
The practical answer
- Short answer
- Acquirers discount AI IP up to 60% when data provenance is murky. How to prove lineage on your models and training sets before a PE deal team arrives.
- Best fit
- Industry: Software & Technology. Function: M&A Due Diligence
- Operating path
- Exit Readiness → Operational Excellence → Transaction Advisory Services
- Key metric
- 40% of AI M&A deals face valuation haircuts due to data provenance issues.
The afternoon I wiped $85M off a data room
On a recent sell-side engagement for a Series C AI platform, the founder walked into the second buyer meeting convinced his "proprietary model" was the crown jewel. Three days later I was rebuilding the data room from scratch, because the buyer's counsel had asked one question the team couldn't answer: where did the fine-tuning corpus come from? The honest answer was web-scraped content with no license trail. We stripped a combined $85 million in projected enterprise value out of the model, and the intangible-asset line went to zero overnight. The algorithm wasn't the problem. The provenance was.
That is the trap baked into AI IP valuation right now, and it is specific to companies that built on top of someone else's foundation model. What a founder calls a differentiated model is, more often than not, a fine-tuning layer and some prompt orchestration wrapped around a commercial LLM, fed by a database nobody governed. Acquirers know this. In 2026 they are discounting that "proprietary" IP by as much as 60% during technical diligence, and they start from the assumption that the moat is thinner than the CIM claims.
The blind-multiple era is over. Buyers are no longer paying 15x to 20x revenue because there's a ".ai" in the domain. Gartner's 2026 AI Asset Valuation Guide shows 75% of generative AI application companies watching their valuations compress back to ordinary SaaS metrics, roughly 6x to 8x EBITDA, once the quality-of-earnings and technical diligence phases get going. The premium doesn't evaporate because the technology is bad. It evaporates because the part the founder bragged about, the model itself, is the part that's becoming a commodity.
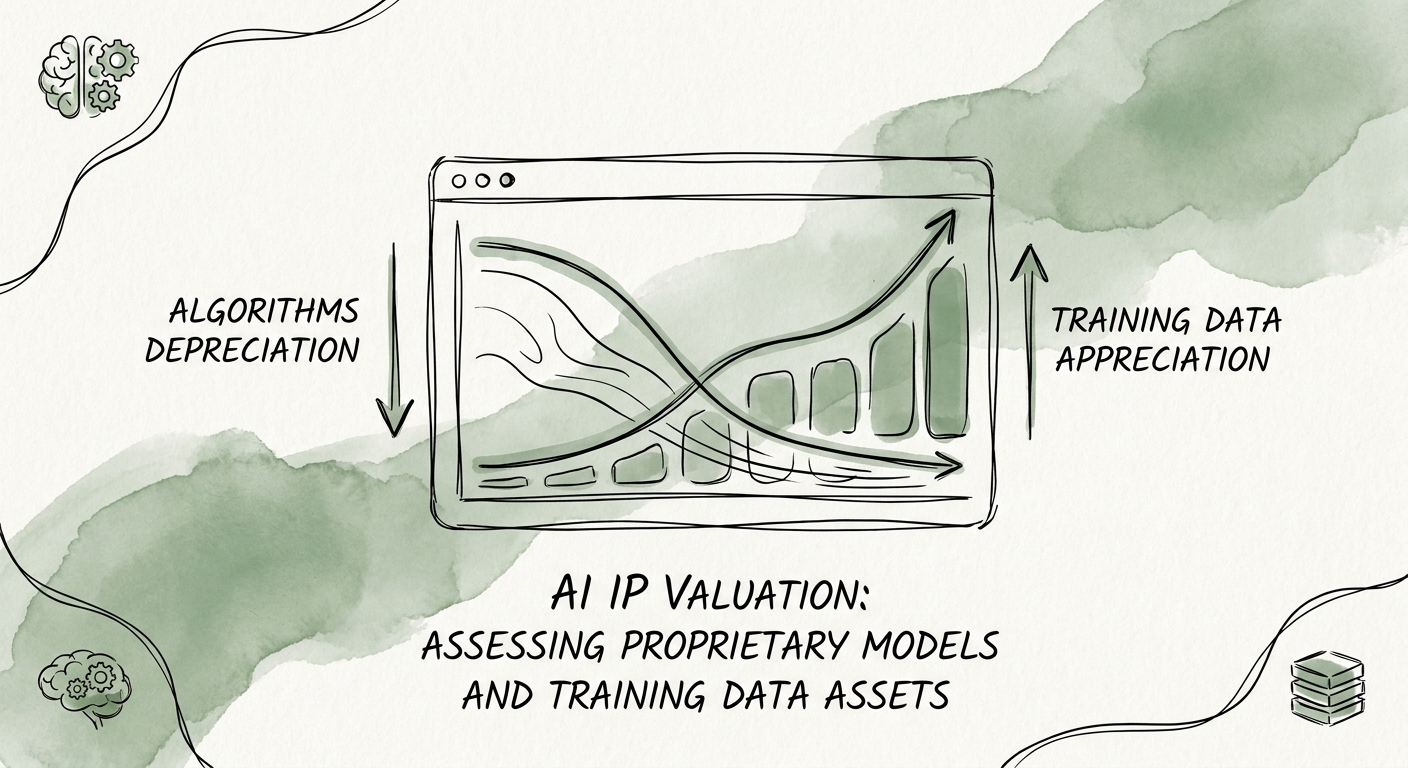
The asset that actually holds is narrower and less glamorous: a domain-specific training set you can prove you own, free and clear, plus the workflow integration that keeps capturing human feedback after the deal closes. Everything else is rented. If you want the structuring logic behind that distinction, our playbook on how to value proprietary data assets in tech acquisitions walks through the segmentation.
