The week before the auditor calls, three people stop shipping
Picture a 90-person SaaS company heading into its second SOC 2 Type II audit. Six weeks out, the security lead, an engineer, and someone from people-ops quietly disappear into evidence-gathering mode. They export user lists from Okta, screenshot S3 bucket policies, dig termination dates out of the HRIS, pull approval threads from Jira, and chase a vendor's SOC report that expired in March. By the time the audit firm sends its request list, half the artifacts are stale and nobody can remember which Slack thread approved the one production access exception from Q3.
This is the exact shape of work AI is good at — and the exact shape of work where AI does the most damage when it's pointed the wrong way. Compliance evidence is repetitive, lives in known systems, and gets reviewed by a human who decides if it's real. That makes it a strong automation target. But the failure mode is specific: a model optimized to produce a clean evidence package will happily produce a clean evidence package for a control that's broken.
So draw the line up front. The AI does not decide whether you pass. It assembles the package, points to where every artifact came from, and flags what's missing — then a control owner approves it or fixes the control. Frameworks like the AICPA SOC suite and ISO/IEC 27001 exist precisely because evidence has to be verifiable, not just present. An assistant that makes weak controls look finished isn't saving you work — it's setting up a finding you'll see in the report.
Build it around your control matrix, not around "documents"
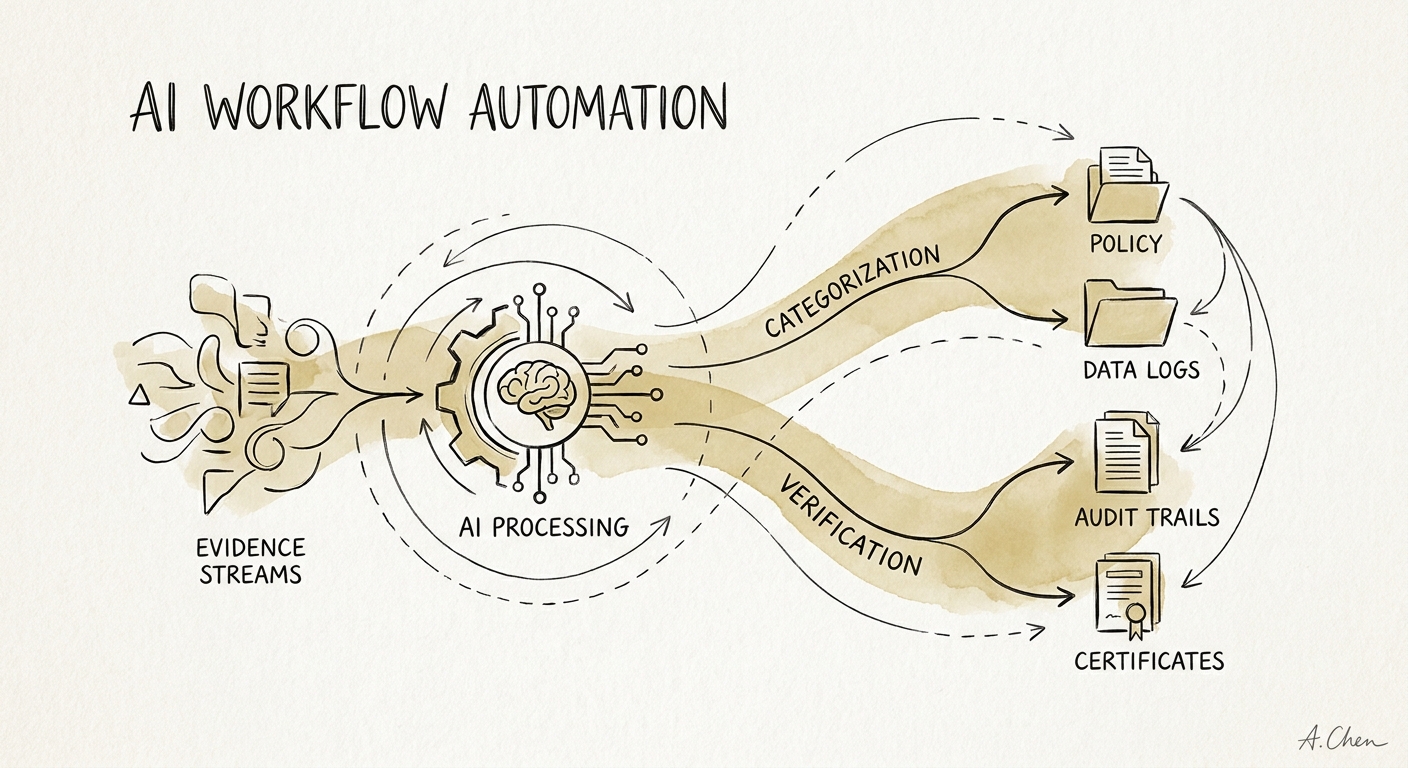
The mistake most teams make is treating this as a document-retrieval problem — "go find all the screenshots." It isn't. It's a control problem. Start from your control matrix and give every control five attributes: the owner, the source system, the evidence type, the review frequency, and the escalation path. An access-review control, for instance, needs the identity-provider export, the termination dates from the HRIS, the approval records, and notes on every exception. The workflow's job is to pull those four artifacts and show, for each one, exactly which system and which timestamp it came from.
Then split the pipeline into three states and don't blur them: routine evidence, exceptions, and owner approval. Routine evidence — the user list pulled clean, the policy acknowledgment everyone signed — goes into a review queue with source links attached. Exceptions get routed to the accountable owner the moment a record is missing, stale, contradicts another system, or sits outside the approved policy boundary. That terminated contractor who still shows active in one console? That's an exception with a name on it, surfaced in week one, not a surprise the auditor finds in your sample.
