The question that should never get a confident wrong answer
A 120-person company turns on an AI assistant and within a week someone types: "I'm in California, salaried, hired in March — how much PTO have I accrued and can I cash it out when I leave?" That single question touches jurisdiction, employment status, hire date, and a payout rule that California treats very differently from Texas. If your assistant answers smoothly and gets it wrong, the employee doesn't know it's wrong. They act on it. That's the difference between policy Q&A and ordinary document search: people do something with the answer.
That's also why "we already pay for ChatGPT, let's point it at the handbook" deserves a harder look than most knowledge-base projects. Smaller companies are pushing AI into real operational workflows fast — RSM's middle-market survey, San Francisco Fed research, and the OECD's SME adoption report all show the same trend. But policy is the one knowledge domain where a fluent guess is more dangerous than no answer at all.
So sort your policy questions into two piles before you pick any tool. Pile one: context-free and current. "What's the holiday schedule?" "Where do I submit a reimbursement?" "What's the parental leave policy in the U.S.?" These have one right answer regardless of who asks. Pile two: context-dependent or consequential. Anything that bends on state, employment classification, manager approval, customer contract terms, or a security procedure. Pile one is a summarization job. Pile two is a system you build.
What "build" actually buys you that a chat workspace can't
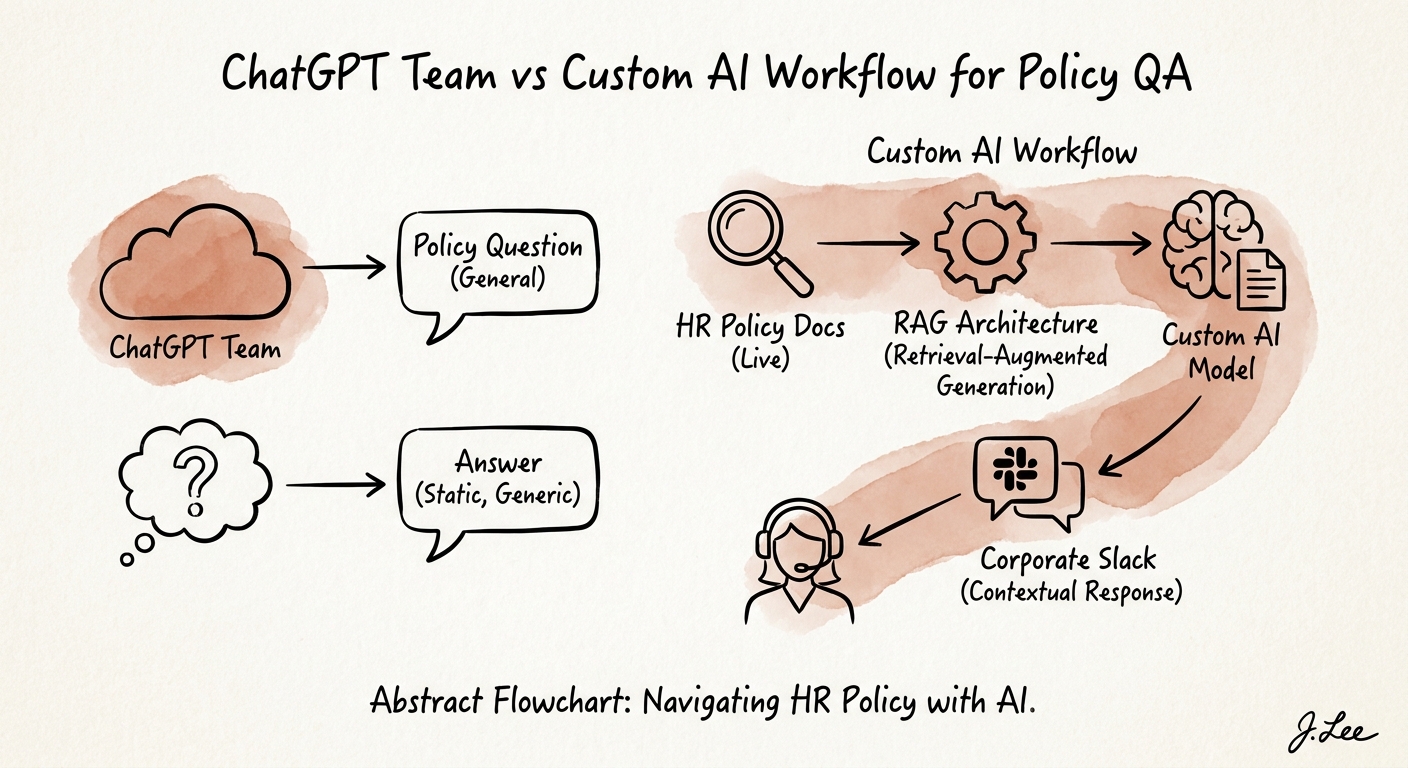
ChatGPT Business gives you a shared workspace, and the enterprise privacy controls handle the data-boundary question — your handbook isn't training the model. That's real and it's enough for pile one. Drop the current handbook in, let people ask, and have HR spot-check. Done.
Pile two is where a chat assistant quietly fails, because the failure modes are invisible. Walk through what breaks: an employee asks about overtime eligibility, and the model answers from the 2023 handbook version someone pasted in months ago — there's no flag that the document is stale. A contractor asks about benefits and gets the full-time answer, because the assistant has no concept of who is asking. A manager asks about a termination process and the model reasons its way to a plausible-sounding sequence that skips the legal review step, because nothing forces it to refuse and route. None of these throw an error. They just produce a clean, wrong paragraph.
A custom workflow exists to close exactly those gaps: it retrieves from one indexed, versioned policy set; it knows the asker's role and location and won't serve a rule that doesn't apply to them; it suppresses documents flagged stale instead of quoting them; it shows the citation so the human can verify; and it refuses-and-routes the consequential questions to the named HR, legal, finance, IT, or security owner rather than improvising. The NIST AI Risk Management Framework gives you the language for mapping that risk and accountability, and CISA's AI data-security guidance matters the moment policy content brushes up against security procedures or employee data. The test is simple: when the answer is wrong, can an owner trace why? In a chat workspace, usually no. In a built workflow, the log tells you.
Start with travel expenses, not terminations — and measure deflection
Pick the most boring, lowest-stakes policy domain you have and pilot there first. IT access requests and travel-and-expense rules are ideal: high question volume, mostly context-free, and a wrong answer costs an awkward correction, not a lawsuit. Prove the mechanics — citation, freshness, escalation — on the domain where mistakes are cheap. Do not let the demo be about HR leave law or anything legal-sensitive, no matter how impressive it looks.
Then watch the number that actually means something. Not how many questions it answered — how many it answered correctly enough that the employee didn't re-ask a human. Track that deflection rate, the share of answers carrying a real citation, the escalation rate on consequential questions, how often a stale document got flagged instead of quoted, and policy corrections logged after launch. Deloitte's State of AI in the Enterprise 2026 describes the broader shift from pilot theater to production value; for policy Q&A, that value is correct deflection and clean escalation, full stop.
Write the decision down in one paragraph: we kept travel-expense Q&A in ChatGPT Business because it's current and human-checked; we're building the workflow for HR and benefits because answers there depend on who's asking; we paused IT-security policy until the source docs get cleaned up. If you can't fill in that paragraph with evidence, you don't expand to the next domain — you fix the source set first. For the mechanics of choosing what to automate and setting escalation rules, see the policy automation guide and the internal knowledge assistant guide, and when you're ready to sequence the build, the AI roadmap ties it to outcomes.
