
Most intake demos use the one document that never causes problems
Picture the demo: someone drops a crisp, born-digital invoice into the tool, and out comes vendor name, amount, due date, PO number, all perfectly extracted. It looks like magic. Then you deploy it across a professional services firm's actual inbox and the second week you get a faxed contract amendment, a scanned SOW with a partner's handwriting in the margin, and a "final_v3_FINAL_use_this_one.pdf" that contradicts the version already in your system. The demo never showed you those, because those are the documents that break the pipeline.
Here is the trap with document intake specifically: AI is genuinely good at the easy 80% and confidently wrong on the hard 20%, and the hard 20% is where your money and your liability live. A misread invoice line is annoying. A misclassified indemnification clause that gets auto-filed as "routine NDA" is a problem you discover in a dispute. IBM Institute for Business Value AI capabilities research makes the underlying point cleanly: AI capability is gated by data quality, operating model, adoption, and measurement, not by the model itself. For intake, that means the work happens before automation. You cannot route what you have not named, and most firms have never written down their actual document universe.
So start there, on paper, before a single API call. List every document type that lands in this function. For each one, answer four questions: who is the authoritative source, what fields actually matter, what confidence level would let you accept the extraction without a human glance, and what happens when the file is ambiguous. The NIST AI Risk Management Framework gives you the spine for this: map what is in scope, measure the extraction risk per type, manage the review threshold, and govern the whole thing as documents and senders change. The deliverable is unglamorous, a spreadsheet, and it is the single highest-leverage hour you will spend on the project.
The rule: autonomy scales with how cheaply you can catch a mistake
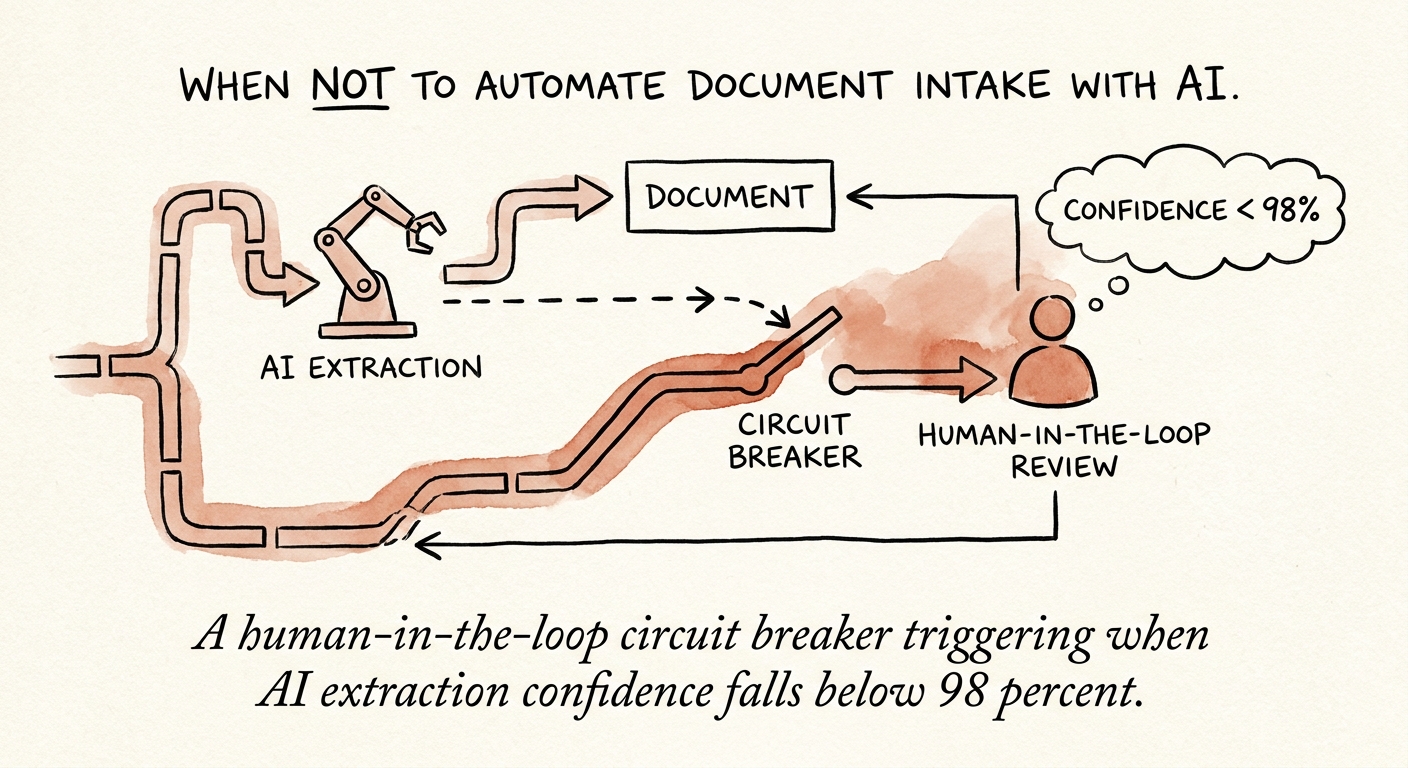
Once the document universe is mapped, sort each type onto a simple grid: how often is this document ambiguous or non-standard, and how expensive is an undetected error? A recurring monthly invoice from a known vendor is low-ambiguity, low-cost, so let the machine run it end to end. A new client's master services agreement is high-ambiguity, high-cost, so the AI's job is to extract, flag, and hand off, never to decide. The instinct to chase a single automation rate across all document types is exactly how firms end up with the confident misfile, the worst failure mode here, because nobody audits an answer the system already accepted.
Permission is not the same as safety, and this trips up technology and IT leaders constantly. Microsoft 365 Copilot data protection architecture shows how much of a document workflow rides on identity, permissions, and auditability. All real, all necessary. But "the system is allowed to read this file" answers a different question than "the system should act on this file without a human." A perfectly permissioned scanned contract with a smudged effective date is still a document that needs eyes. Intake controls have to add extraction confidence, source traceability back to the original page, and explicit rules for what counts as ambiguous, on top of the access layer.
And the controls cannot be theater. PwC Responsible AI survey work keeps surfacing the same gap, that responsible-AI principles often fail to survive contact with daily operations. The version that actually holds up: a sampled review of even the high-confidence accepts, a real exception queue that a named person works each day, a citation on every extracted field pointing to where it came from, and a correction log. That log is the part people skip and the part that matters most, because it is the only mechanism by which the system gets better instead of quietly repeating the same misread a thousand times.
What to build Monday: triage first, full autonomy last
Do not launch by promising leadership a fully automated intake desk. Launch with the AI as a triage clerk that sorts incoming documents by type and pre-fills structured fields for a human to confirm. That single move buys most of the speed, because the slow part of intake is rarely keying data, it is figuring out what a document even is and where it goes. Let the machine do the sorting and the first-pass extraction, and let a person keep the judgment until you have the data to earn more.
Instrument it from day one with five numbers, tracked per document type, not in aggregate: classification accuracy, field-extraction accuracy, exception rate, correction rate, and cycle time. When a given type runs for a few weeks with high extraction accuracy and a low correction rate, graduate that one type to full autonomy and leave the messy ones in the assisted lane. That is how you expand confidently instead of all at once and then walking it back after the first bad week.
If you want a structured starting point, a QuickStart AI Audit is built to map your document sources and source authority before you commit to a tool, and AI workflow automation is where the exception routing and confidence thresholds get designed. Map the universe, automate the boring documents, and keep a human between the AI and the ones that can hurt you.
