It's 9:40 a.m. and the board is already on fire
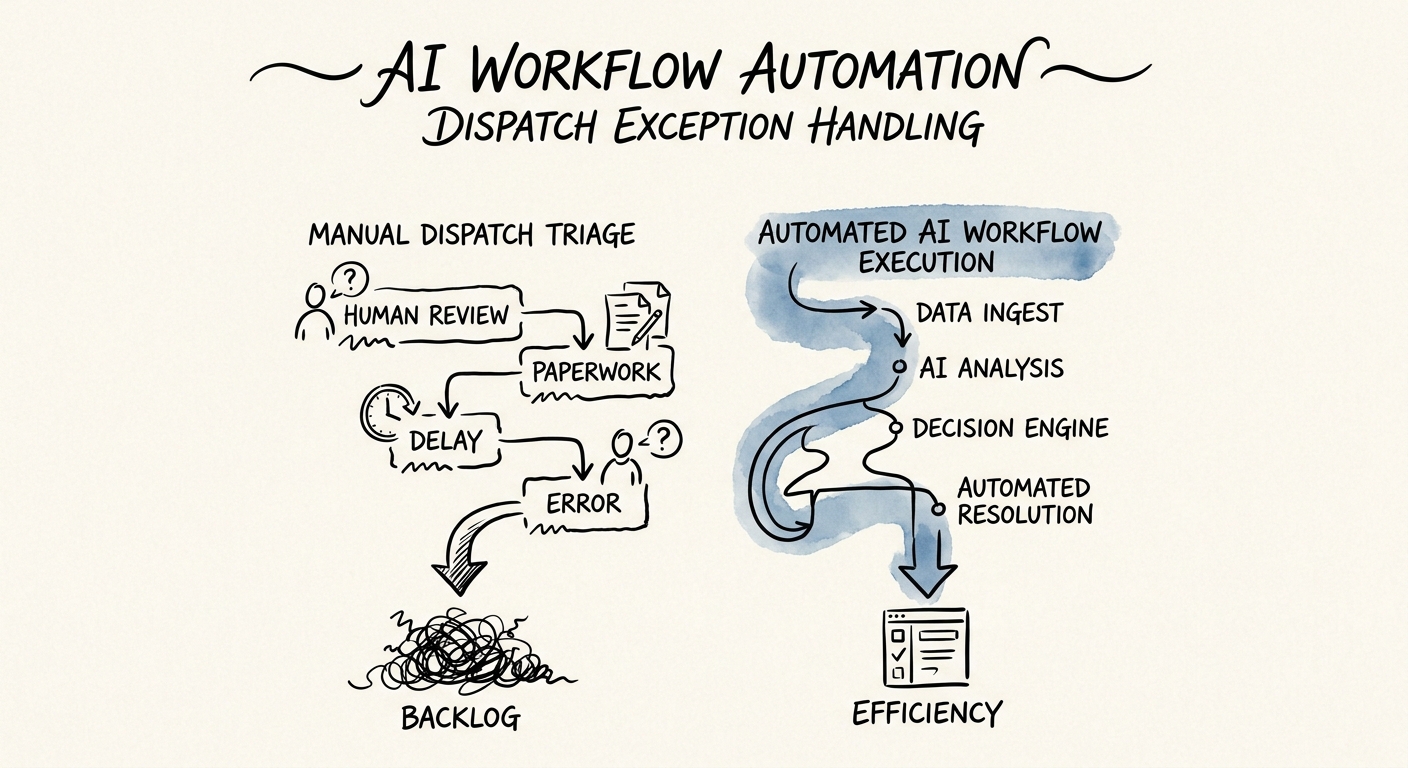
Picture the dispatch desk at a 60-tech HVAC and refrigeration shop. The 8 a.m. install no-shows because the customer's loading dock is blocked. A tech texts that the part on the truck is the wrong SKU. A commercial account with a same-day SLA just opened a ticket that outranks three residential calls already routed. By 9:40 the dispatcher has reshuffled the board twice, and every reshuffle quietly broke a promise someone made yesterday.
This is the trap most teams fall into when they bolt AI onto dispatch: they aim it at the schedule and let it auto-reroute. Wrong target. The board is not the problem. The exception stream hitting the board is the problem, and exceptions are not interchangeable. A blocked dock is a reschedule. A wrong part is a parts-and-second-visit problem. A breached commercial SLA is a money-and-relationship problem. McKinsey's supply chain operations research frames dispatch as exactly this kind of reconciliation problem — capacity, location, service windows, and commitments colliding in real time — which is why the first useful thing AI can do is classify what just landed, not act on it.
So the opening move is narrow and boring on purpose: as each exception arrives, have the assistant tag it with four signals before anyone touches the route — customer priority, available capacity, SLA status, and the actual reason for the exception. Salesforce's State of Service report is blunt that dispatch quality is customer experience, not back-office hygiene; a dispatcher who can see "commercial / no slack until 2pm / SLA breaches in 90 min / cause: dock access" reacts in seconds instead of reconstructing it call by call.
Draw the line at "recommend," not "reschedule"
Here is the decision that actually matters, and it's the one templated rollouts skip: what is the assistant allowed to do versus only propose? My line for dispatch is unambiguous. AI can rank options — "move the 11 a.m. residential to Thursday, slot the commercial breach into Marco's gap, flag the customer who's already been bumped once." It does not get to send the customer text, reassign the tech, or close the SLA clock. A human owns final exception policy, full stop, because every one of those moves is a commitment to a person who will remember it.
Why so strict? Because the cost of a wrong auto-reschedule isn't a corrected calendar entry — it's a truck 40 minutes out from a stop that no longer exists, plus a customer who got a confirmation and a cancellation in the same hour. The NIST AI Risk Management Framework gives you the structure to make this explicit rather than assumed: map where dispatch recommendations touch customer promises, measure the failure modes that actually hurt (silent double-booking, an SLA timer the model misread), and govern who can approve an override. Write down the escalation rule — say, anything touching a same-day commercial SLA or a twice-bumped customer routes to a named dispatcher before it executes.
And before any of this works, check what the assistant is even reading. Dispatch context is scattered — the SLA lives in the CRM, the dock note is buried in an email thread, the part status is in a tech's Teams message, the route is in the scheduling system. Microsoft 365 Copilot's data-protection architecture is the reminder that permission boundaries and data freshness aren't fine print: an assistant summarizing a ticket off a three-day-old cached schedule will confidently recommend slotting a tech who called in sick this morning.
Measure the scramble, not the screenshot
The failure mode I see most after go-live is a team celebrating that "the AI classifies exceptions now" while the dispatcher's day is exactly as chaotic as before. Novelty is not a metric. The thing you were drowning in was the two-hour scramble after each exception — so measure that. Track time from exception arrival to a routed decision, how many SLA breaches were caught while still recoverable versus discovered after the fact, repeat-bump rate on the same customer, and whether dispatchers actually accept the recommendations or quietly override every one. IBM's Institute for Business Value research on AI capabilities makes the case that the operating capability around the tool — data quality, the operating model, adoption — is what determines whether any of this sticks, not the model itself.
Run it for two weeks against a real baseline. If classification is fast but acceptance is near zero, your four signals are wrong or your data is stale — fix that before expanding scope. If acceptance is high and recoverable breaches climb, you've got the wedge; now widen the exception types it handles.
If you're deciding whether your dispatch desk is even ready for this, start by scoring the inputs rather than the ambition: the AI Opportunity Score walks through data readiness and decision ownership, and Human Renaissance AI transformation services can help you set the recommend-versus-execute line before the first reroute goes live.
