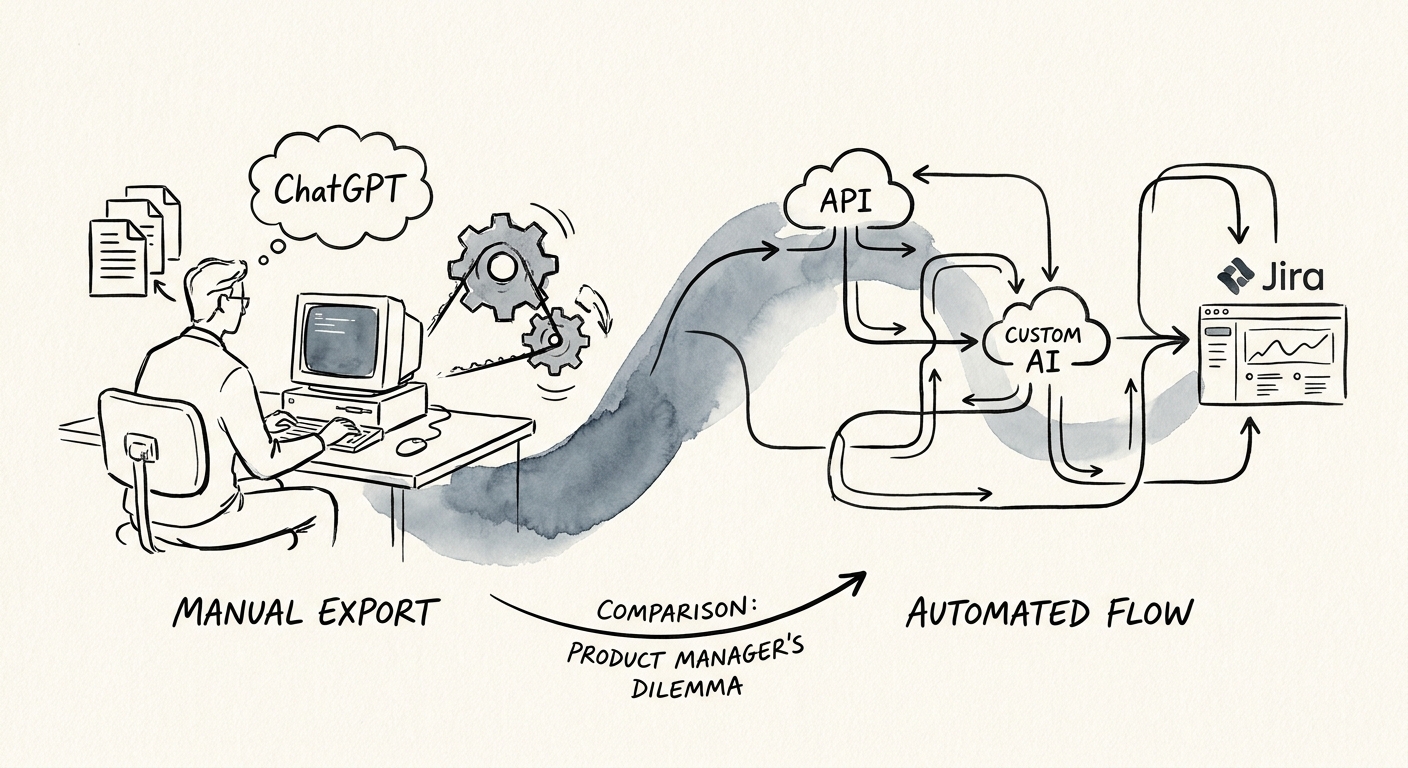
The 600-Ticket Summary Nobody Acted On
Picture a 120-person SaaS company. The VP of Customer Success exports a quarter of support tickets, NPS verbatims, three churn calls, and a stack of onboarding notes, drops them into ChatGPT Business, and asks for the top themes. Ten minutes later she has a clean list: "onboarding friction," "reporting gaps," "slow support response." It reads beautifully. She pastes it into the QBR deck. And then nothing happens — because the PM looks at "onboarding friction," asks "for which customers, saying what, exactly?", and the answer is gone. The export got summarized; the evidence got vaporized.
