The promise nobody wrote down
Picture a 60-person B2B services firm closing a $180K engagement. The signed SOW says "data migration and integration." The discovery call notes — three of them, in a CRM nobody reads after close — say the client expected their legacy reporting dashboards rebuilt, too. The deal desk granted a 15% discount on the condition that go-live slips to Q3. None of that made it into the kickoff deck the delivery lead presents on day one. So the delivery lead promises a Q2 go-live, says nothing about dashboards, and the account manager who closed the deal is already off chasing the next logo. Week two, the client asks where their dashboards are. Now you're eating rework to keep a reference customer.
That gap is the single most expensive thing in a services business, and it is almost never a delivery problem. It is a handoff problem. The promise was made across four systems — the SOW, the call notes, the deal-desk exception log, the customer-success intake — and no human ever reconciled them into one document before someone stood up in front of the customer. This is exactly the kind of cross-source comparison work that is tedious for people and trivial for a model that can read all four sources at once.
The reason to point AI here first, before chatbots or proposal-writing, is that the inputs already exist and the cost of a miss is enormous and measurable. Salesforce's State of Sales research and the companion State of Service research both land on the same uncomfortable truth: revenue leaks where selling and servicing don't share context. A handoff-QA workflow is the cheapest place to plug that leak because you're not generating anything new — you're catching contradictions between things you already wrote down.
What the model reads, and what it's allowed to say
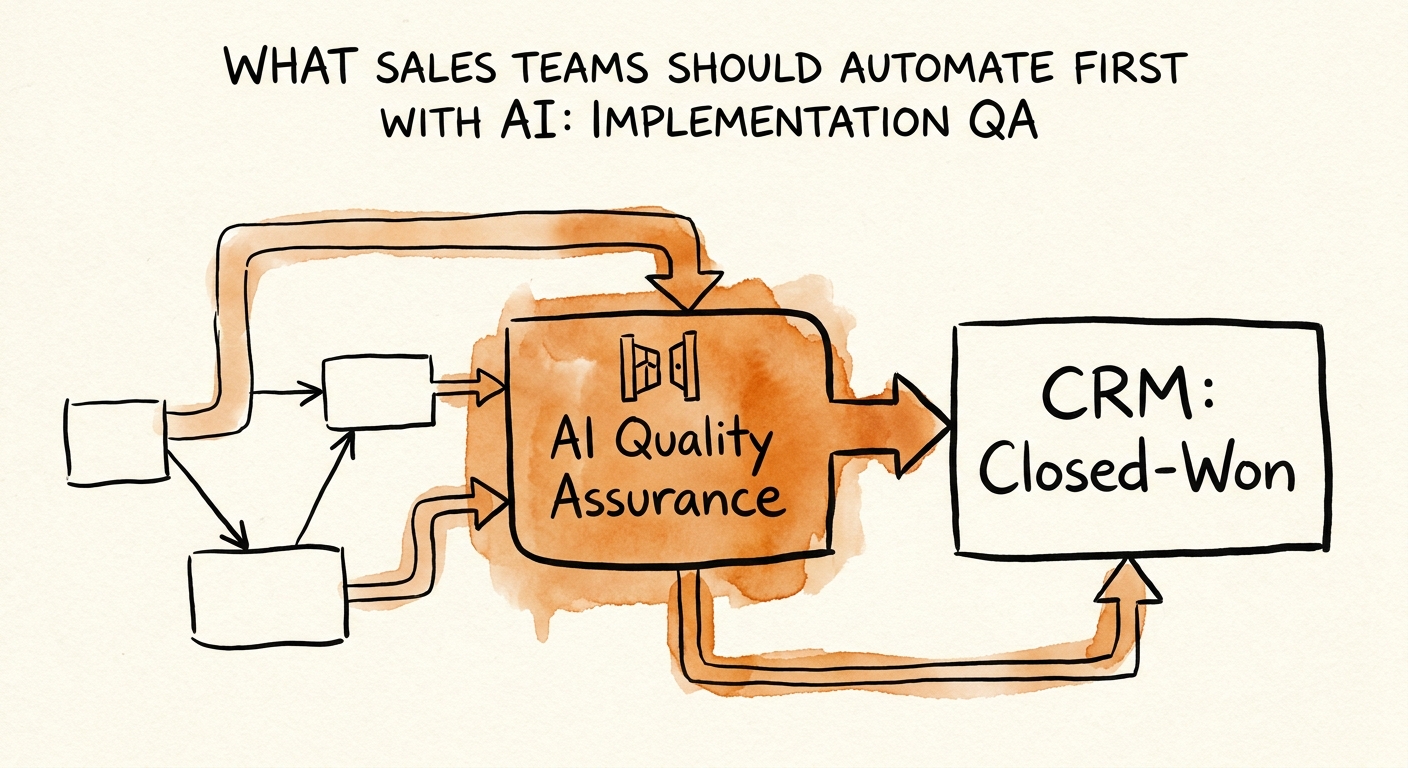
Keep the first build embarrassingly narrow: one engagement, one packet, reviewed by one human before a single QA note touches the kickoff. The packet is the signed SOW, the order form, every deal-desk exception, the discovery and close call notes, and the customer-success intake form. The model's only job is to read all six and produce a short list of contradictions: commitments in the call notes that never made it to the SOW, the discount-for-timeline trade buried in the deal desk, acceptance criteria that no one owns, deliverables described in two different scopes. Crucially, each flag must cite which source produced it — "the Q3 condition is in deal-desk note #4421, but the kickoff deck says Q2." A flag the delivery lead can't trace back to a source is a flag they'll learn to ignore.
