The first 90 seconds of every intake is the part worth automating
Picture the operations coordinator at a 60-person B2B services firm on a Tuesday morning. The shared inbox has 31 new items: a vendor sent a W-9 with no banking attachment, a customer uploaded an onboarding form and called the PDF "scan_final_v2," someone in sales forwarded a signed SOW that needs to reach finance, and three submissions are missing the one field that stalls everything downstream. Before any real work happens, that person spends the morning sorting, renaming, routing, and emailing people to ask for the page they forgot. That triage layer — not the decisions underneath it — is where AI earns its keep first.
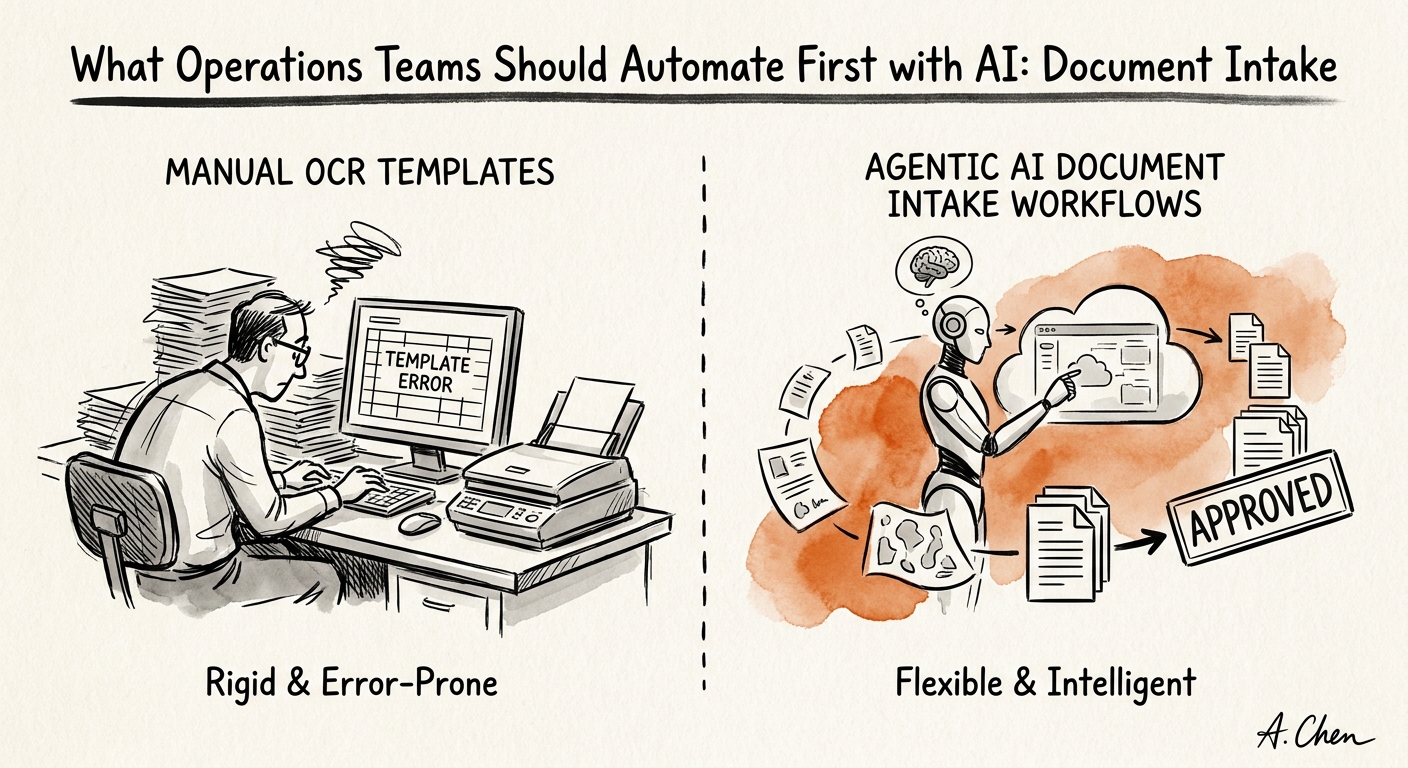
This is exactly the kind of repeated administrative work the U.S. Census Bureau AI business adoption analysis and the OECD SME AI adoption report identify as the realistic on-ramp for smaller firms: narrow, high-volume, reviewable. The win is not "the AI reads our documents." The win is that the coordinator stops doing the part a machine does better — classify the document, check whether the required fields are actually present, propose a route — and keeps the part that needs judgment: deciding whether it's complete enough to move.
So pick one lane, not "all our documents." For a B2B services shop that usually means vendor onboarding packets or customer intake forms — pick whichever one generates the most "you forgot something, please resend" emails. That volume is your signal. The lane that triggers the most chasing is the lane where AI removes the most drudgery.
Completeness is the gate, not classification
Here is the trap most teams fall into. They measure the pilot on whether the AI labeled the document correctly — "yes, it knew this was an MSA" — and declare victory. But a correctly labeled document that's missing the effective date, the signatory, or the rate schedule isn't ready to route. It just looks ready. The model's confidence and the document's completeness are two different things, and conflating them is how a half-finished vendor packet sails into finance and stalls a payment for a week.
So make the deliverable a packet, not a label. For every document, the intake should surface: source, document type, the required fields it found, the required fields it didn't, a privacy category, a proposed destination queue, and the SLA clock. That last column matters — it tells you whether something is aging in an exception state versus moving. With that packet, your coordinator can answer in five seconds the question that used to take five minutes: is this ready, or does someone need to go get the missing piece?
Because classification can drift and missing fields create real downstream risk, the NIST AI Risk Management Framework belongs in the pilot from day one — it gives you the language for tracking error types instead of just throughput. Watch first-pass classification accuracy, missing-field detection rate, how often a human reroutes the AI's choice, and how long items sit in the exception queue. And treat a recurring missing field as a process finding, not a model failure: if the same blank keeps appearing, the fix is a required field on the submission form, not a smarter classifier. The intake pilot should quietly hand you a punch list of where your forms and instructions are broken.
Sensitive documents get a manual lane until the rules are boring
Document intake is also where a B2B services firm's most sensitive material flows through one chokepoint — customer records, supplier banking details, signed contracts, employee forms, invoices. Before the workflow ever touches a live document store, set the access, retention, logging, and exclusion rules using the CISA AI data-security best practices as the checklist. The practical move: anything tagged sensitive — HR files, anything with bank or SSN-grade data — stays on a manual route until the basic version has run clean long enough to be boring. Boring is the standard you're aiming for.
When you decide whether to add a second lane, do not look at speed alone. Put intake speed and correction quality side by side. If the AI routes faster but your reroute and missing-field-catch numbers are climbing, you don't have a scaling problem — you have a field-rules problem, and adding another document type will multiply it. Narrow the set, tighten the rules, then expand. A healthy roadmap grows from one trusted lane to the next, with the completeness packet and privacy controls visible the whole way.
Monday, do three concrete things. Name the single intake lane that generates the most chasing. Write down the five-or-so required fields that must be present before that document is allowed to move. And decide, in advance, which document types are sensitive enough to skip automation entirely for now. If you want to weigh document intake against quote turnaround, invoice routing, or meeting summaries before committing, run the AI Opportunity Score — it forces the comparison your gut would otherwise skip. Get the first lane to where the exception queue is short and the packets are trustworthy, and you'll have something better than a faster inbox: a clear view of which documents are actually ready to move.
