The same question, answered forty times, never written down
Open any support queue and you'll find it: the question your team has typed a thousand variations of. How do I migrate my data. Why did my invoice change. What happens when I hit the plan limit. Your best agents answer it beautifully every time — clear, accurate, on-brand — and then that answer evaporates into a closed ticket. The next customer asks again. Nobody ever turned the forty good replies into one help-center article, because writing the article is the task that loses every priority fight against the live queue.
That gap is exactly where AI earns its first paycheck in a support org — and it is the opposite of what most teams reach for. The instinct is to bolt a chatbot onto the website and hope it deflects tickets. The smarter first move is quieter: take your resolved tickets, your approved help-center answers, your release notes, and the questions you already know customers ask, and have AI draft the education asset a human editor would have written if they'd had the time. You are not asking the model to know your product. You are asking it to reshape answers your team already vetted into a format customers can self-serve. The RSM middle-market AI survey shows mid-market leaders moving AI out of the demo phase and into real operating use — but the use that sticks is the kind a team can actually supervise, and repurposing approved content is supervisable because the truth is already on file.
Permission the library, or you'll publish your own contradictions
Here's the failure mode nobody warns you about. You point the model at "the support knowledge," and the support knowledge contains three answers to the same billing question — one from 2024 that's now wrong, one from a power user's Slack reply that was a one-off exception, and one from the actual current docs. The model averages them, sounds confident, and ships a customer-facing article that's subtly false. When that happens, the problem was never the prompt. It was that you never decided which source wins.
So before a single draft gets written, name the approved library explicitly — the specific docs, the canonical macros, the release notes that count — and quarantine everything else. The CISA AI Data Security guidance frames the controls in plain terms: decide what data enters the system, who can touch it, and what happens to the output. For support content that means an approved-source list, a hard rule that strips customer-specific details out of any ticket before it becomes training material, and one editor who can kill a draft that wanders past its source. Lean on the NIST AI Risk Management Framework as a working routine rather than a binder: which topics carry real customer risk if they're wrong (billing, security, data handling), which require a human sign-off no matter what, and a log that retains the source link behind every generated paragraph. If you can't trace an article back to the answer it came from, you can't defend it when a customer acts on it. A 90-day implementation plan is where you assign that ownership across support, product, and marketing — one release lane, one reviewer queue, one exception log — before you expand to other formats.
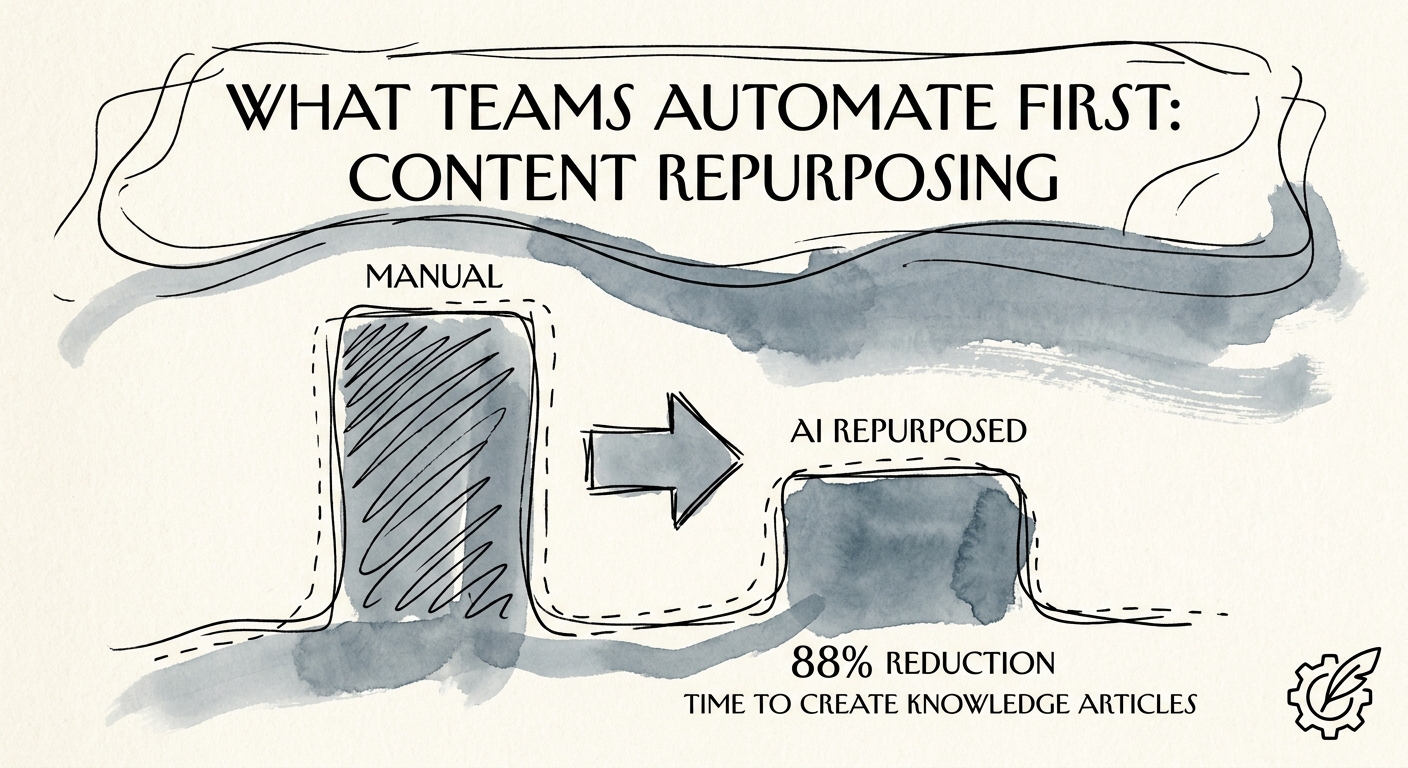
The scoreboard is fewer repeat tickets, not a folder of polished drafts
It's easy to declare victory because the AI produced thirty articles in an afternoon. Thirty articles nobody reads, that don't match the next product release, and that quietly add a maintenance burden is a loss dressed up as productivity. Measure the things that actually move: the lag from a question becoming common to a published answer existing, the rate at which your editor has to correct drafts before they ship, and — the only number leadership should care about — whether the volume of repeat tickets on that topic drops after the article goes live. Watch Salesforce State of Service dynamics in your own data: support is judged on both speed and quality, and a self-serve article only counts if it deflects the ticket without creating a confused follow-up.
And keep the stop rules sharp, because customer education is the place where a wrong answer costs the most trust. Do not auto-publish when the product answer is genuinely disputed internally, when the source ticket is laced with one customer's private details, or when the draft makes a claim that legal, security, or product hasn't blessed. In those cases the model still earns its keep — it can assemble the source packet so a human writes the final word faster — but it does not get to be the voice talking to your customer. Want to pressure-test which support topic to start with and what "fewer repeat tickets" should be worth before you build? Build the AI roadmap, and keep the economics honest with ROI measurement that doesn't fake the savings.
