Watch where a Tuesday morning actually breaks
Picture a 25-seat support desk on a Monday-after-a-long-weekend morning. The queue is at 340 tickets. Half of them are duplicates of the same outage. A third are routed to the wrong team and will bounce twice before they land. The senior agents are the only ones who know which knowledge article is current and which one is three product versions stale. That is where the time goes — not in the actual answering, but in the sorting, the re-routing, the hunting, and the writing-up.
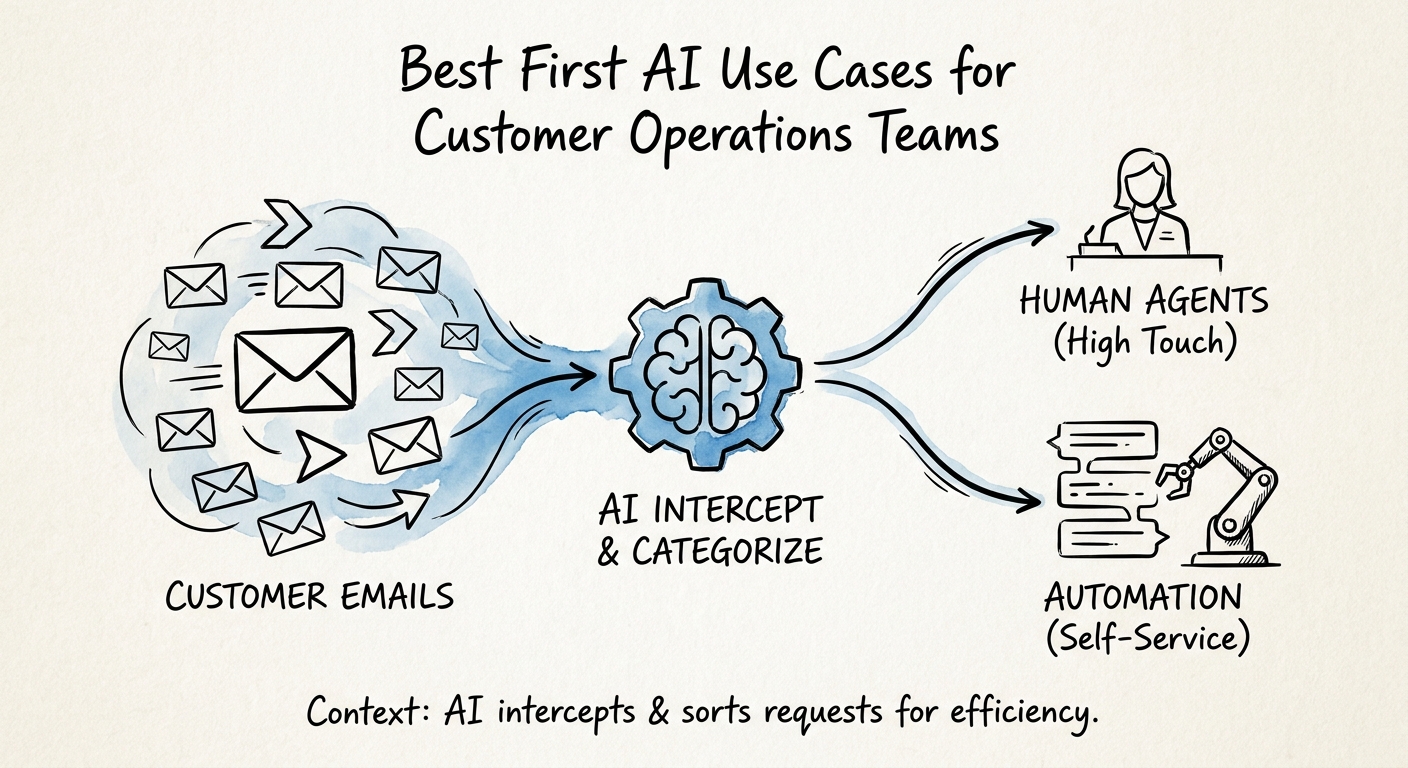
So when someone says "let's put AI on customer service," the instinct is a customer-facing chatbot. That is the one use case that does none of the above and adds a new failure mode: an unsupervised bot saying the wrong thing to a paying customer, in writing, at scale. The better first move is to point AI at the four chores that are silently eating your agents' day — triage and routing, knowledge retrieval, case summarization, and follow-up drafting — and leave the human in front of the customer.
This is not a contrarian opinion; it tracks where adoption is actually heading. The RSM middle-market AI survey shows mid-market leadership pushing AI into core operations rather than novelty deployments, and the San Francisco Fed analysis of AI and small businesses shows the same pressure reaching firms with no dedicated AI team to absorb a public mistake. Both point to one rule for a support desk: start where a better outcome shows up in your own queue before a customer ever sees it.
Score each candidate on one axis: how loud is the failure?
Rank your support workflows on a single brutal question — when this goes wrong, who finds out and how? An internal case summary that's slightly off gets corrected by the agent reading it. A cancellation handled by a bot that misreads the account gets corrected by the customer's lawyer. Same model, wildly different blast radius. The OECD SME adoption report draws the line you need here: enthusiasm is cheap, but adoption capacity — current policies, clean account data, supervisors who can review output — is what determines whether a use case is safe to ship.
Sort your work into two columns. On the low-blast side: tagging and routing tickets, surfacing the right knowledge article, summarizing a long thread for the next agent, drafting a reply for a human to approve, and QA-sampling closed tickets for tone and policy adherence. On the high-blast side: billing exceptions, cancellations and saves, anything regulated, and any answer that reshapes what the customer believes they're owed. The NIST AI Risk Management Framework gives you the structure to score this deliberately instead of by gut feel, and the CISA AI Data Security Best Practices add the part teams skip: if the answer depends on pulling a customer's account, you now own permissions, access logs, and an escalation path for when the source data is wrong.
The winning first candidate clears one test — a supervisor can see the receipt. Which policy, which prior ticket, which knowledge article produced this output? If your agent can glance at the citation and accept or reject in five seconds, you have a reviewable workflow. If the answer arrives as an unexplained verdict, you don't have a first use case; you have a liability you haven't met yet.
Run it as a 90-day pilot with numbers you already track
Pick one workflow — say, AI-drafted first replies on your top three ticket categories, agent-approved before sending. Don't measure it on "AI tickets handled," which means nothing. Measure it on the metrics your QA lead already pulls: first-contact resolution, repeat-ticket rate on those categories, escalation accuracy, time-to-first-useful-answer, and QA scores on tone and policy. Take a two-week baseline first. If FCR doesn't move and reopens don't drop, you learned something cheap and reversible — which is the entire point of keeping the bot away from the customer.
This discipline is what separates the pilots that survive from the ones that get quietly killed. The Deloitte State of AI report ties realized value to process change rather than the model itself, and the Gartner agentic AI project forecast projects that a large share of agentic projects get canceled when autonomy outruns clear value and data quality. The defense is the same on both fronts: keep the first use case inside a human-reviewed loop, prove the queue moved, then earn the right to widen the autonomy.
Monday-morning version: open last week's tickets, count how many bounced between teams and how many forced an agent to dig for a stale article. That count is your first use case, ranked and waiting. When you're ready to wire it up — triage, retrieval, summarization, or QA — that's the work that belongs in AI for Customer Service, where it becomes a visible operating improvement instead of a chatbot gamble.