That is the actual failure mode in customer feedback analysis, and it is different from the failure modes in contract review or invoice coding. Feedback isn't wrong, it's weighted. A single furious enterprise account that pays you $80K churns for a different reason than fourteen self-serve users who never finished setup. A summary that flattens those into one bullet has destroyed the thing that makes feedback worth reading. ChatGPT Business is genuinely good at the first pass — the OpenAI Help Center description of ChatGPT Business covers the shared-workspace use case well, and OpenAI's enterprise privacy material frames how business data is handled. For a one-time "what are people complaining about this quarter" question, that's the right tool. Use it and move on.
The build-vs-buy line here is one word: traceability. The moment someone needs to click from a theme down to the four exact quotes that produced it, weight a signal by segment or ARR, route a churn risk to the right owner, or prove three months later that the roadmap actually changed because of feedback — a chat summary stops being enough. Adoption research from RSM's middle-market survey, the San Francisco Fed's small-business work, and the OECD's SME research all point the same direction for companies your size: the win isn't fancier summaries, it's less time lost between a customer saying something and someone owning it.
The Quote Trail Is the Whole Product
Here is what separates a feedback workflow from a feedback summary. In a workflow, every theme carries its receipts. "Reporting gaps — 11 mentions" expands into the eleven verbatims, tagged by plan tier, account size, and whether the customer is expanding or at risk. The PM doesn't have to trust the AI's clustering; she can audit it. That single capability — drilling from theme to source quote and back — is the line most teams cross when they outgrow ChatGPT Business, because a chat thread has no durable link between the bullet it gave you and the row in the export it came from.
Three controls matter specifically for feedback, and they map to known risks. First, quote approval: a verbatim that names a competitor, includes a profanity-laced rant, or reveals an unannounced commitment your sales team made should not flow into a customer-facing roadmap note unreviewed. Second, minority-signal protection: the NIST AI Risk Management Framework is useful precisely because it names failure modes like distorted themes and dropped minority signals — and in feedback, the three customers quietly describing a security gap matter more than thirty describing a UI nitpick, even though the model will rank by frequency. Third, data sensitivity: feedback is full of customer names, internal account notes, and contractual promises, which is why CISA's AI data-security guidance belongs in the design conversation, not as bureaucracy but as the rule for which comments are even allowed in the chat tool versus which stay locked in your support or product system.
So the practical control layer for feedback analysis is small but specific: quote traceability, segment and ARR weighting, an owner attached to each theme, automatic ticket creation for accepted product themes, and a churn-risk escalation log. Don't grade the output on how articulate the themes sound. Grade it on whether a manager can pull up "onboarding friction," see the segment mix, read the source quotes, and find the Jira ticket it spawned. If she can't trace it, you bought prose, not insight.
