
The practical answer
- Short answer
- AI targets don't fail in the codebase—they fail in the retraining pipeline. A buyer's field guide to auditing MLOps maturity, model drift, and registry gaps.
- Best fit
- Industry: B2B Software & AI. Function: Technology Due Diligence
- Operating path
- Technical Debt → Turnaround & Restructuring → Transaction Advisory Services
- Key metric
- 64% Percentage of predictive models that suffer significant performance degradation within 90 days if unmonitored.
The model passed every test on Monday and started losing money on Thursday
Here is the scenario that breaks a clean diligence report. A target's pricing model scores 94% on its holdout set. The code coverage is excellent. The GitHub repo is tidy. Your tech diligence team signs off. Then, six weeks after close, the model starts quoting prices that are subtly, systematically wrong—because the customer mix shifted, the input data drifted, and nothing in the stack was watching. Nobody touched a line of code. The asset degraded on its own.
That is the part standard underwriting misses. Software is deterministic: the same input gives the same output until someone changes the code. A machine learning model is probabilistic—it is only ever as good as the statistical shape of the data flowing into it. When the data moves, the model moves with it, silently. So when you run a legacy code-quality scan on an AI target and see high test coverage, you have learned almost nothing about the actual risk, because the debt does not live in the repository. It lives in the unversioned training sets, the manual deploy scripts a single engineer runs by hand, and the total absence of automated retraining. MIT Sloan's 2024 research on ML technical debt found that without mature pipelines, data science teams burn up to 70% of their capacity nursing degraded models and babysitting infrastructure—not building the IP you priced into the multiple.
The cost asymmetry is what should worry a buyer most. McKinsey's 2025 Global Survey on AI reports that first-year maintenance on ungoverned predictive models can run up to 400% of the original development budget. Read that again as an operating partner: the thing the seller built for a dollar can cost you four dollars a year to keep alive—and that line item is nowhere in the CIM. Picture a target boasting "45 models in production." Sounds like a moat. Now ask the two questions that actually price it: which version of each model is live right now, and what data was it trained on? If the honest answer is "let me check the spreadsheet," you have not found a moat. You have found 45 separate liabilities, each one drifting on its own schedule. For the broader picture, our 10 Red Flags in Technology Due Diligence That Kill Deals sets the table—but AI demands its own investigative lens, and the rest of this is that lens.
A model registry is the AI equivalent of a general ledger. When a target can't tell you which model version is in production or what data trained it, you're not buying intelligence—you're buying a black box with a key-person risk attached.
The "Hero Data Scientist" is a key-person risk wearing a hoodie
Walk into most early-stage AI companies and you will find the same person: the one engineer who can actually retrain the models. They do it from a local notebook, by hand, with a process that lives entirely in their head. The models work. The demos are impressive. And the entire enterprise value of that algorithm walks out the door the day that person gives notice. There is no reproducible pipeline, no record of how the production model was built, no way for anyone else to rebuild it. That is not a quirky startup culture detail. In a hold-period model, it is the most concentrated key-person dependency you will underwrite—and it does not show up on an org chart.
Drift is what turns that dependency into a P&L event. Gartner's 2025 AI engineering maturity benchmark found that 64% of predictive models suffer significant performance degradation within 90 days of deployment if left unmonitored. Now connect that to the business: when a pricing model drifts, it misprices revenue. When a risk-scoring model drifts, you quietly absorb bad debt you did not underwrite. When a churn model drifts, your retention spend gets aimed at the wrong accounts. The damage is continuous and invisible, because the model never throws an error—it just gets gradually, expensively wrong.
This is also why integration budgets blow up. EY's 2025 GenAI investment framework shows post-acquisition AI integration running 45% over initial estimates on average, driven almost entirely by the target's lack of operational maturity. Buyers think they are purchasing the algorithm's intelligence. What they are actually inheriting is the obligation to build the factory that keeps that intelligence from rotting—monitoring, versioning, automated retraining—and that factory was never on the seller's books. So price it before you sign. Our Technical Debt Quantification Framework: From Assessment to Dollar Value walks the translation from gap to CapEx, but here is a concrete anchor you can use in the room: if the target has no automated drift detection, put a remediation line of roughly half a million dollars on the board immediately and make the seller argue it down with evidence, not assurances.