The algorithm depreciates on a 14-month clock. The thing that actually survives diligence is a training set you can prove you own, line by line.
Provenance is the new Quality of Earnings
In a traditional SaaS deal, the sponsor's team obsesses over the QoE report: cohort retention, revenue recognition, one-time adjustments. In an AI deal, a parallel report now sits next to it, and the technical diligence team treats it with the same seriousness. Call it Quality of Data. The test is brutal and binary: if you cannot show the provenance, lineage, and licensing rights for the data that trained or fine-tuned your model, the buyer assigns that IP a value of zero. Not a discount. Zero. There is no partial credit for "we're pretty sure it's clean."
This isn't a lawyer's hypothetical. PwC's 2026 Tech Due Diligence Benchmark found that 40% of AI-focused M&A deals take a valuation haircut specifically over data provenance and model-drift issues surfaced in technical diligence. Institutional buyers are not scared of your code; they're scared of inheriting a copyright infringement suit, or discovering the foundational model is contaminated by training sets they'd have to litigate over for years.
The flip side is where the money is. McKinsey's 2025 M&A Data Asset Analysis puts the average multiple expansion at 2.5x for software companies that own legally ring-fenced, proprietary datasets versus peers leaning on synthetic or open-source data. The reason a competitor can't close that gap by renting more GPUs: they don't have your data, and they can't manufacture the years of real usage that produced it.
Here's what most founders underestimate. Contamination is not a patch. If GPL-licensed code or copyrighted content leaked into the training pipeline, the remediation isn't a config change. It frequently means retiring the model and retraining from clean inputs, which can take quarters and reset whatever performance edge you were selling. That is why the audit has to happen long before the teaser goes out. Run a full intellectual property audit checklist for AI/ML acquisitions at least twelve months ahead of going to market, so you have time to fix what you find.
And understand what you're actually defending. MIT Sloan's 2025 Generative AI Asset Depreciation Study pegs the half-life of a purely algorithmic edge at 14 months. If your exit story is "we have the best algorithm," the asset is decaying faster than your deal timeline. The data underneath it is what compounds; the math on top of it is on a depreciation clock.
Three folders that decide your multiple
When the deal team opens your data room, an architecture diagram and a list of API endpoints won't carry you. Treat your AI assets with the same evidentiary rigor you'd apply to a financial liability, and build the room around three things a buyer can verify.
First, the cost-to-serve. "AI" does not mean "high margin," and sophisticated acquirers assume the opposite until you prove otherwise. Show a dashboard where inference compute scales sub-linearly with revenue. If your gross margin is stuck around 60% because GPU spend eats the difference, you are not being valued as a software company; you are being valued as a compute reseller passing cloud bills to customers. That distinction alone can move you a full turn on the multiple.
Second, the lock-in. EY's 2026 Intellectual Property Valuation Index attributes 80% of perceived AI enterprise value to workflow integration, not algorithmic superiority. The platforms commanding 14x multiples are the ones embedded in the user's daily critical path, quietly accumulating proprietary telemetry that retrains the model without anyone lifting a finger. Document where in the customer's workflow you live and what unique signal you collect there, because that feedback loop is the part a competitor genuinely cannot copy.
Third, the boundary map. Be aggressively honest about what's commodity and what's yours. Draw the exact line between the open-source foundation model, your proprietary fine-tuning layer, and your workflow logic. Buyers reward this transparency and punish the opposite, and resist the urge to over-engineer the stack just to look sophisticated. Say a 60-person vertical-SaaS company bolts on three extra data tools to seem advanced; all it does is widen the surface a technical auditor has to interrogate. We dismantle that pattern in our look at the modern data stack trap and Snowflake technical liabilities.
Valuing AI IP in 2026 comes down to separating the marketing from the math. Start one task on Monday: pull the manifest of every dataset that touched your model and write down, per source, who owns it and under what license. The rows you can't fill are exactly where the buyer will find the discount first.







