The pile a new client dumps on you
A new client signs. Within 48 hours your delivery team gets a shared folder with 30 files: a signed engagement letter, two prior-year returns, a cap table screenshot, three bank statements as photos taken at an angle, a "misc" PDF that turns out to be a lease, and a spreadsheet someone exported wrong. A senior associate spends most of a morning sorting it, renaming it, and emailing the client back about the four things that are missing. That morning repeats for every onboarding, all year.
That sorting-and-chasing morning is the right place to point document intake AI — and the wrong place to start is "feed it everything." The temptation is to build one model that ingests any client upload. Resist it. The RSM middle-market AI survey, the San Francisco Fed analysis of AI and small businesses, and the OECD report on AI adoption by SMEs all point the same direction: adoption sticks when you pick a narrow slice where the data quality, the owner, and the payoff are obvious.
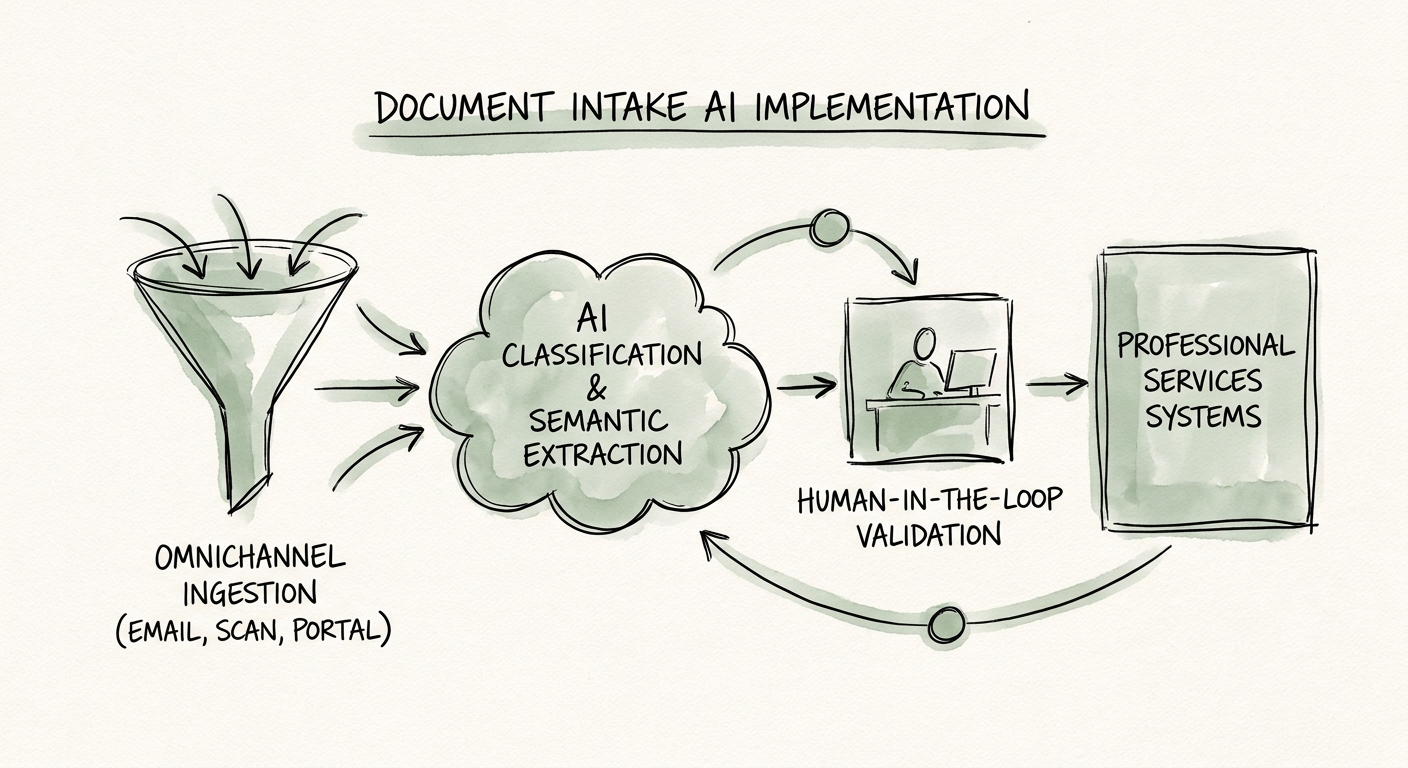
So pick one document family. Say your firm's onboarding always requires engagement letters and prior-year tax returns. Those have known required fields — signature date, entity name, EIN, tax year, signing partner — and they arrive in a handful of recognizable formats. Teach the workflow to classify each upload, pull those fields, flag what's missing, route anything sensitive, and hand your reviewer a packet instead of a folder. Prove extraction quality on that one family before you go near the "misc" PDFs. Mapping the manual work first tells you which family is worth automating.
Every field has to point back to a page
Here's what kills trust in an intake bot fast: it confidently reports an EIN that's actually the client's prior accountant's EIN, lifted from a stray letterhead. Once a reviewer catches one of those, they stop trusting the whole packet and go back to reading every document by hand — and you've spent budget to make work slower. So the rule for professional services intake is simple and non-negotiable: every extracted field must link back to the exact document and page it came from, with a confidence score the reviewer can see.
That's not just hygiene; for a services firm it's defensible documentation. If a field reads "Tax Year: 2024" the reviewer should be able to click it and land on the source page where the model found it. When two documents disagree — the engagement letter names one entity, the return names another — the workflow should surface the conflict, not silently pick one. The NIST AI Risk Management Framework gives you the language for mapping who's accountable for that review decision, and the CISA AI Data Security Best Practices cover the part most firms underbuild: client financials and PII need access controls, retention rules, and monitoring on the outputs, not just the inputs.
Concretely, before launch, nail down: the document types in scope, who can see what, how long extracted data is retained, the confidence threshold below which a field auto-routes to human review, the reviewer queue itself, and an escalation path for incomplete or contradictory uploads. Run the use-case scoring model on the family you chose — if the source documents are too messy or the review burden too heavy, that's a signal to pick a cleaner family first.
The number that proves it worked
The win isn't "we have AI in intake." The win is that the senior associate's morning shrinks to twenty minutes of reviewing flagged exceptions, and the client gets the "you still owe us X and Y" email on day one instead of day four. Deloitte's State of AI in the Enterprise 2026 makes the point that real value shows up when the work pattern actually changes — not when a tool gets switched on. For document intake, that change is concrete: from manual sorting and missing-field chasing to a reviewable packet that's mostly triaged before a human opens it.
Measure it that way. Track intake cycle time (signed engagement to delivery-ready packet), missing-information rate caught at intake versus discovered weeks later, how often reviewers correct an extracted field, and how often the workflow prevents the avoidable rework of re-requesting a document you already had. If review corrections stay high after a few weeks, your extraction or your document family is wrong — fix that before scaling.
Stay on one document family and one delivery process until those numbers hold. Then add the next family. A firm that tries to automate all client uploads on day one usually ends up trusting none of it; a firm that nails engagement-letter-plus-returns earns the right to expand. Use the 90-day implementation plan to sequence source mapping, extraction testing, reviewer queues, and the measurement above — and when you're ready to scope the full rollout, the AI transformation blueprint turns this into a roadmap.
