The brief that blew up the meeting
Picture a senior consultant walking into a renewal conversation with a $400K account, holding an AI-generated brief that confidently cites a "recent product launch" the client quietly killed eight months ago. The client notices in the first five minutes. Now the rest of the hour is spent rebuilding credibility instead of expanding the account. That is the real failure mode of AI research briefing — not bad grammar, but confident, undated, unsourced wrongness presented to someone who knows better.
Research briefing is genuinely one of the best AI workflows in a professional services or technology firm, because the output is structured by nature: summarize an account, a market, a competitor, or a delivery situation, with evidence a partner can defend. The McKinsey State of AI 2025 survey shows knowledge-and-research-style work is exactly where AI adoption is widening across functions. But the value never came from "ask a model to summarize the account." It comes from redesigning what a brief is and what it has to prove before anyone reads it.
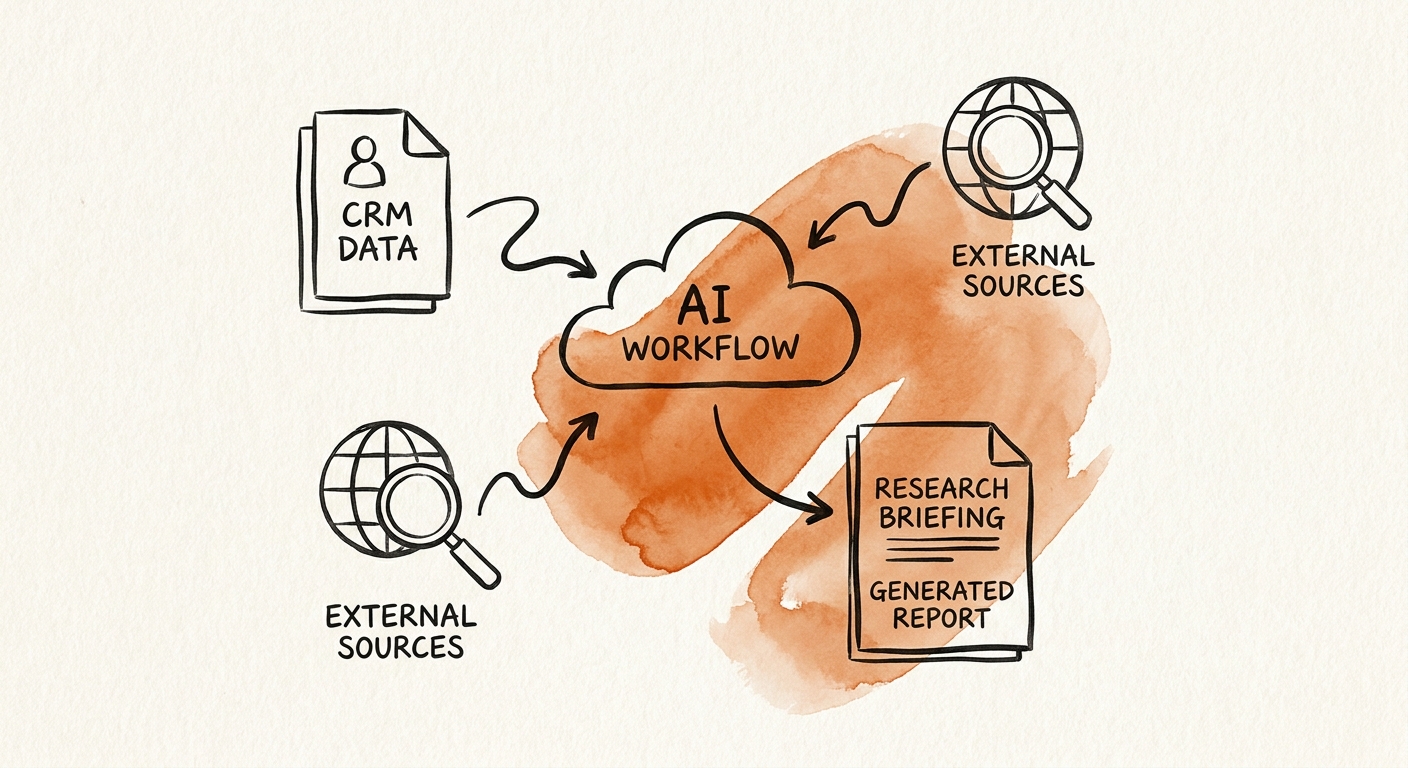
And the moment the brief draws on internal files — past engagement notes, the CRM, the shared drive — permissions stop being a nice-to-have. Microsoft's 365 Copilot data protection architecture exists precisely so a model summarizing internal knowledge respects who is allowed to see what, leaves an audit trail, and doesn't quietly surface a confidential margin note from another client's folder into your briefing.
Build the brief to argue with itself
The fix is structural, and it is boring on purpose. Every claim in the brief carries four tags: source type, date, confidence, and reviewer status. "Competitor launched X" is useless. "Competitor launched X — press release, March 2026, high confidence, reviewed" is a sentence a partner can stand behind. The NIST AI Risk Management Framework is the practical backbone here: it pushes you to make uncertainty and provenance visible rather than papering over them. The working rule for a research brief is blunt — if a claim isn't solid enough to cite, it isn't solid enough to repeat to a client.
Say a 60-person advisory firm builds this. The agent's job is narrow: discover sources, extract them with dates, structure the synthesis, and flag anything it couldn't verify. The human's job is the part that actually requires judgment — deciding what matters for this account this week. Bain's agentic AI transformation report describes systems that can gather and chain together research steps autonomously, and they can — but the first version you ship should stay supervised. Let the agent collect and arrange; let a person sign the brief.
What most teams get wrong: they grade the brief on coverage. More sources, longer summary, looks thorough. The right grade is the opposite — how short can the trusted path be? A half-page brief where every line is dated, sourced, and reviewer-approved beats a three-page document where 30% is unverifiable filler the partner has to mentally discount.
The only metric that matters: did the meeting go better?
Track the obvious operational numbers — prep time per brief, citation coverage, how heavily reviewers edit before approval, whether the brief killed follow-up research that used to eat an afternoon. But the metric that decides whether you scale this is downstream: did the brief change how the conversation went? A workflow that produces beautiful, well-cited summaries that don't shift a single decision is a writing exercise, not an automation win.
Here's the Monday move: pull your last ten client or account briefs, written by humans, and tag every factual claim with source, date, and confidence after the fact. You will find the unsupported assertions instantly — and that list becomes the spec for what the AI workflow must enforce, because those are the exact claims that get a senior person caught flat-footed in the room.
When you're ready to design the workflow itself, start with AI Workflow Automation, and use the AI Opportunity Score to check whether research briefing is actually your highest-leverage first use case or whether something else in the delivery org should go first.
