: how many launches went out with a known gap that nobody caught.
So track it directly. Count missed-requirement escapes (acceptance criteria that shipped untested), defect-triage speed on reopened Sev-1s, evidence completeness at the moment of go/no-go, how often a human overrides the gate and why, and the rate of post-launch customer escalations traceable to QA. Run it for two releases on Copilot-as-prep and two with a custom gate, and compare the escape rate — not the prep time. Practical split for Monday: keep Copilot in every reviewer's hands for the messy read-and-reconcile, and build the custom workflow the day a missed gate costs you a renewal, not a sprint. Most 50-300 person delivery teams discover the gate matters about one customer escalation before they wish they'd built it.
