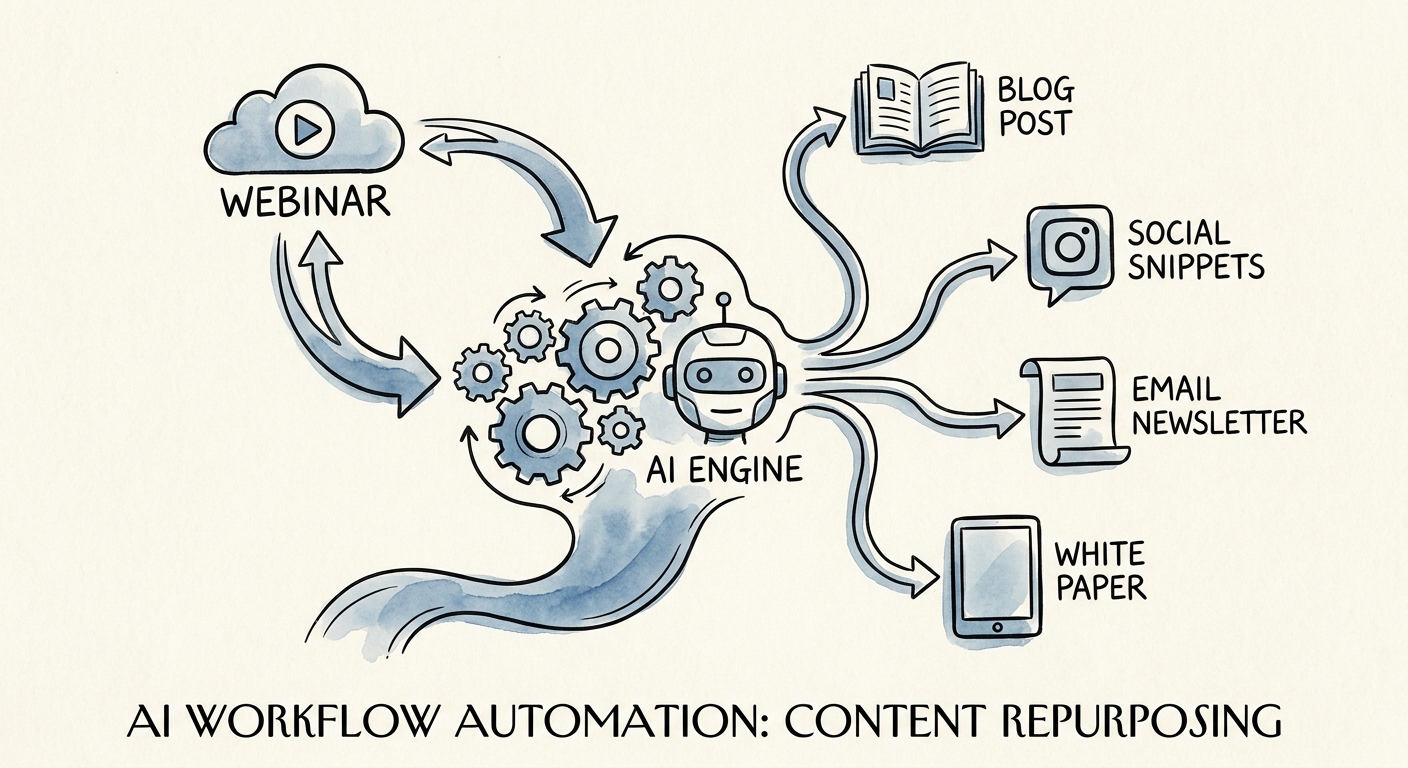
One webinar should become forty assets, not forty problems
Say a 30-person consultancy runs a 45-minute webinar with a sharp client story in it. The old way: a marketer pulls three quotes, writes a recap post over two days, and the other 90% of that recording dies in a Google Drive folder no one opens again. The promise of AI repurposing is the opposite — that one webinar becomes a LinkedIn carousel, six pull-quote graphics, a newsletter section, three sales-enablement one-pagers, a blog recap, and a dozen short clips. Forty assets from one source.
Here is the part everyone skips: a repurposing pipeline is a multiplier, and multipliers work in both directions. If the source is approved, current, and accurate, you get forty clean assets at a marginal cost near zero. If the source contains a stale price, an unapproved client name, or a claim legal never cleared, you now have that error in forty places — published across channels before a human reads the first one. The McKinsey State of AI 2025 finding that value scales when companies redesign the work around the tool lands hard here. The redesign for repurposing isn't a better prompt. It's deciding, deliberately, what is allowed to become a source in the first place.
That's why the first control isn't a model setting — it's a gate. One approved source asset before any derivative gets generated. The Salesforce State of Marketing report shows marketing teams already leaning on AI across content, data, and personalization; the teams that get burned are the ones who let the tool repurpose whatever was nearest, not whatever was vetted.
Where derivatives quietly go wrong
Factual drift in repurposing is sneaky because each step looks fine. The webinar says "we cut onboarding time by roughly a third." The blog draft rounds it to "by a third." The LinkedIn caption tightens it to "we cut onboarding time in half." The sales one-pager, summarizing the caption, prints "fastest onboarding in the industry." Nobody lied at any single step. The pipeline drifted, because each derivative was generated from the previous derivative instead of from the source. That single rule — every asset is generated from the approved original, never from a sibling — kills most of the drift before it starts.
The NIST AI Risk Management Framework gives you the shape of the rest: map the context, measure the failure modes, manage the controls, and put a named human on approval. For a content operation that's four concrete checks before anything publishes — source accuracy (does the claim still match the approved original?), channel fit (does a 1,200-word recap belong as an Instagram caption?), approval (did the owner sign off on this specific asset?), and performance tagging (can you trace what this asset drove?). Four checks, one owner, every time.
And know where your sources actually live. For most service firms the good material is scattered across shared drives, old sales decks, and meeting-notes archives — exactly the surfaces the Microsoft 365 Copilot data protection architecture documentation cares about. Before you let a tool repurpose from those spaces, two things have to be visible: permissions (can this content legally leave the room it was created in?) and freshness (is this the current deck, or the one from two pricing changes ago?). A repurposing engine pointed at a stale folder will confidently broadcast last year's positioning to every channel you own.
Measure reuse, not output
The trap is judging the system by how much it produces. Forty assets a week is a vanity number — it tells you the machine ran, not that it helped. The IBM Institute for Business Value AI capabilities research makes the case for measuring adoption and operating impact instead of raw volume, and for a repurposing pipeline that means a short, honest scorecard:
Reuse rate — of the assets generated, how many actually got used versus quietly trashed? If it's under half, your source selection is wrong, not your model. Edit distance — how heavily did the owner rewrite before approving? Heavy edits every time means the tool is creating review work, not saving it. Time to publish — did the webinar-to-channel cycle drop from two days to two hours, or did approval bottleneck it right back? Pull-through — and the one that matters most: are sellers and marketers reaching for these assets unprompted, or did you build a library nobody opens?
Monday's move: pick your single best piece of source content from the last quarter — the webinar, the research note, the case story everyone references. Make it the only approved source. Generate ten derivatives from it (not from each other), run the four checks, and track which ten get used. If reuse is high and edits are light, you've found your pattern and you can scale it. If not, you've learned something cheap before you automated it everywhere. The AI Opportunity Score and Human Renaissance AI transformation services can help you decide whether your content operation is ready to turn that pattern into a standing pipeline.
