"Acme Corp" or "ACME Corporation"? Your CRM Has Both, and AI Won't Settle It
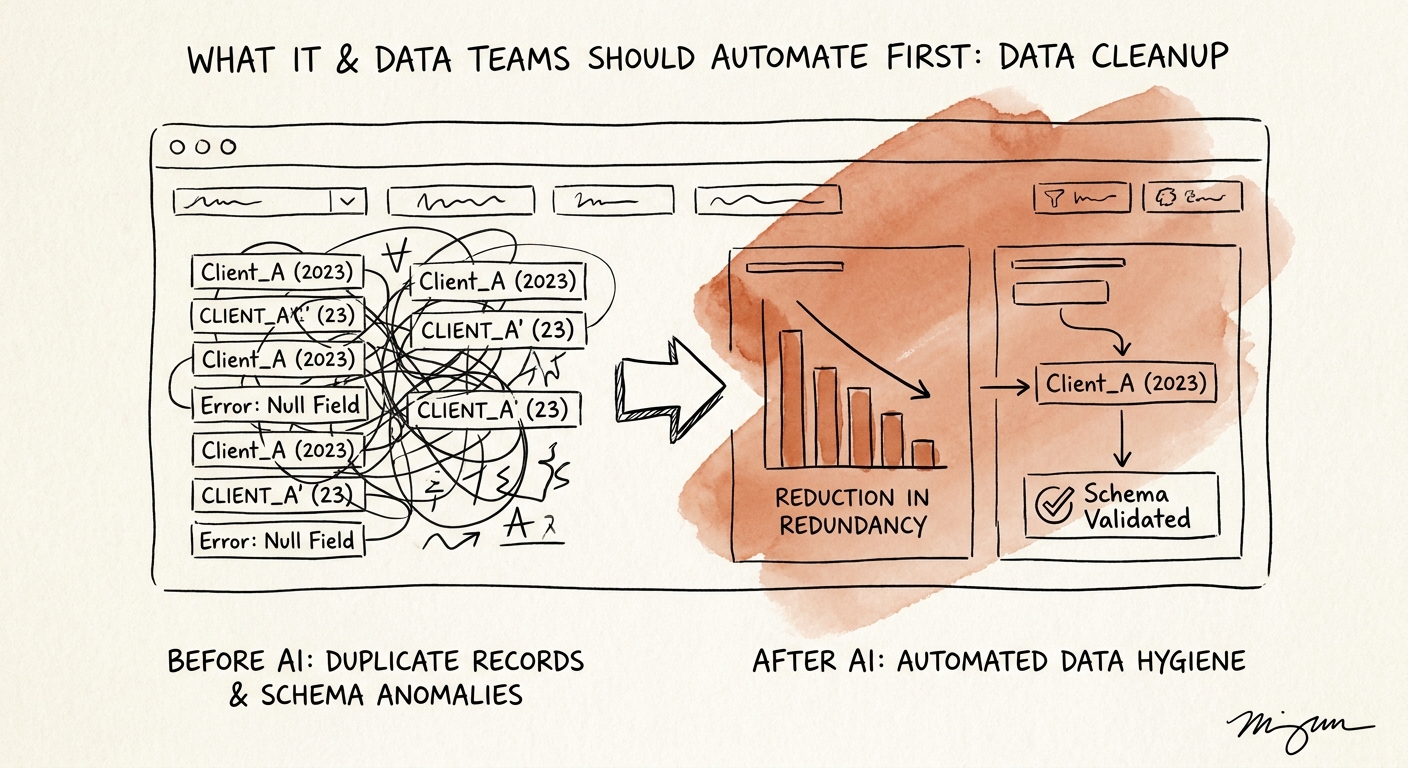
Here is the scene every IT lead at a growing tech-services firm knows. Sales has three records for the same account: "Acme Corp," "ACME Corporation," and "Acme Corp. (DO NOT USE — old)." Billing invoices against one. The CSM logs notes against another. The renewal forecast quietly double-counts. Someone says, "Can't AI just clean this up?" And on paper, yes — a model will happily find the duplicates in an afternoon.
The trap is that finding the duplicates was never the hard part. The hard part is deciding which of the three is the master record, and that is a business rule, not a string-similarity score. Does the billing system win because it touches money? Does the most recently modified record win? What happens when the "old, do not use" record is the only one with the correct tax ID? A model can rank candidates by confidence. It cannot tell you that finance's record is canonical for invoicing while sales' record is canonical for territory assignment — because nobody wrote that down.
This is exactly the gap the OECD SME AI adoption report and Deloitte State of AI in the Enterprise 2026 keep surfacing: the distance between "AI looks easy here" and "AI is safe to run in production" is almost never the model. It's the missing decision underneath the data. So pick one narrow field family for the first pilot — account duplicates, or vendor name normalization, or project-code cleanup — and resist doing all three. One family, one owner, one rule you can actually defend.
Make the AI Build a Case File, Not a Commit
The mistake most teams make is asking the model to fix records. Ask it to assemble evidence instead. For every duplicate it proposes to merge, the output should be a small case file: source system, the duplicate candidates, the proposed master record, the conflict rule it applied, why it's confident, the owner who must sign off, the sample of what the merged record would look like, and the exact path to undo it. No writeback. A reviewed queue.
That structure does something useful: it forces three honest outcomes instead of one optimistic one. Stop — when there's no named owner for that field family, the workflow halts, because there is no one to approve the merge. Fix — when the owner reviews a sample and the rule produced a wrong master, you correct the rule before touching anything live. Automate — only the narrow slice of cases that pass owner review on real samples graduates to a recurring job. Everything else stays in the queue as discovery, not failure.
The NIST AI Risk Management Framework earns its place here precisely because a bad merge doesn't stay contained. Collapse two vendor records and you can break a payment routing, orphan a tax document, or rewrite a customer's support history so the renewal team walks in blind. Track the metrics that catch this early: approved-sample accuracy, unresolved-conflict rate, rollback events, duplicate reduction, downstream report corrections, and how fast owners actually respond. If your owner response time is measured in weeks, you don't have a model problem — you have a stewardship problem, and shipping faster will only make it worse.
The Rejected Merges Are Worth More Than the Approved Ones
Here's the counterintuitive part. When the pilot creates an argument — sales insists their record is right, finance insists theirs is — that argument is the most valuable output of the whole exercise. It means you've found a place where two systems define the same entity differently and nobody noticed until a model tried to reconcile them. Inspect rejected candidates as carefully as approved ones. They map, almost perfectly, to the spots where your business has no master-data rule, or where a value that "looks wrong" is actually load-bearing for some downstream report.
Because cleanup touches customer, vendor, financial, and support records spread across systems, set the guardrails before the first write, not after. The CISA AI data-security best practices should define the access boundary, retention window, logging, and rollback process while you're still in candidate-generation mode — the safest release a data team can ship. Then make the scale decision on writeback readiness, not on how many duplicates the model can find: count what was approved, corrected, rejected, and rolled back, and only let the rule-governed slice run on its own.
If you want to sequence this against everything else competing for AI attention, the AI Opportunity Score helps you decide whether cleanup should come before other use cases, and the AI ROI Calculator puts a number on the reporting and routing hours you recover when records stop lying to you. Monday's move: name one owner for one field family, run the model in candidate-only mode against a 50-record sample, and watch how many "obvious" merges that owner refuses. That refusal count is your real readiness signal. When it drops near zero on a family, that family is ready to automate. Everything still in dispute is a backlog for the business to settle — not a job for AI to silently decide.