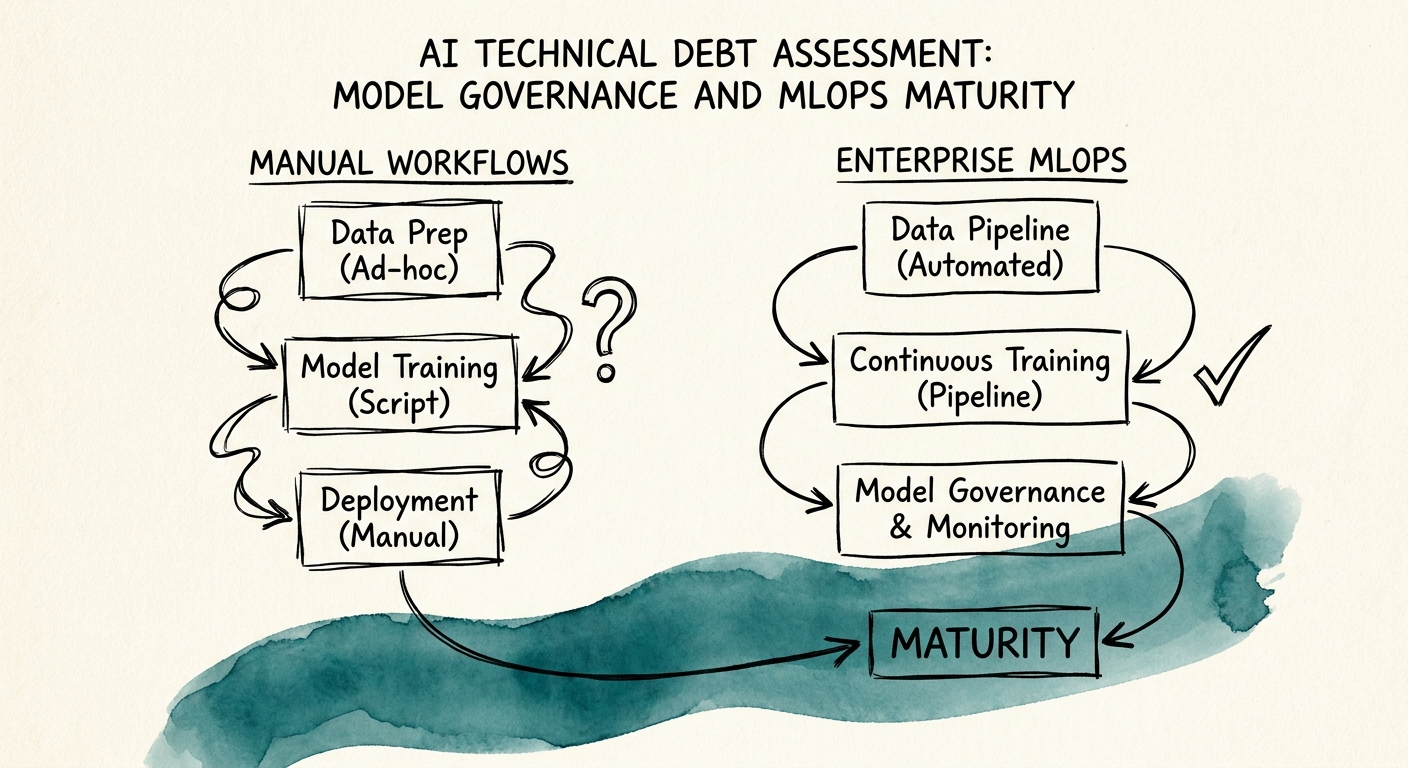
The four questions that separate an AI asset from a science experiment
Audit the MLOps pipeline the way you audit GAAP financials—because a model registry is the AI equivalent of a general ledger. It is the system of record that tells you exactly which model version is in production, the specific data snapshot it was trained on, and the hyperparameters used to tune it. Demand to see it. If it does not exist, the target cannot answer the most basic governance question—"what is running and why"—and you are buying blind. Then walk the rest of the rig with these checks, each a yes/no you can put in the report. Continuous training: does a retraining pipeline fire automatically when performance drops below a threshold, or does someone do it by hand when a customer complains? Feature stores: are the features used in training guaranteed to match the features served at inference, or is there a quiet skew that corrupts predictions in production? Shadow deployments: can they run a challenger model alongside the live champion to compare outputs before routing real traffic, or does every model change ship straight to customers on a prayer? A "no" on any of these is not a roadmap item. It is a discount to the ARR multiple, because that revenue is sitting on a foundation that erodes without anyone watching.
The exit math makes this urgent rather than academic. PwC's 2026 AI trust and governance survey reports that 82% of enterprise acquirers now demand a formal third-party model governance audit before signing an LOI on an AI-native business. So the immature pipeline you tolerate today becomes the diligence wall that strands your exit in three years. If your models are unexplainable, undocumented, or non-compliant with frameworks like the EU AI Act, the next buyer does not negotiate—they walk, or they re-price you down to the cost of rebuilding the whole stack themselves.
So treat the absence of MLOps maturity as a valuation defect to be priced at signing, not a fix-it-later operational note. Build the scorecard before you walk into management presentations: registry, continuous training, feature store, shadow deployment, drift monitoring. Score each one. Convert every "no" into a dollar figure and either fund it in the deal model or push it into the purchase price. The IP audit runs in parallel—our Intellectual Property Audit Checklist for AI/ML Acquisitions: The "Poisoned Model" Risk covers the legal and provenance traps that sit underneath the models—but the operational read is what protects your margin. Price the debt, fund the factory, and never pay turnkey money for an experiment.