Wire it read-only. A compliance evidence assistant should never be able to change a production config, edit a source record, approve an access request, or rewrite policy text. The blast radius of a hallucination has to be zero — the worst it can do is mislabel an artifact, and a human catches that at review. Map permissions, audit trails, and review standards using the AI assistant governance framework before you connect it to Okta or your cloud accounts. The NIST Cybersecurity Framework and the Cloud Security Alliance Cloud Controls Matrix both give you a vocabulary for which systems are sensitive enough to warrant that discipline.
What to measure: corrections caught early, not artifacts generated
Resist the vanity metric. "1,400 evidence items collected" tells you nothing — a script can generate noise. The numbers that matter are the ones tied to a cleaner audit: missing artifacts flagged before the request list arrives, source references that verify on inspection, exceptions routed to a named owner, review cycle time, repeat auditor requests (these should drop year over year), and corrections made internally before external review. Track the failure cases too — false positives and incomplete summaries — because that's how the workflow earns more autonomy over time instead of less.
Scope the first run narrowly. Pick one control family — access reviews is the usual best starting point because the evidence is structured and the exceptions are obvious. Month one: map the requirements and owners. Month two: run it in draft-and-review mode, where every package lands in front of a human before it counts. Month three: let the genuinely routine, recurring evidence flow on a controlled cadence while exceptions stay human-led. Ninety days is enough to know whether it's working, and short enough that you haven't bet the audit on it.
Sequence that pilot with the 90-day AI implementation plan, and before you commit, run evidence collection through the AI Opportunity Score to see how it stacks up against your other automation candidates — it may not be your highest-leverage first move. The bar for shipping is simple: if the workflow can't preserve source references and keep a human accountable for sign-off, it isn't ready. The payoff, done right, is that your team sees control status in week one of the cycle instead of week ten — and stops losing three people to screenshot duty every audit. Responsible-AI work from groups like PwC keeps landing on the same point: governed assistance beats autonomous output anywhere a human is still on the hook for the answer.
