
The first AI project that lands in your lap, not on your roadmap
Here's how it usually starts for a data or IT team. Sales saw an AI demo at a conference. It pulled a company's funding round, latest product launch, and three named contacts into a tidy one-page brief in eight seconds. Now someone in a leadership channel is asking why your team hasn't shipped that yet. The honest answer — that the demo ran against a clean fictional company and yours runs against a CRM where 40% of the "account owner" fields are stale and "industry" is a free-text mess — does not fit in a Slack reply.
So before you treat account research as a writing problem, treat it as a source-governance problem you happen to own. The RSM middle-market AI survey, the San Francisco Fed analysis of AI and small businesses, and the OECD report on AI adoption by small and medium-sized enterprises all point the same direction: the adoption work that sticks starts with clear ownership and usable data, not with the model. For your team specifically, account research is a good first bet because it touches systems you already control — the CRM, the support log, the product-usage tables — and because the failure mode is loud enough that you'll know fast if it's wrong.
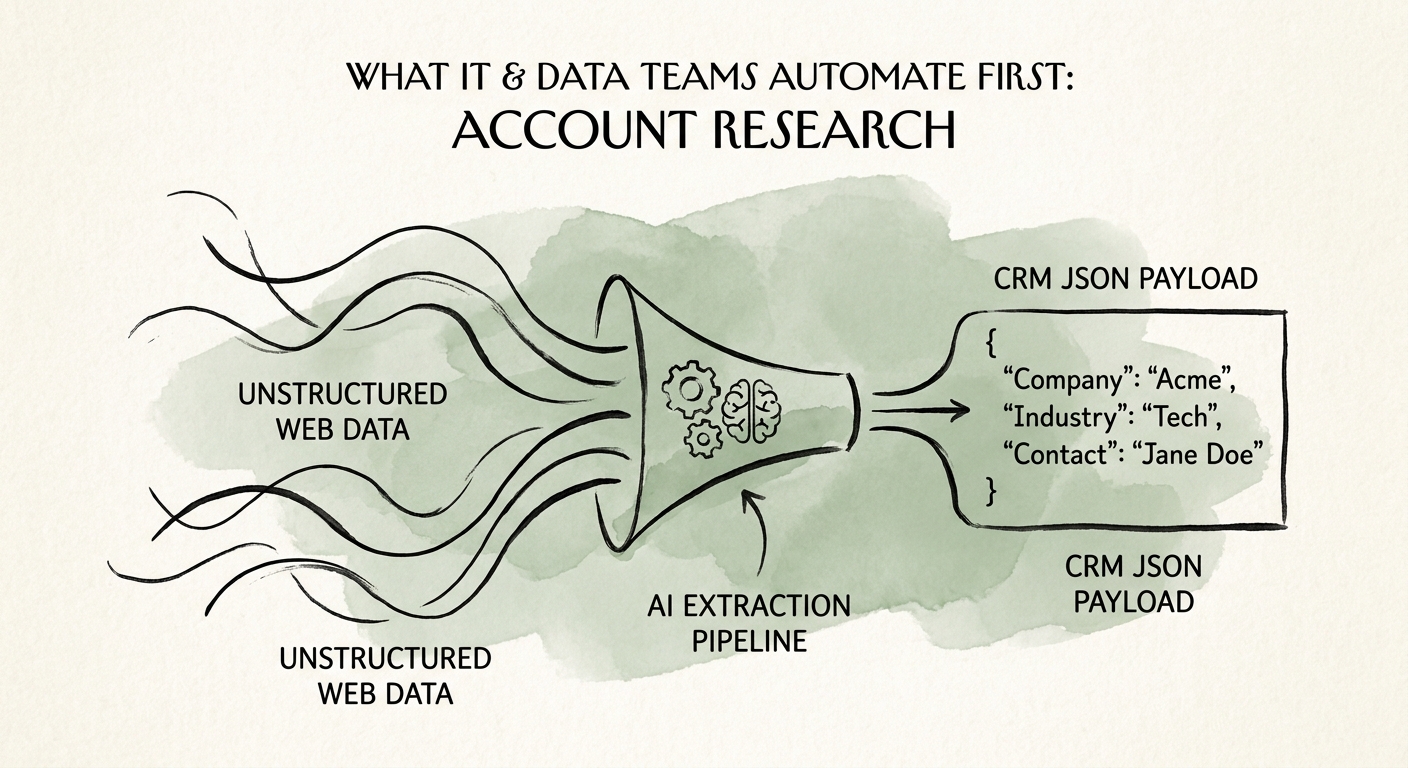
The dream brief blends public company context, CRM history, product usage, support tickets, renewal dates, and CS notes. But a model summarizing six sources can only be as good as the worst one. Before you pipe anything in, run account research through the workflow automation screen and be honest about whether the repeat volume and source quality are actually there.
The data classification job nobody asks for until it's too late
This is the part where being the data team is an advantage, because you already know that "an account" is not one thing. It's a public layer (the company's website, news, filings), a first-party operational layer (CRM fields, deal stage, owner), and a sensitive layer (support transcripts, billing disputes, churn-risk notes, anything a customer said in confidence). A sales-built prototype tends to flatten all three into one prompt. That's how a draft outreach email ends up quoting a customer's open escalation ticket back at them.
The NIST AI Risk Management Framework is useful here precisely because it forces you to map context and assign accountable controls per source — which is the classification exercise you'd want to run anyway. Pair it with CISA's guidance on securing data used to train and operate AI systems for the access-control, monitoring, and review specifics. Practically: decide what the model is allowed to retrieve and surface unrestricted (public web, basic firmographics), what it can read but only summarize inside approved systems (CRM history), and what is off-limits without a named human checking the output first (support and churn-risk records).
Write those three buckets down before you write a single prompt. Then score the use case against them with the AI use-case scoring model — source readiness, access complexity, customer-data exposure, and adoption value — so the "why not yet" conversation with leadership is a rubric, not your gut feeling against their FOMO.
The metric isn't "we shipped AI" — it's "the next call got easier"
The trap your team can fall into is measuring activity: briefs generated, tokens consumed, a dashboard that says the thing is running. Deloitte's State of AI in the Enterprise 2026 keeps hammering that the gap between piloting and value is real, and account research is where you can prove value cheaply. The signal that matters is whether the next human action — the seller's call, the CS check-in — got more specific, more timely, and more grounded in something verifiable.
So track things you can defend: research cycle time, CRM field completion rate after briefs are adopted, how often a manager has to correct a generated brief, brief reuse across a team, and whether reps stop reconstructing account context from scattered memory and old email threads. The manager correction rate is the one to watch first — if it climbs instead of falling over a few weeks, your source layer is leaking, not your model.
Stage it so the blast radius stays small. Start with internal briefs and CRM hygiene — outputs that only your own people see — before you let anything generate external messages to a customer. Use the 90-day AI implementation plan to sequence source cleanup, permission testing, a manual manager review window, and a limited rollout to one team. Monday, do the cheapest high-value step: pull a sample of 20 real accounts, draft what the brief would say, and have a sales manager mark every line as right, wrong, or "where did that come from?" That one afternoon tells you more about your data than any vendor demo will.