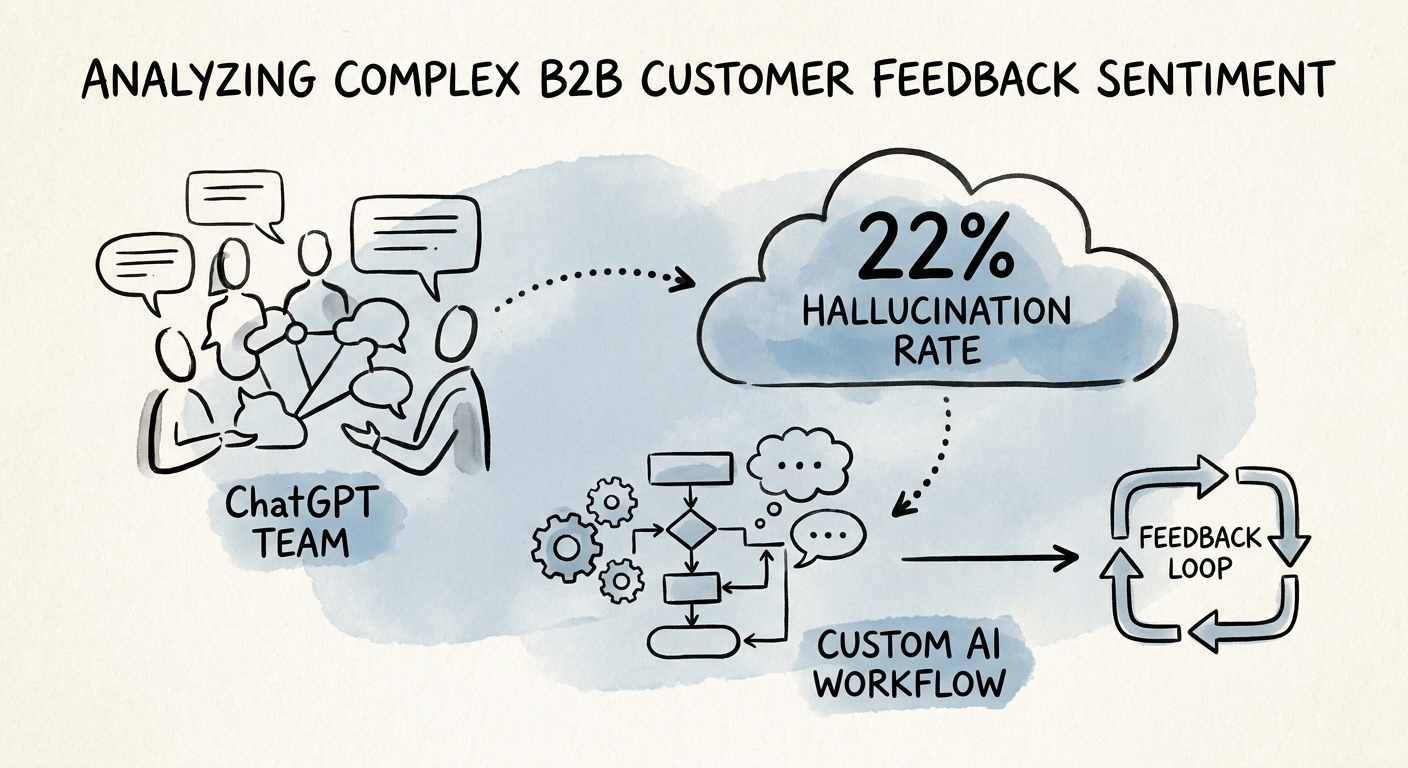
Count Tickets Created, Not Themes Found
The metric that kills pilot theater in feedback analysis is brutal and simple: how many product or retention decisions changed because of the last batch you ran? Deloitte's 2026 AI research keeps pushing teams off the high of "we summarized a lot of data" and toward production outcomes, and for feedback the honest scoreboard is: duplicate themes merged, themes accepted with their evidence intact, time from churn-risk flag to owner contact, and product tickets actually opened. If you ran feedback through AI all quarter and opened zero tickets and saved zero accounts, the volume of clean summaries is noise.
Start narrower than feels satisfying. Pick one recurring source family — support tickets plus the last quarter's churn notes — and run it weekly against one decision: does the next sprint's backlog change, or does an at-risk account get a call it wouldn't have gotten? If ChatGPT Business is enough to inform that one decision, you've saved yourself a build. If the same sources come back every Monday and three different people keep re-clustering them by hand, that repetition is your signal to build the workflow around the evidence trail. Pair the customer-service automation lens with a focused rollout plan before you wire up every feedback channel you own.
Write down the decision in one line: feedback analysis stays in ChatGPT Business, moves to a custom workflow, or pauses until the source data is clean enough to trust — and the reason is the evidence, specifically theme-with-receipts acceptance, escalation speed, and tickets created. Expand to more channels only when the owner can say plainly what got faster, what got sharper, and which customer you didn't lose. That's the difference between a feedback program tied to the roadmap and a quarterly ritual of beautifully summarized complaints that change nothing.