This is where the NIST AI Risk Management Framework earns its place: the same sentence carries different weight depending on where it lives. "We can probably handle the reporting piece" is a harmless aside in a sales call. The instant it's treated as a delivery commitment, it's binding work the firm now owes for free. The model needs to surface that line and flag it as unconfirmed scope — not silently fold it into the plan, and not drop it. The delivery lead decides; the model just refuses to let it disappear.
Measure the thing that pays: how many flags the delivery lead accepts, how many rework loops you avoid, how many kickoff slips you catch before the customer hears a date. If the workflow keeps surfacing the same missing field — say, acceptance criteria are absent in 8 of 10 SOWs — that is not an AI win to celebrate. That is your SOW template telling you it's broken. Fix the template and the model has less to catch. The goal is a cleaner handoff, not a longer QA report.
Guard the customer's data while the workflow earns trust
This workflow reads your most sensitive records: pricing exceptions, contract terms, internal notes about which accounts are shaky. So scope the inputs hard. The CISA AI data-security best practices point the way — feed the model only approved sales, contract, and delivery sources, log every QA output so you can audit what it saw, and keep final readiness authority with the delivery lead. No flag auto-publishes. No note goes to the customer. The model proposes; a human signs off.
Run a tight 90-day loop to prove it works. For every engagement that went through QA, compare the accepted flags against what actually surfaced in the first two weeks of delivery. Three numbers tell you everything: how many real commitments the model caught before kickoff, how often delivery overruled a flag (your false-positive rate), and which sales fields keep producing ambiguity. That last number is gold — it tells you the exact spot in your sales process to fix.
And here's the test that separates a real fix from theater: if kickoffs still uncover buried discount terms or phantom dashboard promises after a quarter of QA, the prompt isn't the problem. Sales, deal desk, and delivery simply don't share one definition of "ready to deliver." No model fixes a disagreement about what was sold. Resist the urge to expand into automated customer status updates until the internal handoff is clean — point it outward and you're just broadcasting your contradictions faster.
Before you build, confirm this work actually repeats enough to automate using the manual-work scoring guide, then stage source cleanup, reviewer training, pilot, and the scale decision with the 90-day AI implementation plan. Pick the next workflow only after kickoff readiness improves in numbers you can show a skeptic.
